初始PyTorch(六):卷积神经网络CNN
CNN的主要操作:输入~ 神经元(提取特征)[Convolution、激活函数ReLU 、Pooling等] ~ 全连接层(分类)~ 输出
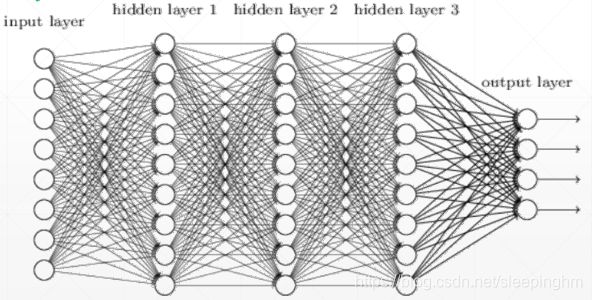
eg:4层的神经网络(不包括第一层即输入层),其中有3个隐藏层和1个输出层【每一层包含输入它的参数和它的输出】。
对于MINST数据集像素为28*28,维度变换为[784,256]~[256,256]~[256,256]~[256,10]。
一、卷积核
卷积核计算过程不多赘述,参考吴恩达deeplearning之CNN—卷积神经网络入门。
修改滤波矩阵(卷积核),可进行边缘检测、锐化和模糊等操作;滤波器越多,提取到的图像特征就越多,网络所能在未知图像上识别的模式也就越好。对于多滤波器情况(RGB图像的卷积处理):
输入 x:[b,3,28,28] , 其中b为Batchsize,3为RGB的三通道,[28,28]为图片大小。
单个卷积核 one-k:[3, 3,3] , 整个卷积核叫一个kennel,第一个3对应于RGB,后俩个3为卷积核的大小。
多个卷积核 multi-k:[16, 3, 3, 3] ,假设一共有16个kennels,后面的3和前面叙述的含义相同,
偏置 bias:[16] ,与核数相同。
输出 out:[b, 16, 28, 28] (有padding)
二、神经单元
训练神经网络的时候,一个神经单元一般为conv2d,Batch,pooling,relu等。
conv2d
'''输入x为[B,C,H,W],其中B:batch数量,C:channel数量,H:数据的长,W:数据的宽。'''
layer=nn.Conv2d(1,3,kernel_size=3,stride=1,padding=0)
#x:[1,1,28,28]
out=layer.forward(x)
#[1,1,28,28]~[1,3,26,26]
layer=nn.Conv2d(1,3,kernel_size=3,stride=1,padding=1)
out=layer.forward(x)
#[1,1,28,28]~[1,3,28,28]
layer=nn.Conv2d(1,3,kernel_size=3,stride=2,padding=1)
out=layer.forward(x)
#[1,1,28,28]~[1,3,14,14]权重w的shape和输入x的channel要对应,比如输入x为[1, 1, 28, 28]而w为[16,3,5,5],就不对应,就会报错。
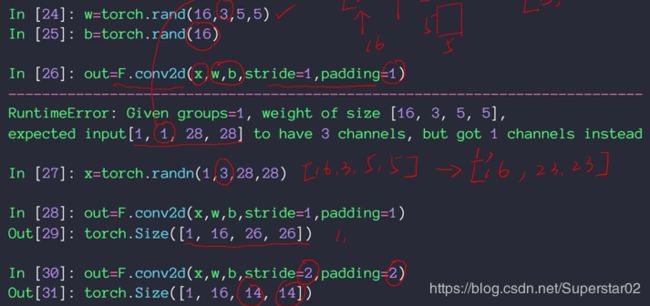
池化层与采样
下采样:
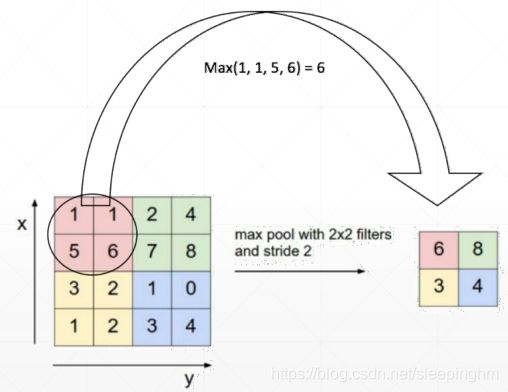
#Max pooling:以一定步长移动一个窗口,然后取窗口内的最大值
nn.MaxPool2d(2,stride=2)
#[1,16,14,14]~[1,16,7,7]
#Avg pooling:以一定步长移动一个窗口,然后取窗口内的平均值
F.avg_pool2d(x,2,stride=2)
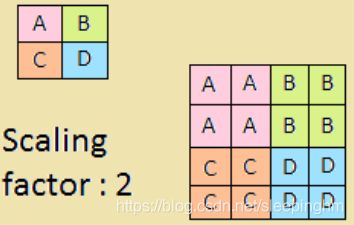
#[1,16,14,14]~[1,16,7,7]上采样:
F.interpolate(x,scale_factor=2,mode='nearest')
#第一个参数为输入x,第二个参数为倍数,第三个参数为mode模数,如双线性,三线性差值,近邻差值等。ReLU
