快速入门Django(结合深度学习DNN实例)
在熟悉了简单操作后,做一点有意思的事情吧
本文实现的功能:
1.使用Keras创建,DNN深度学习网络模型,解决多分类问题,数据集是IRIS数据集。
2.Keras模型保存,及重新加载
2.结合我的上一篇文章的结果,最终实现了,由网页写入data,将data传入已经训练好的模型,predict结果输入数据库,最终将predict显示在网页。
此篇project非常适合入门,能够快速看到结果,但某些细节好比较粗糙,有待完善。欢迎指正与交流。
参考的博客,但调试时有很多bug,自己做了些改动,此处附上原博客链接:
是https://www.jianshu.com/p/1d88a6ed707e
OK
1.Keras创建DNN深度学习网络模型
前期准备
如果想用在你的电脑上使用Keras,需要以下工具:
Python
TensorFlow
Keras
这里,选择TensorFlow作为Keras的后端工具。使用以下Python代码,可以输出Python、TensorFlow以及Keras的版本号:
import sys
import keras as K
import tensorflow as tf
py_ver = sys.version
k_ver = K.__version__
tf_ver = tf.__version__
print("Using Python version " + str(py_ver))
print("Using Keras version " + str(k_ver))
print("Using TensorFlow version " + str(tf_ver))
OK
IRIS数据集
IRIS数据集(鸢尾花数据集),经典的机器学习数据集,适合作为多分类问题的测试数据。
IRIS数据集是用来给鸢尾花做分类的数据集,一共150个样本,每个样本包含了花萼长度(sepal length in cm)、花萼宽度(sepal width in cm)、花瓣长度(petal length in cm)、花瓣宽度(petal width in cm)四个特征,将鸢尾花分为三类,分别为Iris Setosa,Iris Versicolour,Iris Virginica,每一类都有50个样本。
DNN代码
DNN结构:
搭建的DNN由输入层、隐藏层、输出层和softmax函数组成,其中输入层由4个神经元组成,对应IRIS数据集中的4个特征,作为输入向量。
隐藏层有两层,每层分别有5和6个神经元。
之后就是输出层,由3个神经元组成,对应IRIS数据集的目标变量的类别个数。
最后,就是一个softmax函数,用于解决多分类问题而创建。
直接上代码:
# 导入模块
import os
import numpy as np
import keras as K
import tensorflow as tf
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
#from keras.models import load_model
from keras.models import load_model as keras_load_model
# 读取CSV数据集,并拆分为训练集和测试集
# 该函数的传入参数为CSV_FILE_PATH: csv文件路径
def load_data(CSV_FILE_PATH):
IRIS = pd.read_csv(CSV_FILE_PATH)
target_var = 'Species' # 目标变量
# 数据集的特征
features = list(IRIS.columns[1:6])
features.remove(target_var)
# 目标变量的类别
Class = IRIS[target_var].unique()
# 目标变量的类别字典
Class_dict = dict(zip(Class, range(len(Class))))
# 增加一列target, 将目标变量进行编码
IRIS['target'] = IRIS[target_var].apply(lambda x: Class_dict[x])
# 对目标变量进行0-1编码(One-hot Encoding)
lb = LabelBinarizer()
lb.fit(list(Class_dict.values()))
transformed_labels = lb.transform(IRIS['target'])
y_bin_labels = [] # 对多分类进行0-1编码的变量
for i in range(transformed_labels.shape[1]):
y_bin_labels.append('y' + str(i))
IRIS['y' + str(i)] = transformed_labels[:, i]
# 将数据集分为训练集和测试集
train_x, test_x, train_y, test_y = train_test_split(IRIS[features], IRIS[y_bin_labels], \
train_size=0.7, test_size=0.3, random_state=0)
return train_x, test_x, train_y, test_y, Class_dict
def predict(input_data):
print("Using loaded model to predict...")
