3.6 BatchNorm 为什么起作用-深度学习第二课《改善深层神经网络》-Stanford吴恩达教授
| ←上一篇 | ↓↑ | 下一篇→ |
|---|---|---|
| 3.5 将 Batch Norm 拟合进神经网络 | 回到目录 | 3.7 测试时的 Batch Norm |
BatchNorm 为什么起作用? (Why does Batch Norm work?)
为什么Batch归一化会起作用呢?
一个原因是,你已经看到如何归一化输入特征值 x x x ,使其均值为0,方差1,它又是怎样加速学习的,有一些从0到1而不是从1到1000的特征值,通过归一化所有的输入特征值 x x x ,以获得类似范围的值,可以加速学习。所以Batch归一化起的作用的原因,直观的一点就是,它在做类似的工作,但不仅仅对于这里的输入值,还有隐藏单元的值,这只是Batch归一化作用的冰山一角,还有些深层的原理,它会有助于你对Batch归一化的作用有更深的理解,让我们一起来看看吧。
Batch归一化有效的第二个原因是,它可以使权重比你的网络更滞后或更深层,比如,第10层的权重更能经受得住变化,相比于神经网络中前层的权重,比如第1层,为了解释我的意思,让我们来看看这个最生动形象的例子。

这是一个网络的训练,也许是个浅层网络,比如logistic回归或是一个神经网络,也许是个浅层网络,像这个回归函数。或一个深层网络,建立在我们著名的猫脸识别检测上,但假设你已经在所有黑猫的图像上训练了数据集,如果现在你要把此网络应用于有色猫,这种情况下,正面的例子不只是左边的黑猫,还有右边其它颜色的猫,那么你的cosfa可能适用的不会很好。

如果图像中,你的训练集是这个样子的,你的正面例子在这儿,反面例子在那儿(左图),但你试图把它们都统一于一个数据集,也许正面例子在这,反面例子在那儿(右图)。你也许无法期待,在左边训练得很好的模块,同样在右边也运行得很好,即使存在运行都很好的同一个函数,但你不会希望你的学习算法去发现绿色的决策边界,如果只看左边数据的话。

所以使你数据改变分布的这个想法,有个有点怪的名字“Covariate shift”,想法是这样的,如果你已经学习了 x x x 到 y y y 的映射,如果 x x x 的分布改变了,那么你可能需要重新训练你的学习算法。这种做法同样适用于,如果真实函数由 x x x 到 y y y 映射保持不变,正如此例中,因为真实函数是此图片是否是一只猫,训练你的函数的需要变得更加迫切,如果真实函数也改变,情况就更糟了。

“Covariate shift”的问题怎么应用于神经网络呢?试想一个像这样的深度网络,让我们从这层(第三层)来看看学习过程。此网络已经学习了参数 w [ 3 ] w^{[3]} w[3] 和 b [ 3 ] b^{[3]} b[3] ,从第三隐藏层的角度来看,它从前层中取得一些值,接着它需要做些什么,使希望输出值 y ^ \hat{y} y^ 接近真实值 y y y 。
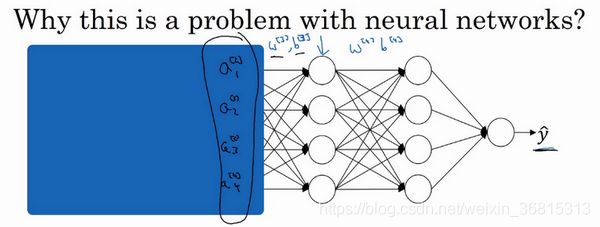
让我先遮住左边的部分,从第三隐藏层的角度来看,它得到一些值,称为 a 1 [ 2 ] , a 2 [ 2 ] , a 3 [ 2 ] , a 4 [ 2 ] a_1^{[2]},a_2^{[2]},a_3^{[2]},a_4^{[2]} a1[2],a2[2],a3[2],a4[2] ,但这些值也可以是特征值 x 1 , x 2 , x 3 , x 4 x_1,x_2,x_3,x_4 x1,x2,x3,x4 ,第三层隐藏层的工作是找到一种方式,使这些值映射到 y ^ \hat{y} y^ ,你可以想象做一些截断,所以这些参数 w [ 3 ] w^{[3]} w[3] 和 b [ 3 ] b^{[3]} b[3] 或 w [ 4 ] w^{[4]} w[4] 和 b [ 4 ] b^{[4]} b[4] 或 w [ 5 ] w^{[5]} w[5] 和 b [ 5 ] b^{[5]} b[5] ,也许是学习这些参数,所以网络做的不错,从左边我用黑色笔写的映射到输出值 y ^ \hat{y} y^ 。