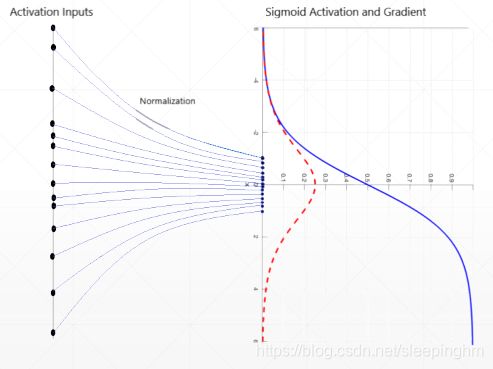
有时使用Sigmoid函数时,如果数据过小或者过大会出现梯度弥散的情况,长时间得不到更新,此时可以使用Relu函数。

F.interplayer=nn.ReLu(inplace=True) #inplace=True 节约内存消耗
out=layer(x) #out=F.relu(x)也可以
#[1,16,7,7]~[1,16,7,7]Batch Normalization
有时Sigmoid函数,为了避免梯度弥散,要把输入的值控制在一定范围内,在进入Sigmoid之前,先做一个标准化(normalization)操作,变化到以0为均值,以σ为方差,就可以让值映射在0附近。
BN公式: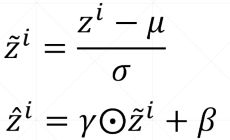 也就是让数据服从N(β, γ)分布【式一是使数据逼近于N(0,1),μ和σ可以根据当前batch统计出来,但是β, γ是模型学出来的,需要梯度信息。】
也就是让数据服从N(β, γ)分布【式一是使数据逼近于N(0,1),μ和σ可以根据当前batch统计出来,但是β, γ是模型学出来的,需要梯度信息。】
#对一维数据,输入channel的数量
x=torch.rand(100,16,784) # x原本为[100,16,28,28] 28*28打平成一维
layer=torch.nn.BatchNorm1d(16)
out=layer(x)
layer.running_mean #均值
layer.running_var #方差
#对二维数据,输入channel数量,forward计算之后,shape不变,layer.weight=γ,b=β。
# x为[1,16,7,7] channel为16
layer=torch.nn.BatchNorm2d(16)
layer.weight #γ [16]
layer.bias #β [16]
'''
注意test前使用layer.eval()
'''三、全连接层
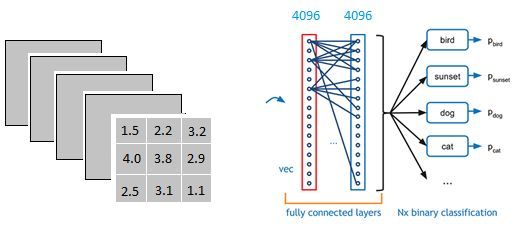 该全连接层中的每一层是由许多神经元组成的(1x 4096)的平铺结构。
该全连接层中的每一层是由许多神经元组成的(1x 4096)的平铺结构。
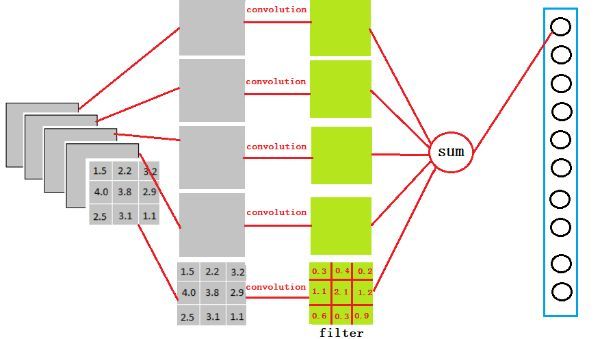
从上图我们可以看出,我们用一个3x3x5的过滤器去卷积激活函数的输出,得到的结果就是一个fully connected layer的一个神经元的输出,这个输出就是一个值[有4096个神经元,实际就是用一个3x3x5x4096的卷积层去卷积激活函数的输出]
进行卷积的作用就是把分布式特征representation映射到样本标记空间,即把特征整合到一起,输出为一个值。
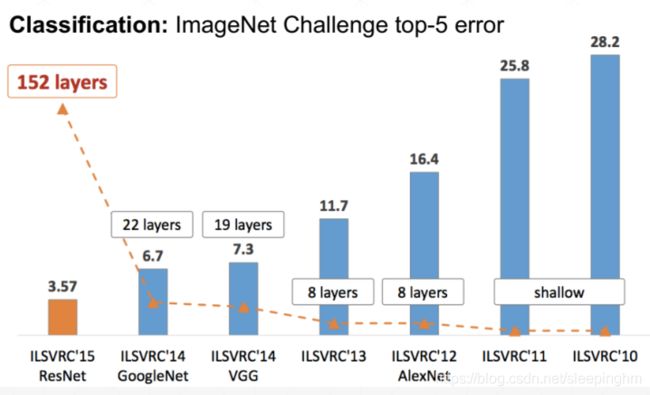
四、经典神经网络(待更新
1.LeNet
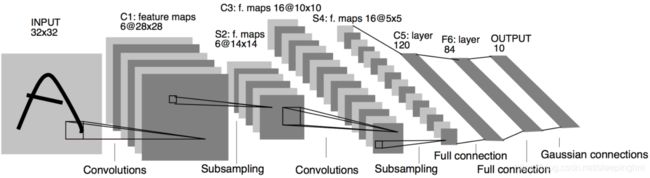 LeNet
LeNet
共7层网络(不计输入层),分别为:3个卷积层、2个下采样层(Subsampling,S2)、1个全连接层(F6)、1个输出层。
2、AlexNet
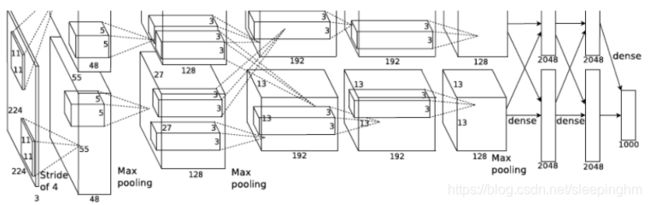 AlexNet
AlexNet
8层结构加入了MaxPoolig和Relu、卷积核11x11。
3、VGG
VGG16共包含:
- 13个卷积层(Convolutional Layer),分别用conv3-XXX表示,kernel size=3.
