语音识别/声纹识别的基础概念
语言模型的作用:
已知文本前面有若干个词,预测下一个词出现的概率是多少。简单地说,就是一句话符合不符合当前已知的说话习惯。
N-gram模型:
N-gram模型基于一个假设:第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现的概率的乘积。它没有训练的过程,只是统计当前词在N元组里出现的次数。一般业内最大的使用三元模型,也就是3-gram模型。因为虽然N越大计算越准确,但是考虑到计算量过大的问题(≥4元的模型用的很少,因为训练它不仅需要更庞大的语料,数据还稀疏严重,时间复杂度也高,精确度却提高的不多),三元模型最合适。
一元模型,1-gram:当前模型出现的所有词里面,这个词出现过多少次。
二元模型,2-gram,Bi-gram:把每相邻的两个词组成一个二元组,这个二元组在所有的二元组里面出现过多少次。
三元模型,3-gram,Tri-gram:把每相邻的三个词组成一个三元组,这个三元组在所有的三元组里面出现过多少次。这里的计算量就很大了。
所以总结一下Bi-gram和Tri-gram只需要一句话:“当前词的出现,可能跟前面两个词有关,也可能跟前面一个词有关”。
组会上讨论过的一个误区:N-gram模型不能和GMM-UBM用到的MAP/MLE划等号,说它们相似也是不对的。因为:最大似然里面,相似的是两个分布,此模型关注的不是向量间是否满足最大似然,而且下一个向量在这个分布里会不会出现。
这篇文章里有一个具体公式计算的例子,很生动,可以加深理解:https://www.cnblogs.com/chaosimple/p/3376438.html
对齐:
知道哪段区域发什么音(这段录音对应的什么文字,什么时间点,发了什么音),找到什么时间每帧发哪个音,输出它。语音是10ms一帧时,对齐是为了知道,每帧属于哪个音,哪个类别。
monophone音,与上下文无关;triphone音,与上下文有关,要用三音子把它区分开来,每个三音子都有开始,中间,结束三个状态。三音子的状态就叫senone。
强制对齐结果:把每一帧对齐到一个状态,每个状态都是它在三音子中的某个状态,即输出的一个节点。比如我们可以用交叉熵来构建一个loss function来训练一个模型。
因为开组会和平时学习基础知识的时候总会遇到一个问题,“为什么帧的长度要设置成25ms?”,在这里再说一个帧长和分帧的地方 :一般时域分帧是10-30ms分为一帧。引自:《MATLAB在语音信号分析与合成中的应用》,宋知用,北航出版社。原书中第二章的内容,宋知用老师本人在论坛上的回复内容是:“不论用哪一种方法都要对帧长(记为wlen)和帧移(记为inc)进行赋值。语音信号是一种准周期性的信号,一般认为语音在10-30ms之内是稳态的,所以取帧长也在10-30ms之内,有取20ms,也有取30或40ms。而帧移常取5-15ms之间”。而我们常看到的提取mfcc时,一般是以帧长25ms,帧移10ms分帧。还有个采样率的问题:采样率16000是什么意思?就是一秒钟采样16000次,也就是从一秒钟里取出来16000个点。为什么取16000呢?具体可以百度/谷歌奈奎斯特采样定理。
人体语音学基本概念:
1.元音,vowel; 按气流的受阻程度分,“唯二”的两个半元音是:i,u;
2.辅音,consonant;
3.音节,syllable;由一个或几个音素构成的最小的语音结构单位;
4.音素,phoneme;是语音中最小的单位,依据音节的发音动作来分析,一个动作构成一个音素。(如:a,i)('ai'不是音素,因为ai=a+i)
5.音子,phone;语音识别建模时的单位,根据需要可以是音节、音素等,或者是更小的单位;
6.senone,(无中文翻译);银子又可以分为多个状态,如:开始,中间,结束。如果不同音子的同一状态相同,则可合并;而这些不同的状态,就叫做senone。
共振峰、谐波:
直接上图了,


几个大峰(红色)分别是:第一共振峰,第二共振峰,第三共振峰, ……
几个小的峰(蓝色)分别是:第一谐波,第二谐波,第三谐波,……
谐波是声带振动的快慢,谐波越高,基频就越高。
第一共振峰是400-500,第二是1800左右,
开口度最大的发的是a的音。
主成分分析(PCA)降维:
想把一个X矩阵(39×100)变成一个39×10的矩阵U,假如X的秩是10,就可以把X(39×100)分解成39×10,10×10,10×100相乘。即:

因此左乘U的-1次方即可得

就从39×100变成5×100的矩阵了,这个左乘,就是主成分分析。将39维特征分解成5维就够了。
下面由一个图说明如何通过舍去部分几乎为0的值,进行降维。假如该X矩阵为:
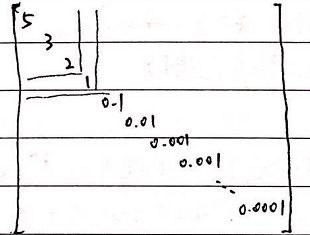
截取占比多的部分,前三个值占比总值有10/11,前四个几乎有100%,因此舍去后面0.1,0.01,0.001……那些占比低的,不会使矩阵包含的信息受损,却可以让维数减少很多,达到提升计算速度的目的。