现在我们把网络的左边揭开,这个网络还有参数 w [ 2 ] , b [ 2 ] w^{[2]},b^{[2]} w[2],b[2] 和 w [ 1 ] , b [ 1 ] w^{[1]},b^{[1]} w[1],b[1] ,如果这些参数改变,这些 a [ 2 ] a^{[2]} a[2] 的值也会改变。所以从第三层隐藏层的角度来看,这些隐藏单元的值在不断地改变,所以它就有了“Covariate shift”的问题,上张幻灯片中我们讲过的。
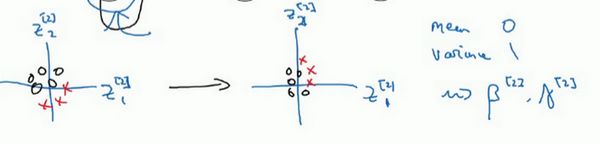
Batch归一化做的,是它减少了这些隐藏值分布变化的数量。如果是绘制这些隐藏的单元值的分布,也许这是重整值 z z z ,这其实是 z 1 [ 2 ] , z 2 [ 2 ] z^{[2]}_1,z^{[2]}_2 z1[2],z2[2] ,我要绘制两个值而不是四个值,以便我们设想为2D,Batch归一化讲的是 z 1 [ 2 ] , z 2 [ 2 ] z^{[2]}_1,z^{[2]}_2 z1[2],z2[2] 的值可以改变,它们的确会改变,当神经网络在之前层中更新参数,Batch归一化可以确保无论其怎样变化 z 1 [ 2 ] , z 2 [ 2 ] z^{[2]}_1,z^{[2]}_2 z1[2],z2[2] 的均值和方差保持不变,所以即使 z 1 [ 2 ] , z 2 [ 2 ] z^{[2]}_1,z^{[2]}_2 z1[2],z2[2] 的值改变,至少他们的均值和方差也会是均值0,方差1,或不一定必须是均值0,方差1,而是由 β [ 2 ] \beta^{[2]} β[2] 和 γ [ 2 ] \gamma^{[2]} γ[2] 决定的值。如果神经网络选择的话,可强制其为均值0,方差1,或其他任何均值和方差。但它做的是,它限制了在前层的参数更新,会影响数值分布的程度,第三层看到的这种情况,因此得到学习。
Batch归一化减少了输入值改变的问题,它的确使这些值变得更稳定,神经网络的之后层就会有更坚实的基础。即使使输入分布改变了一些,它会改变得更少。它做的是当前层保持学习,当改变时,迫使后层适应的程度减小了,你可以这样想,它减弱了前层参数的作用与后层参数的作用之间的联系,它使得网络每层都可以自己学习,稍稍独立于其它层,这有助于加速整个网络的学习。

所以,希望这能带给你更好的直觉,重点是Batch归一化的意思是,尤其从神经网络后层之一的角度而言,前层不会左右移动的那么多,因为它们被同样的均值和方差所限制,所以,这会使得后层的学习工作变得更容易些。
Batch归一化还有一个作用,它有轻微的正则化效果,Batch归一化中非直观的一件事是,每个mini-batch,我会说mini-batch X { t } X^{\{t\}} X{t} 的值为 z [ t ] , z [ l ] z^{[t]},z^{[l]} z[t],z[l] ,在mini-batch计算中,由均值和方差缩放的,因为在mini-batch上计算的均值和方差,而不是在整个数据集上,均值和方差有一些小的噪声,因为它只在你的mini-batch上计算,比如64或128或256或更大的训练例子。因为均值和方差有一点小噪音,因为它只是由一小部分数据估计得出的。缩放过程从 z [ l ] z^{[l]} z[l] 到 z ~ [ l ] \tilde{z}^{[l]} z~[l] ,过程也有一些噪音,因为它是用有些噪音的均值和方差计算得出的。

所以和dropout相似,它往每个隐藏层的激活值上增加了噪音,dropout有增加噪音的方式,它使一个隐藏的单元,以一定的概率乘以0,以一定的概率乘以1,所以你的dropout含几重噪音,因为它乘以0或1。
对比而言,Batch归一化含几重噪音,因为标准偏差的缩放和减去均值带来的额外噪音。这里的均值和标准差的估计值也是有噪音的,所以类似于dropout,Batch归一化有轻微的正则化效果,因为给隐藏单元添加了噪音,这迫使后部单元不过分依赖任何一个隐藏单元,类似于dropout,它给隐藏层增加了噪音,因此有轻微的正则化效果。因为添加的噪音很微小,所以并不是巨大的正则化效果,你可以将Batch归一化和dropout一起使用,如果你想得到dropout更强大的正则化效果。
也许另一个轻微非直观的效果是,如果你应用了较大的mini-batch,对,比如说,你用了512而不是64,通过应用较大的min-batch,你减少了噪音,因此减少了正则化效果,这是dropout的一个奇怪的性质,就是应用较大的mini-batch可以减少正则化效果。
说到这儿,我会把Batch归一化当成一种正则化,这确实不是其目的,但有时它会对你的算法有额外的期望效应或非期望效应。但是不要把Batch归一化当作正则化,把它当作将你归一化隐藏单元激活值并加速学习的方式,我认为正则化几乎是一个意想不到的副作用。
所以希望这能让你更理解Batch归一化的工作,在我们结束Batch归一化的讨论之前,我想确保你还知道一个细节。Batch归一化一次只能处理一个mini-batch数据,它在mini-batch上计算均值和方差。所以测试时,你试图做出预测,试着评估神经网络,你也许没有mini-batch的例子,你也许一次只能进行一个简单的例子,所以测试时,你需要做一些不同的东西以确保你的预测有意义。
在下一个也就是最后一个Batch归一化视频中,让我们详细谈谈你需要注意的一些细节,来让你的神经网络应用Batch归一化来做出预测。
课程PPT

| ←上一篇 | ↓↑ | 下一篇→ |
|---|---|---|
| 3.5 将 Batch Norm 拟合进神经网络 | 回到目录 | 3.7 测试时的 Batch Norm |