pytorch SSD代码解读(1)
SSD总共11个block,网络结构如下
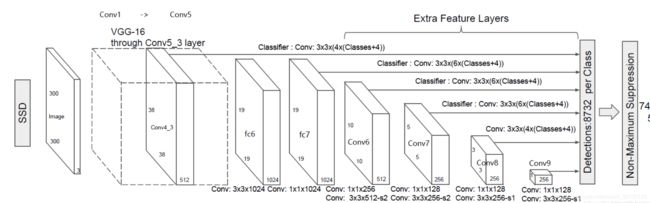

一、主干网络

import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import os
base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512]
# vgg网络
def vgg(i): # i为3,输入的图片是三通道
layers = []
in_channels = i
for v in base:
if v == 'M': # M就是maxpooling
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C': # C就是进行ceil_mode,不足2*2的滤波器也进行maxpooling
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
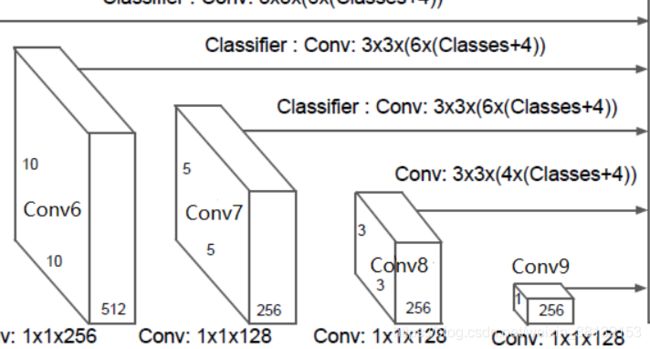
# 额外添加的网络
def add_extras(i, batch_norm=False): # i是1024,FC7输出的是1024维
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
# Block 6
# 19,19,1024 -> 10,10,512
layers += [nn.Conv2d(in_channels, 256, kernel_size=1, stride=1)]
layers += [nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)]
# Block 7
# 10,10,512 -> 5,5,256
layers += [nn.Conv2d(512, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)]
# Block 8
# 5,5,256 -> 3,3,256
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
# Block 9
# 3,3,256 -> 1,1,256
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
return layers
二、特征提取
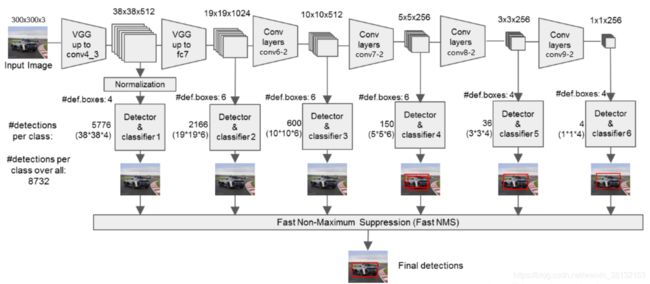
进行分类与回归
我们对conv4_3,FC7,conv6,conv7,conv8,conv9提取出来的特征进行分类与回归
1.把conv4_3,FC7,conv6,conv7,conv8,conv9传出的存放到sources
通过loc_layers,conf_layers,把x的值传进去,得到loc和conf五维张量(loc是一个list,每个元素是一个四维张量),再对loc进行变换
2.我们通过loc.append(l(x).permute(0, 2, 3, 1).contiguous())把loc中的四维张量batch,channel,height,weight --> batch,height,weight,channel,conf同理

3.通过loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)变成[batch,38 * 38 * 16+19 * 19 * 24+……+1 * 1 * 16]=[batch,8732 * 4]
通过loc.view(loc.size(0), -1, 4)输出anchor变成[batch,8732,4],意味着输出8732个先验框和每个先验框的坐标
import torch
import os
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from utils.config import Config
from nets.ssd_layers import Detect
from nets.ssd_layers import L2Norm, PriorBox
from nets.vgg import vgg as add_vgg
class SSD(nn.Module):
def __init__(self, phase, base, extras, head, num_classes):
super(SSD, self).__init__()
self.phase = phase
self.num_classes = num_classes
self.cfg = Config
# nn.ModuleList中的顺序无所谓,网络的执行顺序是根据 forward 函数来决定的,要用for循环实现;nn.Sequential,网络执行的顺序是按照Sequential的顺序执行的
self.vgg = nn.ModuleList(base) # 把vgg网络变成ModuleList类型
self.L2Norm = L2Norm(512, 20)
self.extras = nn.ModuleList(extras)
self.priorbox = PriorBox(self.cfg)
with torch.no_grad():
self.priors = self.priorbox.forward()
self.loc = nn.ModuleList(head[0]) # head = (loc_layers, conf_layers)
self.conf = nn.ModuleList(head[1])
if phase == 'test':
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect(num_classes, 0, 200, 0.01, 0.45)
def forward(self, x):
sources = list() # sources=[]
loc = list()
conf = list()
# 获得conv4_3的内容
for k in range(23): # conv4_3在vgg中是第23层
x = self.vgg[k](x)
s = self.L2Norm(x) # 因为网络比较浅,对输出量进行调整
sources.append(s)
# 获得fc7的内容
for k in range(23, len(self.vgg)): # 共有35层,range(23,35)
x = self.vgg[k](x)
sources.append(x)
# 获得后面的内容
for k, v in enumerate(self.extras):
# 计算forward,每一步用relu激活
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
sources.append(x)
