python 中 feedparser的简单用法
最近在机器学习实战中用到feedparser ,然后简单总结了一下:
feedparser是python中最常用的RSS程序库,使用它我们可轻松地实现从任何 RSS 或 Atom 订阅源得到标题、链接和文章的条目。
首先随便找了一段简化的rss:
<feed xmlns="http://www.w3.org/2005/Atom">
<title type="text">博客园_mrbeantitle>
<subtitle type="text">**********************subtitle>
<id>uuid:32303acf-fb5f-4538-a6ba-7a1ac4fd7a58;id=8434id>
<updated>2014-05-14T15:13:36Zupdated>
<author>
<name>mrbeanname>
<uri>http://www.cnblogs.com/MrLJC/uri>
author>
<generator>feed.cnblogs.comgenerator>
<entry>
<id>http://www.cnblogs.com/MrLJC/p/3715783.htmlid>
<title type="text">用python读写excel(xlrd、xlwt) - mrbeantitle>
<summary type="text">最近需要从多个excel表里面用各种方式整...summary>
<published>2014-05-08T16:25:00Zpublished>
<updated>2014-05-08T16:25:00Zupdated>
<author>
<name>mrbeanname>
<uri>http://www.cnblogs.com/MrLJC/uri>
author>
<link rel="alternate" href="http://www.cnblogs.com/MrLJC/p/3715783.html" />
<link rel="alternate" type="text/html" href="http://www.cnblogs.com/MrLJC/p/3715783.html" />
<content type="html">最近需要从多个excel表里面用各种方式整理一些数据,虽然说原来用过java做这类事情,但是由于最近在学python,所以当然就决定用python尝试一下了。发现python果然简洁很多。这里简单记录一下。(由于是用到什么学什么,所以不算太深入,高手勿喷,欢迎指导)一、读excel表读excel要用...<img src="http://counter.cnblogs.com/blog/rss/3715783" width="1" height="1" alt=""/><br/><p>本文链接:<a href="http://www.cnblogs.com/MrLJC/p/3715783.html" target="_blank">用python读写excel(xlrd、xlwt)</a>,转载请注明。</p>content>
entry>
feed>把他复制到一个.txt文件中,保存为.xml:
import feedparser
print feedparser.parse('')
d=feedparser.parse("tt.xml")
print d['feed']['title']
print d.feed.title # 通过属性访问
print d.entries[0].id
print d.entries[0].content
结果:
{'feed': {}, 'encoding': u'utf-8', 'bozo': 1, 'version': u'', 'namespaces': {}, 'entries': [], 'bozo_exception': SAXParseException('no element found',)}
博客园_mrbean
博客园_mrbean
http://www.cnblogs.com/MrLJC/p/3715783.html
[{'base': u'', 'type': u'text/html', 'value': u'\u6700\u8fd1\u9700\u8981\u4ece\u591a\u4e2aexcel\u8868\u91cc\u9762\u7528\u5404\u79cd\u65b9\u5f0f\u6574\u7406\u4e00\u4e9b\u6570\u636e\uff0c\u867d\u7136\u8bf4\u539f\u6765\u7528\u8fc7java\u505a\u8fd9\u7c7b\u4e8b\u60c5\uff0c\u4f46\u662f\u7531\u4e8e\u6700\u8fd1\u5728\u5b66python\uff0c\u6240\u4ee5\u5f53\u7136\u5c31\u51b3\u5b9a\u7528python\u5c1d\u8bd5\u4e00\u4e0b\u4e86\u3002\u53d1\u73b0python\u679c\u7136\u7b80\u6d01\u5f88\u591a\u3002\u8fd9\u91cc\u7b80\u5355\u8bb0\u5f55\u4e00\u4e0b\u3002\uff08\u7531\u4e8e\u662f\u7528\u5230\u4ec0\u4e48\u5b66\u4ec0\u4e48\uff0c\u6240\u4ee5\u4e0d\u7b97\u592a\u6df1\u5165\uff0c\u9ad8\u624b\u52ff\u55b7\uff0c\u6b22\u8fce\u6307\u5bfc\uff09\u4e00\u3001\u8bfbexcel\u8868\u8bfbexcel\u8981\u7528...
