python爬虫教程 遍历所有网页
第二天: 遍历网页内的所有链接
上一节中有一个小问题, 我们需要注意一下, 很多网站为了反爬会检测用户代理, 所以我们需要设置用户代理, 来停止爬虫失效.
设置用户代理
默认情况下, urllib2使用python-urllib2/2.7作为用户代理下载网页内容, 其中2.7是python的版本号. 但是这样存在一个问题, 有些网站可能会封掉你使用的默认代理, 如果我们能自己设置代理, 就可以解决这一个问题. 下面我们使用代理tubedown.cn作为代理来下载网页, 代理一般为浏览器的信息, 这里只是以tubedown.cn为例, 你可以根据你浏览器的信息写入就行:
#coding:utf8
import urllib2
def download(url, user_agent='tubedown.cn', num_retries=2):
print 'downloading:', url
headers = ('User-agent': user_agent)
request = urllib2.Request(url, headers=headers)
try:
html = urllib2.urlopen(request).read().decode('utf8', 'ignore').encode('gbk', 'ignore')
except urllib2.URLError as e:
print 'download error:', e.reason
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
return download(url, unm_retries-1)
if html:
print url, 'download complated!'
return html
爬取页面下的所有链接
我们下载网页的函数已经很完美了, 现在我们可以用它来爬取整个网站了, 每个页面中都有超链接, 我们可以采用跟踪超链接的方式把整个网站都爬下来
#coding:utf8
import re
import urlparse
def link_crawler(seed_url, link_regex):
crawl_queue = [seed_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
for link in get_links(html):
if re.match(link_regex, link):
if link.find(seed_url) < 0:
link = urlparse.urljoin(seed_url, link)
crawl_queue.append(link)
def get_links(html):
if not html:
return []
webpage_regex = re.compile(']+href=["\'](.*?)["\']' , re.IGNORECASE)
return webpage_regex.findall(html)
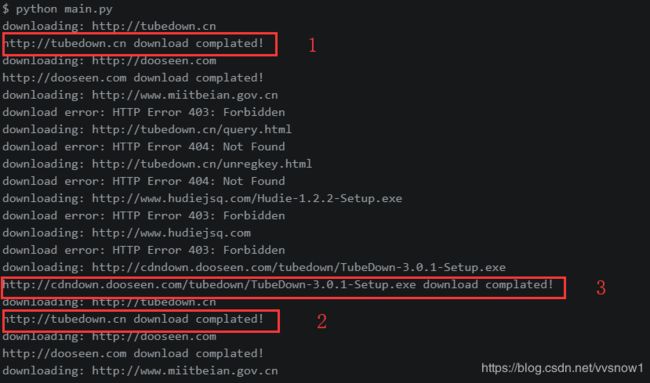
当我们执行python main.py, 却出现了两个意想不到的情况, 如果所示:
1和2说明网址有重复下载的,3说明下载了不必要的文件, 我们修改一下我们的代码
def link_crawler(seed_url, link_regex):
crawl_queue = [seed_url]
seen_url = set([])
while crawl_queue:
url = crawl_queue.pop()
seen_url.add(url)
if url.endswith('.exe'):
continue
html = download(url)
for link in get_links(html):
if re.match(link_regex, link):
if link.find(seed_url) < 0:
link = urlparse.urljoin(seed_url, link)
if link not in seen_url:
crawl_queue.append(link)
好了这次不会重复下载了, 但是还有一个小问题, 那就是网站有一个网址是油管的, 需要代理才能访问, 我们暂时不管这个, 把这个网站跳过去, 再次修改代码:
def link_crawler(seed_url, link_regex):
crawl_queue = [seed_url]
seen_url = set([])
while crawl_queue:
url = crawl_queue.pop()
seen_url.add(url)
if url.endswith('.exe'):
continue
if 'youtube' in url:
continue
html = download(url)
for link in get_links(html):
if re.match(link_regex, link):
if link.find(seed_url) < 0:
link = urlparse.urljoin(seed_url, link)
if link not in seen_url:
crawl_queue.append(link)
我们执行python main.py, 结果如下

这次基本就没有问题了, 但是有些网页下会载失败, 我们在之后的小节中再讲