# 添加回归层和分类层
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous()) # batch,channel,height,weight --> batch,height,weight,channel
conf.append(c(x).permute(0, 2, 3, 1).contiguous()) # contiguous是对transpose,permute等进行深拷贝
# 进行resize
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1) # 变成[batch,38*38*16+19*19*24+……+1*1*16]=[batch,8732 * 4]
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == "test":
# loc会resize到batch_size,num_anchors,4
# conf会resize到batch_size,num_anchors,21
output = self.detect(
loc.view(loc.size(0), -1, 4), # anchor变成[batch,8732,4],意味着输出8732个先验框和每个先验框调整坐标
self.softmax(conf.view(conf.size(0), -1,
self.num_classes)), # 变成[batch, 8732, 21],对每一行进行softmax
self.priors
)
else:
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
self.priors
)
return output
def add_extras(i, batch_norm=False):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
# Block 6
# 19,19,1024 -> 10,10,512
layers += [nn.Conv2d(in_channels, 256, kernel_size=1, stride=1)]
layers += [nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)]
# Block 7
# 10,10,512 -> 5,5,256
layers += [nn.Conv2d(512, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)]
# Block 8
# 5,5,256 -> 3,3,256
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
# Block 9
# 3,3,256 -> 1,1,256
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
return layers
mbox = [4, 6, 6, 6, 4, 4] # anchor的数量
def get_ssd(phase, num_classes):
vgg, extra_layers = add_vgg(3), add_extras(1024) # vgg输入维度是3,extras输入维度是1024
loc_layers = []
conf_layers = []
vgg_source = [21, -2] # 对conv4_3和fc7进行回归分类预测
for k, v in enumerate(vgg_source):
# 回归预测
loc_layers += [nn.Conv2d(vgg[v].out_channels,
mbox[k] * 4, kernel_size=3, padding=1)] # 最底层输出4个anchor的坐标,4就是调整参数,对中心和宽和高进行调整
# 分类预测
conf_layers += [nn.Conv2d(vgg[v].out_channels, # mbox * num_classes就是每个anchor所属的类别
mbox[k] * num_classes, kernel_size=3, padding=1)]
for k, v in enumerate(extra_layers[1::2], 2): # 对extra层隔两个取一个层出来,2的作用是k从2开始
loc_layers += [nn.Conv2d(v.out_channels, mbox[k]
* 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, mbox[k]
* num_classes, kernel_size=3, padding=1)]
# 得到loc_layers和conf_layers五维张量(loc_layers是一个list,每个元素是一个四维张量),再对loc_layers进行变换
SSD_MODEL = SSD(phase, vgg, extra_layers, (loc_layers, conf_layers), num_classes)
print(len(loc_layers))
return SSD_MODEL
s = get_ssd('test',21)
# print(s)
三、anchor的位置及其调整
class PriorBox(object):
def __init__(self, cfg):
super(PriorBox, self).__init__()
self.image_size = cfg['min_dim']
self.num_priors = len(cfg['aspect_ratios'])
self.variance = cfg['variance'] or [0.1]
self.feature_maps = cfg['feature_maps']
self.min_sizes = cfg['min_sizes']
self.max_sizes = cfg['max_sizes']
self.steps = cfg['steps']
self.aspect_ratios = cfg['aspect_ratios']
self.clip = cfg['clip']
self.version = cfg['name']
for v in self.variance:
if v <= 0:
raise ValueError('Variances must be greater than 0')
def forward(self):
mean = []
for k, f in enumerate(self.feature_maps):
x, y = np.meshgrid(np.arange(f), np.arange(f)) # meshgrid相当于第一轮画出来38*38的网格
x = x.reshape(-1) # 第一轮x = [ 0~37 0~37 …… 0~37](38个0~37)
y = y.reshape(-1) # 第一轮y = [ 0 0 0 ... 37 37 37](38个0,38个1,……,38个37)
for i, j in zip(y,x):