load_model = keras_load_model("D:/project/iris_keras_dnn/iris_model.h5")
np.set_printoptions(precision=4)
# unknown = np.array([[6.1, 3.1, 5.1, 1.1]], dtype=np.float32)
unknown = np.array([ input_data ], dtype=np.float32)
predicted = load_model.predict(unknown)
print("final......Using model to predict species for features: ")
print(unknown)
print("\nfinal......Predicted softmax vector is: ")
print(predicted)
# species_dict = {v: k for k, v in load_data.Class_dict.items()}
# print("\nfinal......Predicted species is: ")
# print(species_dict[np.argmax(predicted)])
def main():
# 0. 开始
print("\nIris dataset using Keras/TensorFlow ")
np.random.seed(4)
tf.set_random_seed(13)
# 1. 读取CSV数据集
print("Loading Iris data into memory")
CSV_FILE_PATH = 'D:/project/iris_keras_dnn/Iris_data/iris.csv'
train_x, test_x, train_y, test_y, Class_dict = load_data(CSV_FILE_PATH)
# 2. 定义模型
init = K.initializers.glorot_uniform(seed=1)
simple_adam = K.optimizers.Adam()
model = K.models.Sequential()
model.add(K.layers.Dense(units=4, input_dim=4, kernel_initializer=init, activation='relu'))
model.add(K.layers.Dense(units=6, kernel_initializer=init, activation='relu'))
model.add(K.layers.Dense(units=3, kernel_initializer=init, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=simple_adam, metrics=['accuracy'])
# 3. 训练模型
b_size = 1
max_epochs = 10
print("Starting training ")
model.fit(train_x, train_y, batch_size=b_size, epochs=max_epochs, shuffle=True, verbose=1)
print("Training finished \n")
# 4. 评估模型
eval = model.evaluate(test_x, test_y, verbose=0)
print("Evaluation on test data: loss = %0.6f accuracy = %0.2f%% \n" \
% (eval[0], eval[1] * 100) )
# 5. 使用模型进行预测
np.set_printoptions(precision=4)
unknown = np.array([[6.1, 3.1, 5.1, 1.1]], dtype=np.float32)
predicted = model.predict(unknown)
print("main......Using model to predict species for features: ")
print(unknown)
print("\nmain......Predicted softmax vector is: ")
print(predicted)
species_dict = {v:k for k,v in Class_dict.items()}
print("\nmain......Predicted species is: ")
print(species_dict[np.argmax(predicted)])
# save model
print("main......Saving model to disk \n")
mp = "D:/project/iris_keras_dnn/iris_model.h5"
model.save(mp)
main()
print("final......Predicte is: ")
predict([6.1, 3.1, 5.1, 1.1])
OK
Keras模型保存,及重新加载
Keras使用HDF5文件系统来保存模型。模型保存的方法很容易,只需要使用save()方法即可。
# save model
print("main......Saving model to disk \n")
mp = "D:/project/iris_keras_dnn/iris_model.h5"
model.save(mp)
在实际的使用中,我们不需要再用自己的方法来实现模型的预测功能,只需使用Keras给我们提供好的模型导入功能(keras.models.load_model())即可。
有专门的Python代码即可加载模型,此代码我放在了Django 的 views.py函数中。
###进入model处理
print("Using loaded model to predict......")
load_model = keras_load_model("D:/project/iris_keras_dnn/iris_model.h5")
np.set_printoptions(precision=4)
#确定NumPy对象的显示方式。 precision:int或None,可选浮点输出的精度位数(默认为8)。可以不选
predicted = load_model.predict(unknown)
print("\nfinally.......Predicted softmax vector is: ")
print(predicted)
结合网页
models.py
from __future__ import unicode_literals
from django.db import models
# Create your models here.
class message(models.Model):
username = models.CharField(max_length=1000)
password = models.CharField(max_length=1000)
predict_result=models.CharField(max_length=1000)
views.py
#from django.shortcuts import render
#
## Create your views here.
#
#
## 添加 index 函数,返回 index.html 页面
#def index(request):
# return render(request, 'index.html')
from __future__ import unicode_literals
from myapp import models
from django.shortcuts import render
#优化它以使用get_template()而不是硬编码模板和模板路径。Django需要一个可以在一行代码中完成所有这些操作的快捷方式。
from keras.models import load_model as keras_load_model
import numpy as np
#插入函数
def insert(request):
if request.method == "POST":
username = request.POST.get("username", None)
password = request.POST.get("password", None)
print("Using loaded model to predict......")
load_model = keras_load_model("D:/project/iris_keras_dnn/iris_model.h5")
np.set_printoptions(precision=4)
#确定NumPy对象的显示方式。 precision : int或None,可选浮点输出的精度位数(默认为8)。可以不选
unknown = np.array([ username.split(" ") ], dtype=np.float32)
predicted = load_model.predict(unknown)
print("\nfinally.......Predicted softmax vector is: ")
print(predicted)
twz = models.message.objects.create(username=username, password=password,predict_result=predicted)
#objects.create 往数据表中插入内容的方法
twz.save()
return render(request,'insert.html')
#定义展示函数
def list(request):
people_list = models.message.objects.all()
return render(request, 'show.html', {"people_list":people_list})
urls.py
from django.contrib import admin
from django.conf.urls import url
from myapp import views # 在这里添加这一行代码,导入 views
#urlpatterns = [
## path('admin/', admin.site.urls),
## path('', views.index),# 在这里添加这一行代码,这是我们上一步编写的视图函数的路由,默认是 / 路径
# url(r'^admin/', admin.site.urls),
# url(r'^insert/$',views.insert),
# url(r'^show/$',views.list),
#
#]
urlpatterns = [
url(r'^insert/$',views.insert),
url(r'^show/$',views.list),
url(r'^admin/', admin.site.urls),
]
insert.html
这个部分没有改变,我们只拿username做测试
show.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>输出</title>
</head>
<body>
<h1>信息输出</h1>
<table>
<tr>
<th>用户名:</th>
<th>治疗方案:</th>
<th>DNN的输出:</th>
</tr>
{% for line in people_list %}
<tr>
<td>{{line.username}}</td>
<td>{{line.password}}</td>
<td>{{line.predict_result}}</td>
</tr>
{% endfor %}
</table>
</body>
</html>
新建数据库
之前的数据库不可以用了,要换成新的来做
conda控制窗口运行语句,写入
python manage.py makemigrations
python manage.py migrate
OK
启动
conda控制窗口运行语句,启动
>python manage.py runserver
OK
结果
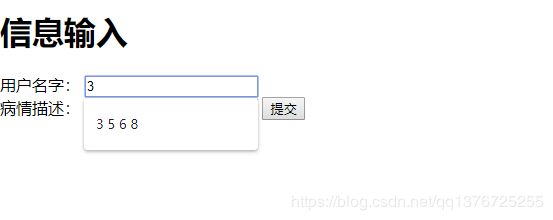

OK
下一步骤,就是要完善我们的代码
学习如何对数据库进行操作