\u672c\u6587\u94fe\u63a5\uff1a\u7528python\u8bfb\u5199excel\uff08xlrd\u3001xlwt\uff09\uff0c\u8f6c\u8f7d\u8bf7\u6ce8\u660e\u3002
', 'language': None}]
**********************feedparser 最为核心的函数自然是 parse() 解析 URL 地址的函数,返回的形式如:
{'feed': {}, 'encoding': u'utf-8', 'bozo': 1, 'version': u'', 'namespaces': {}, 'entries': [], 'bozo_exception': SAXParseException('no element found',)}简单实例:
每个 RSS 和 Atom 订阅源都包含一个标题(d.feed.title)和一组文章条目(d.entries)。
通常,每个文章条目都有一段摘要(d.entries[i].summary),或者是包含了条目中实际文本的描述性标签(d.entries[i].description)
import feedparser
#print feedparser.parse('')
d=feedparser.parse("http://blog.csdn.net/lanchunhui/rss/list")
# d.feed
print d['feed']['title']
print d.feed.title # 通过属性访问
print d.feed.link
print d.feed.subtitle
#d.entries
print type(d.entries)
print len(d.entries)
print 'e.title:',[e.title for e in d.entries][:3]
# d.entries[0].summary是第一篇文章的摘要信息
print 'description==?description:',d.entries[0].description==d.entries[0].summary结果:
计算机科学与艺术
计算机科学与艺术
http://blog.csdn.net/lanchunhui
Email:[email protected]
20
e.title: [u'[\u539f]Handle/Body pattern\uff08Wrapper pattern\uff09', u'[\u539f]Java \u5de5\u7a0b\u4e0e Eclipse \u9ad8\u7ea7\u7528\u6cd5', u'[\u539f]Java \u4e0b\u7684\u51fd\u6570\u5bf9\u8c61']
description==?description: True 其实spyder的variable explorer 窗口可视化的显示了数据的结构:
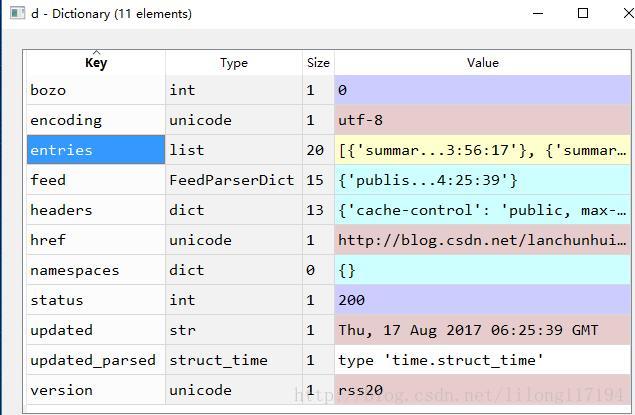
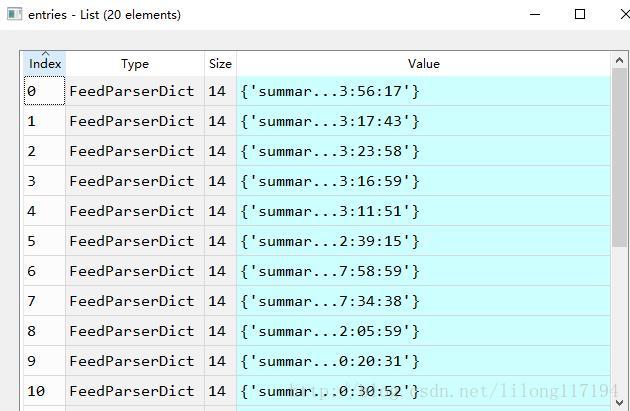
其他基本用法:
参考:
http://www.cnblogs.com/youxin/archive/2013/06/12/3132713.html
>>> import feedparser
>>> d = feedparser.parse("http://feedparser.org/docs/examples/atom10.xml")
>>> d['feed']['title'] # feed data is a dictionary
u'Sample Feed'
>>> d.feed.title # get values attr-style or dict-style
u'Sample Feed'
>>> d.channel.title # use RSS or Atom terminology anywhere
u'Sample Feed'
>>> d.feed.link # resolves relative links
u'http://example.org/'
>>> d.feed.subtitle # parses escaped HTML
u'For documentation only'
>>> d.channel.description # RSS terminology works here too
u'For documentation only'
>>> len(d['entries']) # entries are a list
>>> d['entries'][0]['title'] # each entry is a dictionary
u'First entry title'
>>> d.entries[0].title # attr-style works here too
u'First entry title'
>>> d['items'][0].title # RSS terminology works here too
u'First entry title'
>>> e = d.entries[0]
>>> e.link # easy access to alternate link
u'http://example.org/entry/3'
>>> e.links[1].rel # full access to all Atom links
u'related'
>>> e.links[0].href # resolves relative links here too
u'http://example.org/entry/3'
>>> e.author_detail.name # author data is a dictionary
u'Mark Pilgrim'
>>> e.updated_parsed # parses all date formats
(2005, 11, 9, 11, 56, 34, 2, 313, 0)
>>> e.content[0].value # sanitizes dangerous HTML
u'Watch out for nasty tricks'
>>> d.version # reports feed type and version
u'atom10'
>>> d.encoding # auto-detects character encoding
u'utf-8'
>>> d.headers.get('Content-type') # full access to all HTTP headers
u'application/xml'附:spyder ipython 中文乱码的问题
import sys
reload(sys)
sys.setdefaultencoding('utf8')即可解决。。。