基于单目视觉的同时定位与地图构建方法综述
摘要:
增强现实是一种在现实场景中无缝地融入虚拟物体或信息的技术, 能够比传统的文字、图像和视频等方式
更高效、直观地呈现信息,有着非常广泛的应用. 同时定位与地图构建作为增强现实的关键基础技术, 可以用来在未
知环境中定位自身方位并同时构建环境三维地图, 从而保证叠加的虚拟物体与现实场景在几何上的一致性. 文中首
先简述基于视觉的同时定位与地图构建的基本原理; 然后介绍几个代表性的基于单目视觉的同时定位与地图构建方
法并做深入分析和比较; 最后讨论近年来研究热点和发展趋势, 并做总结和展望.
增强现实需要实时定位设备在环境中的方位. 定位方案虽然已经有很多种, 但多数方案要么在实际应用中存在诸多局限, 要么代价太高难以普及. 比如, GPS 无法在室内及遮挡严重的室外环境中使用, 且定位精度较低; 高精度的惯导系统成本太高且难以民用; 基于无线信号的定位方案需要事先布置使用场景等. 基于视觉的同时定位与地图构建技术(visual simultaneous localization and mapping, V-SLAM)以 其 硬 件 成 本 低 廉 (一个普通摄像头即可)、小场景范围内精度较高、无需预先布置场景等优势, 成为目前一个较常采用的定位方案. 尤其在增强现实应用中, 由于虚拟物体的叠加目标通 常为图像/视频, 因此基于图像/视频等视觉信息的 V-SLAM 方案, 对于确保虚实融合结果在几何上保持一致有着天然的优势.
VSLAM原理


2 代表性单目SLAM方法
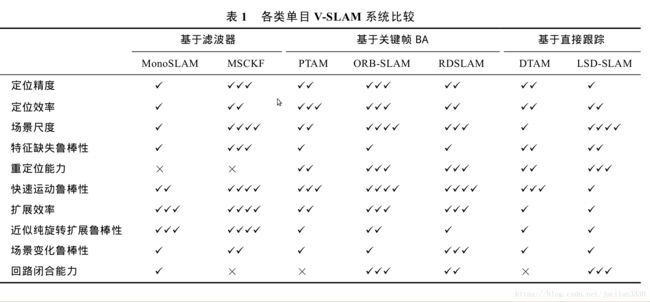
a)基于滤波器 filter-based
MonoSLAM
MonoSLAM 是由 Davison 等发明的第一个成功基于单目摄像头的纯视觉 SLAM 系统. MonoSLAM的状态 x t 由 t 时刻的相机运动参数 C t 和所有三维点位置 X 1 ... X n 构成, 每一时刻的相机方位均带有一个概率偏差(如图 2a 所示); 同样, 每个三维点位置也带有一个概率偏差, 可以用一个三维椭球表示, 椭球中心为估计值, 椭球体积表明不确定程度(如图 2b 所示); 不同场景点之间, 以及场景点和C t 之间均有概率关联. 在此概率模型下, 场景点投影至图像的形状为一个投影概率椭圆(如图 2c)MonoSLAM 为每帧图像中抽取 Shi-Tomasi角点, 在投影椭圆中主动搜索(active search)特征点匹配.


传统 EKF 方法最主要的局限性如下: 1) 如果 预测函数和更新函数为非线性(通常 V-SLAM 问题都是非线性的), 那么 EKF 并不能保证全局最优,与 Levenberg-Marquardt [20] 等迭代的非线性优化技术相比, 更容易造成误差累积. 如果上一帧处理完成时刻的估计值尚未精确, 传递至下一帧的先验信息便带有误差; 由于上一帧状态不再变化, 所以先验信息中的误差便无法消除, 误差不断向后传递造成 误 差 累 积. 2) 若 将 三维 点 引 入 状态 变 量,则每一时刻的计算复杂度为 O ( n 3 ) , 因此只能处理几百个点的小场景.
MSCFK
为了缓解 EKF 方法的计算复杂度问题, Mourikis于 2007 年提出了 MSCKF. MSCKF 是一个VI-SLAM 方法, 在预测阶段, 使用 IMU 数据进行传递系统状态 [14] ; 在更新阶段, MSCKF 将邻近的 l 帧相机运动参数全部包含进一个状态变量集合C ={ C t-l+1 ... C t } . C 中每个 C i 的估计值均在不断优化, 通常移出 C 前 C i 已较为精确, 由此缓解误差累积. 除此之外, MSCKF 对所有三维点进行消元(Marginalization), 将 C i 与 X j 间的二元约束转换为 C ={ C t-l+1 ... C t } 间的多元约束, 从而将 O ( n ^3 ) 的计算复杂度简化为 O ( n l ^3 ) . 因为一般来说 l << n , 而且 为常数, 所以该方法可以大大降低计算复杂度, 将原来的跟三维点数成立方关系降到了线性关系
----------------------------------------------------------
b)Keyframe-based
PTAM
PTAM 的基本思想如下: 将相机跟踪(Tracking) 和地图构建(Mapping)作为 2 个独立的任务在 2 个线 程并行执行. 地图构建线程仅维护原视频流中稀疏抽取的关键帧(如图 3a 所示)及关键帧中可见的三维点(如图 3b 所示), 这样就可以非常高效地求解目标函数(4)(即 BA); 有了 BA 恢复的精确三维结构, 相机跟踪线程作为前台线程, 仅需优化当前帧运动参数 C t , 足以达到实时的计算效率.
具体来说, 前台线程通过一个匀速运动模型预测当前帧方位, 以搜索地图中的三维点在当前帧图像中对应的 FAST 角点 [23] , 并根据匹配关系优化当前帧方位
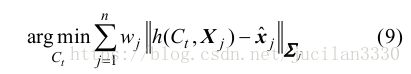
其中 w j 是 Tukey 函数 [24] 对应的权重, 用于缓解误匹配(Outliers)对结果的影响. 如果成功匹配点(Inliers)数不足(如因图像模糊、快速运动等), 则判断跟踪失败, 开始重定位 [25] ——将当前帧与已有关键帧的缩略图进行比较, 选择最相似的关键帧作为当前帧方位的预测, 重复上述特征匹配和方位优步骤. 如果跟踪成功, 判断 C t 是否满足关键帧条件, 一旦符合, 系统将当前帧作为新的关键帧传递给后台构建地图. 后台线程沿极线(Epipolar Line)匹配不同关键帧之间对应于相同场景点的图像特征 点 , 通 过 三 角 化 (Triangulation) 恢 复 这 些 场 景点三维位置, 并对所有关键帧和三维点运行 BA恢复精确的三维地图。
ORB-SLAM


C)直接法
DTAM
DTAM:预测一个与当前帧相机方位Ct十分接近的虚拟相机Cv。在Cv下绘制场景三维模型,由此求解Cv与Ct的相对运动

LSD-SLAM