tf.layers.conv1d
t f . l a y e r s . c o n v 1 d tf.layers.conv1d tf.layers.conv1d
conv = tf.layers.conv1d(inputs, filters, kernel_size, name='conv')
inputs: 输入tensor, 维度(batch_size, seq_length, embedding_dim) 是一个三维的tensor;其中,batch_size指每次输入的文本数量;seq_length指每个文本的词语数或者单字数;embedding_dim指每个词语或者每个字的向量长度;例如每次训练输入2篇文本,每篇文本有100个词,每个词的向量长度为20,那input维度即为(2, 100, 20)。
filters:过滤器(卷积核)的数目
实例:filters=2
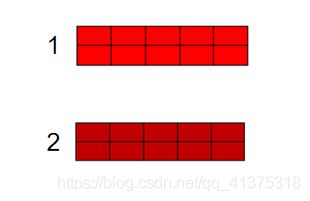
kernel_size:卷积核的大小,卷积核本身应该是二维的,这里只需要指定一维,因为第二个维度即长度与词向量的长度一致,卷积核只能从上往下走,不能从左往右走,即只能按照文本中词的顺序,也是列的顺序。
实例:kernel_size=2


# coding: utf-8
import tensorflow as tf
num_filters = 2
kernel_size = 2
batch_size = 1
seq_length = 4
embedding_dim = 5
embedding_inputs = tf.constant(-1.0, shape=[batch_size, seq_length, embedding_dim], dtype=tf.float32)
sess = tf.InteractiveSession()
embedding_inputs.eval()

with tf.name_scope("cnn"):
conv = tf.layers.conv1d(embedding_inputs, num_filters, kernel_size, name='conv')
session = tf.Session()
session.run(tf.global_variables_initializer())
print (session.run(conv).shape)

参数补充:
tf.layers.conv1d(
inputs,
filters,
kernel_size,
strides=1,
padding='valid',
data_format='channels_last',
dilation_rate=1,
activation=None,
use_bias=True,
kernel_initializer=None,
bias_initializer=tf.zeros_initializer(),
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
trainable=True,
name=None,
reuse=None
)
实例:
conv1_g = tf.layers.conv1d(inputs=z_combine, filters=256, kernel_size=5,padding='same')
z_combine = tf.concat([z, conditioning],-1)
G_sample = generator_conditional(Z, Condition) # 取得生成器的生成结果
Z = tf.placeholder(tf.float32, shape=[batch_size, 4,1]) # Z表示生成器的输入(在这里是噪声),是一个(N,16,2)矩阵
Condition = tf.placeholder(tf.float32, shape=[batch_size, 4,1]) # 生成器和判别器的条件输入,是一个(N,4,2)的矩阵
sample_Z((batch_size , 4,1)