- 3个全连接层(Fully connected Layer),分别用FC-XXXX表示
- 5个池化层(Pool layer),分别用maxpool表示
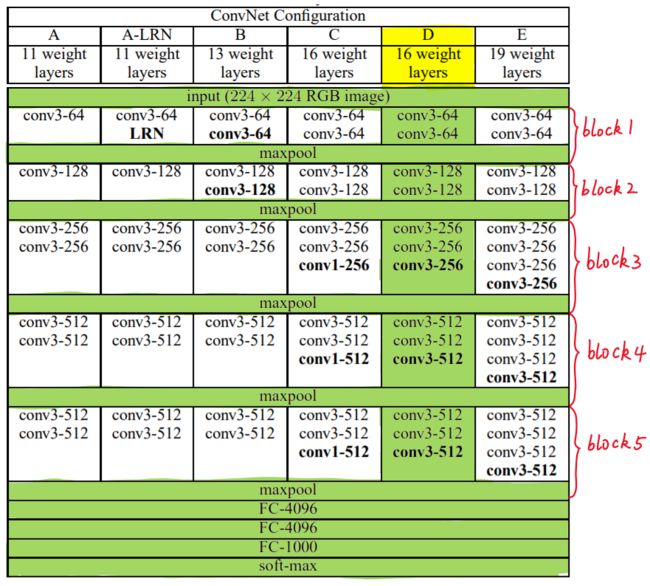 VGG16
VGG16

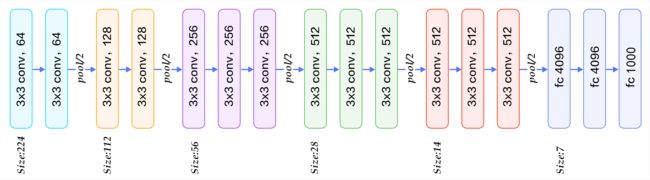
VGG的输入图像是 224x224x3 的图像,随着层数的增加,后一个块内的张量相比于前一个块内的张量:
- 通道数翻倍,由64依次增加到128,再到256,直至512保持不变,不再翻倍
- 高和宽变减半,由 224→112→56→28→14→7
4、GoogLeNet
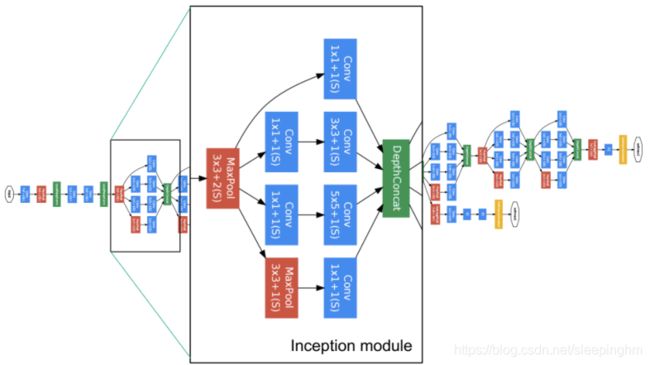
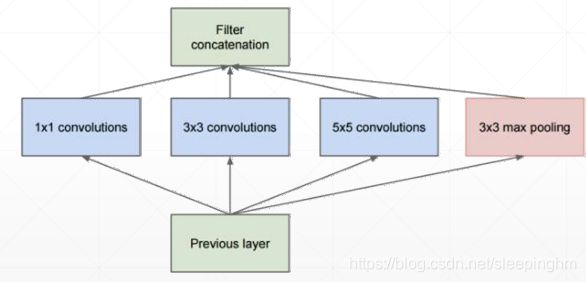
22层模型,使用了11 33 55的核。GAP全池平均化取代全连接层。
5、ResNet
GAP取代全连接层。