李宏毅DLHLP.03.Speech Recognition.1.Listen, Attend, and Spell (LAS)
文章目录
- 介绍
- Listen
- Down Sampling
- Attention
- Beam Search
- Teacher Forcing
- Attention的位置
- Location-aware attention
- LAS实作:Hokkien (閩南語、台語)
- Limitation of LAS
介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站:http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
B站视频:https://www.bilibili.com/video/BV1EE411g7Uk?t=222
公式输入请参考:在线Latex公式
Listen, Attend, and Spell实际上就是典型的带attention的seq2seq模型,其中Listen, Attend是Encoder,Spell是Decoder。
Chorowski. et al., NIPS’15
其他四个 模型其实也都是seq2seq模型,因此为了区分彼此,就叫LAS
Listen
目标:只提取语音特征表示,忽略噪音
• Extract content information
• Remove speaker variance, remove noises
输入:acoustic features { x 1 , x 2 , ⋯ , x T } \{x^1,x^2,\cdots,x^T\} {x1,x2,⋯,xT}
输出:high-level representations { h 1 , h 2 , ⋯ , h T } \{h^1,h^2,\cdots,h^T\} {h1,h2,⋯,hT}

中间的Encoder可以单向RNN

也可以是双向RNN

可以是1维卷积,每个卷积每次扫多个acoustic features,有多个卷积核进行扫描

然后有不同大小的卷积扫描看到的范围也不一样大。而且上层的卷积看到的范围更加大(下图的蓝色三角形)
• Filters in higher layer can consider longer sequence
• CNN+RNN is common

模型还可以是Self-attention Layers

Down Sampling
上节中提到,1秒声音信息就有100个frame向量,所包含信息太多,要进行下采样操作,以提高计算效率(相邻向量其实差不多)


对于CNN的下采样:只考虑第一和最后一个卷积结果
Dilated CNN has the same concept
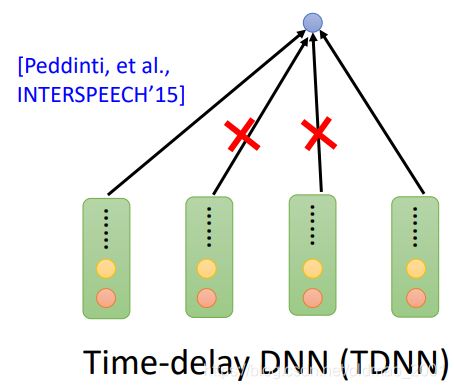
下面的attention为了简化计算,只对范围内的向量进行attention计算,超出范围的则不计算attention,这个很容易理解,其实对于语音识别而言,离得较远的音节对当前音节的识别没什么很大用处。

Attention
这里不做解释,直接贴图,详细说明可以参考paper带读.机器翻译Attention NMT

这里提到蓝色match的计算有两种方式:
Dot-product Attention [Chan, et al., ICASSP’16]

Additive Attention [Chorowski. et al., NIPS’15]

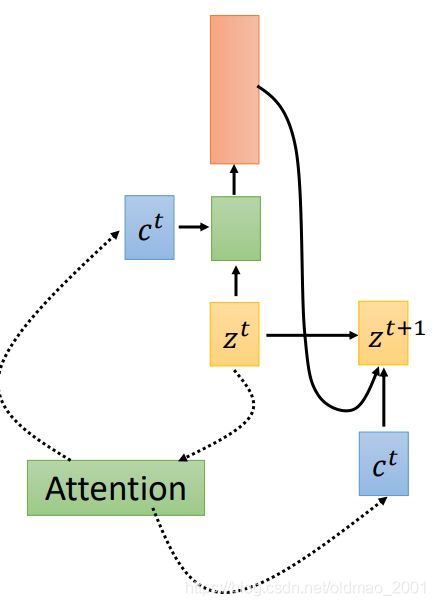
上面算出来的权重要经过softmax,然后加权平均得到最后的 c 0 c^0 c0(c称为context vector):

初始输入得到下一步的输出 z 1 z^1 z1,并得到预测结果:

然后 z 1 z^1 z1再算 c 1 c^1 c1,以此类推

Beam Search
这个在ng的课,还有NLP训练营里面已经讲得很清楚也不啰嗦了。
The red path is Greedy Decoding.
The green path is the best one.
Not possible to check all the paths …

Keep B best pathes at each step
B (Beam size) = 2每次保存最好的两个选择。

Teacher Forcing
是指在训练encoder-Decoder架构的seq2seq模型的过程中,使用groud truth作为每个时间步的输入,调整每个时间步的输出:

测试的时候才接前一个时间步的输入。
Attention的位置
[Bahdanau. et al., ICLR’15] :将attention的结果用于下一个时间步

[Luong, et al., EMNLP’15]:将attention的结果用于当前时间步

第一篇将attention用于语音识别的论文:[Chan, et al., ICASSP’16] 则是将上面两种进行了结合。
老师给出了自己的理解:attention最早用于机器翻译上,翻译由于有词与词之间的不对应性,需要在当前词关注其他位置的词,所以用了attention,效果还不错,但是语音识别上基本上都是根据当前波形走的,这样识别当前发音的时候去关注后面的发音会有好结果吗?
下图是识别token时应该关注的输入(红色实际上是 α \alpha α权重)应是从左到右的

下图是乱attention的结果:

因此有人提出来了
Location-aware attention
其思想就是在生成当前attention的时候要考虑前一个时刻的attention结果。

但是最后当语料够多,不用Location-aware attention 模型也可以学到相应的attention要慢慢往右移

另外一个有意思的现象是,下表中LAS语音识别结果把aaa和triple a识别的分数一样。也就是在LAS自带LM属性。

LAS实作:Hokkien (閩南語、台語)
不能直接识别为对应的中文发音

要加上翻译效果

具体做法:

而且做的过程中忽略:
背景音乐音效
语音与字幕是否对齐
台罗拼音
最后结果:Accuracy = 62.1%
Limitation of LAS
无法边听边输出结果(on-line speech recognition,为什么不反应为实时翻译?)
LAS outputs the first token after listening the whole input.
• Users expect on-line speech recognition.
LAS is not the final solution of ASR!