PyTorch NN 常用函数
import torch
from toch import nn
from torch.nn import functional as F
nn.Xxx 和 nn.functional.xxx 区别:
1. nn.Xxx封装了后者, 更加方便, 比如dropout用nn.Xxx时候只需要m.eval()即可让它失效.
2. nn.Xxx更加方便, 不用每次调用把参数都输入一遍.
out = F.conv2d(x, self.cnn1_weight, self.bias1_weight)
out = self.maxpool2(self.relu2(self.cnn2(out)))
3. nn.functional.xxx更偏向底层, 更灵活. 比如TridentNet根据输入尺度不同, 卷积核要用不同的dilation但是参数共享, 此时如下实现更方便.
x_1 = F.conv2d(x, self.weight,dilation=1, padding=1)
x_2 = F.conv2d(x, self.weight,dilation=2, padding=2)
卷积
>>> input (batch, in_channel, height, width) --> filters (out_channel, in_channel, kernel_height, kernel_width)
>>> P = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias=False, (norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)); output = P(input)
>>> forward函数: torch.nn.functional.conv2d(inputs, filters, padding=1)
RNN
>>> rnn = nn.RNN(10, 20, 2) # 分别对应输入的特征数量, 隐层特征数量(每个单词隐向量用长度为20的embedding表示), RNN层数.
>>> input = Variable(torch.randn(5, 3, 10)) # 分别对应时间序列长度(5个单词), 样本数(3句话), 特征数量(每个单词用长度为10的embedding表示).
>>> h0 = Variable(torch.randn(2, 3, 20)) # RNN层数*方向, 样本数, 隐层特征数量.
>>> output, hn = rnn(input, h0)
反卷积 (转置卷积)
这里kernel size表示输入卷积的大小.
>>> input (batch, in_channel, height, width) --> filters (in_channel, out_channel, kernel_height, kernel_width)
>>> P = nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding); output = P(input)
>>> forward函数: torch.nn.functional.conv_transpose2d(inputs, filters, padding=1)
最大池化
>>> input = torch.randn(2, 512, 128, 128)
>>> P = nn.MaxPool2d(kernel_size, stride, return_indices=True); output, indices = P(input)
自适应最大池化 (根据想要输出结果自动计算步长)
>>> input = torch.randn(2, 512, 128, 128)
>>> P = nn.AdaptiveMaxPool2d(output_size, return_indices=True); output, indices = P(input)
2维最大值去池化 (对应位置, 其余补0)
>>> input = torch.randn(2, 512, 128, 128)
>>> P = nn.MaxUnpool2d(kernel_size, stride); output = P(input, indices)
平均池化
>>> input = torch.randn(2, 512, 128, 128)
>>> P = nn.AvgPool2d(kernel_size, stride=2); output = P(input)
>>> forward函数: torch.nn.functional.avg_pool2d(input, kernel_size, stride, padding, ceil_mode=False, count_include_pad=True)
自适应平均池化 (根据想要输出结果自动计算步长)
>>> input = torch.randn(2, 512, 128, 128)
>>> P = nn.AdaptiveAvgPool2d(output_size); output = P(input)
分数最大池化 (根据想得到的输出尺寸进行池化, 池是随机的)
>>> input = torch.randn(2, 512, 128, 128)
>>> P = nn.FractionalMaxPool2d(3, output_size=(13, 12)); output = P(input)
>>> P = nn.FractionalMaxPool2d(3, output_ratio=(0.5, 0.5)); output = P(input)
上采样 (分别对应普通上采样和双线性插值)
>>> P = nn.Upsample(scale_factor=2, mode='nearest')
>>> P = nn.Upsample(scale_factor=2, mode='bilinear')
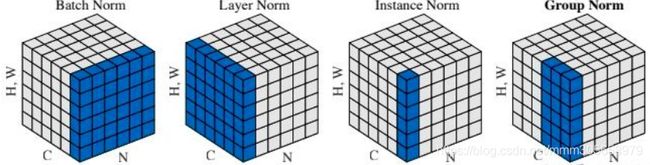
批正则化 (Batch Norm)
N*H*W求均值方差, 训练阶段每个batch需要大量样本数.
>>> bn = nn.BatchNorm2d(num_features=3, eps=0, affine=False, track_running_stats=False) # num_features指定channel的数量, affine=False 则γ=1,β=0也就是不需要对标准化后的再拉伸; track_running_stats=True则使用Momentum的移动加权平均来更新均值方差; model.eval() 可以在联合训练时冻结BN参数更新
层正则化 (Layer Norm)
C*H*W求均值方差, 从而实现单样本正则.
>>> ln = nn.LayerNorm(normalized_shape=[3, 5, 5], eps=0, elementwise_affine=False) # normalized_shape指定C*H*W维度, elementwise_affine=True时γ和β的长度为C*H*W
实例正则化 (Instance Norm)
H*W求均值方差, 也可以单样本正则.
>>> In = nn.InstanceNorm2d(num_features=3, eps=0, affine=False, track_running_stats=False)
组正则化 (Group Norm)
(部分C)*H*W求均值方差,可以单样本正则.
>>> gn = nn.GroupNorm(num_groups=4, num_channels=20, eps=0, affine=False) # num_groups指定把channel分成几组.
激活函数
m = nn.ReLU(); F.relu_(output) 对应inplace=True; # ReLU
m = nn.RReLU() # Randomized Leaky ReLU
m = nn.Sigmoid() # Sigmoid
m = nn.Tanh() # Tanh
m = nn.ELU() # ELU
m = nn.CELU() # CELU
m = nn.SELU() # SELU
m = nn.GLU() # GLU
m = nn.GELU() # GELU
m = nn.LeakyReLU() # LeakyReLU
m = PReLU() # PReLU
损失函数
torch.nn.functional.binary_cross_entropy(input, target, weight=None, size_average=True, reduce=True) # input和target表示预测和GT, weight表示每个类别权重, size_average损失取平均, reduce每个预测的损失单独返回.
torch.nn.functional.l1_loss(input, target, size_average=True, reduce=True) # 一般用于Bbox回归
梯度优化
optimizer = class torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False) # SGD
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1) # 达到指定epoches更改学习率