f_k = self.image_size / self.steps[k] # 第一轮相当于300/8=38,第二轮300/16=19
# 计算网格的中心
cx = (j + 0.5) / f_k # 求每个网格的中心坐标的x轴,再归一化到[0,1]
cy = (i + 0.5) / f_k
# 每个点cell都会有一大一小两个正方形的anchor,小方形的边长用min_size来表示,大方形的边长用sqrt(min_size*max_size)
# 求小正方形的边
s_k = self.min_sizes[k]/self.image_size
mean += [cx, cy, s_k, s_k]
# 求大正方形的边
# size: sqrt(s_k * s_(k + 1)),但是作者论文中给的计算各层anchor尺寸的方法,但在作者源码中给的计算anchor方法有点差异
s_k_prime = sqrt(s_k * (self.max_sizes[k]/self.image_size))
mean += [cx, cy, s_k_prime, s_k_prime]
# 获得长方形
for ar in self.aspect_ratios[k]: # 第一轮会有两个长方形,长宽比是2和1/2
mean += [cx, cy, s_k*sqrt(ar), s_k/sqrt(ar)] # 第一轮第一个长方形的长宽比是2:1
mean += [cx, cy, s_k/sqrt(ar), s_k*sqrt(ar)] # 第一轮第二个长方形的长宽比是1:2
# 获得所有的先验框
output = torch.Tensor(mean).view(-1, 4) # 把mean变成4列,变成[8732,4]再还原到0-300的大小
if self.clip:
output.clamp_(max=1, min=0) # 把mean中的值限制在[0,1],小于0变成0,大于1变成1
return output
四、对预测结果解码
decode函数是对先验框解码,得到预测框
def decode(loc, priors, variances): # loc中是偏差信息
boxes = torch.cat(( # 对x先验框进行平移缩放得到预测框 具体操作见https://zhuanlan.zhihu.com/p/60794316
# Gx = Px * d(x) + Px (代码中又乘以一个超参数variances[0]=0.1)
# Gw = Pw * exp(d(w)) (代码中又乘以一个超参数variances[1]=0.2)
priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:], # variances=[0.1,0.2]是超参数
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
boxes[:, :2] -= boxes[:, 2:] / 2 # 计算左上角坐标
boxes[:, 2:] += boxes[:, :2] # 计算右下角坐标
return boxes
对置信度进行排序,选出最大的200个,对他们进行nms,最大的置信度与后面的iou大于阈值则舍弃,保留小于阈值的,将剩余的锚点框再次循环,即keep中保留的anchor编号为最终输出的锚点框,count为保留的anchor数量。
def nms(boxes, scores, overlap=0.5, top_k=200):
keep = scores.new(scores.size(0)).zero_().long()
if boxes.numel() == 0:
return keep
x1 = boxes[:, 0] # 左上角x
y1 = boxes[:, 1] # 左上角y
x2 = boxes[:, 2] # 右下角x
y2 = boxes[:, 3] # 右下角y
area = torch.mul(x2 - x1, y2 - y1) # 框的面积
v, idx = scores.sort(0) # 升序排序
idx = idx[-top_k:] # 取得最大的top_k个置信度对应的index
xx1 = boxes.new()
yy1 = boxes.new()
xx2 = boxes.new()
yy2 = boxes.new()
w = boxes.new()
h = boxes.new()
count = 0
while idx.numel() > 0:
i = idx[-1]
keep[count] = i
count += 1
if idx.size(0) == 1:
break
idx = idx[:-1] # 取出置信度最大的锚点框的index
torch.index_select(x1, 0, idx, out=xx1)
torch.index_select(y1, 0, idx, out=yy1)
torch.index_select(x2, 0, idx, out=xx2)
torch.index_select(y2, 0, idx, out=yy2)
xx1 = torch.clamp(xx1, min=x1[i])
yy1 = torch.clamp(yy1, min=y1[i])
xx2 = torch.clamp(xx2, max=x2[i])
yy2 = torch.clamp(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
w = torch.clamp(w, min=0.0)
h = torch.clamp(h, min=0.0)
inter = w*h
rem_areas = torch.index_select(area, 0, idx) # 计算这个锚点框与其余锚点框的iou
union = (rem_areas - inter) + area[i]
IoU = inter/union
idx = idx[IoU.le(overlap)] # 排除大于阈值的锚点框
return keep, count
1.创建output来保存最终结果,其shape为[batch,num_classes,top_k,5]。2.conf_data的shape是[batch,8732,21],为了计算变成[batch, 21, 8732]
3.由于网络预测出来的位置预测结果,并不是真正的坐标,需要对先验框解码获得预测框
4.对每个类别进行单独计算(不包含背景),c_mask 获得得到大于置信度阈值的掩码(元素为true或false),scores得到置信度大于阈值的那些锚点框置信度,boxes得到置信度大于阈值的那些锚点框,因此就获得了大于置信度预测框(包含置信度和坐标)
5.通过nms操作,得到最终输出锚点框的Index,将对应的结果(置信度和坐标)保存在output中。
class Detect(Function):
def __init__(self, num_classes, bkg_label, top_k, conf_thresh, nms_thresh): # Detect(num_classes, 0, 200, 0.01, 0.45)
self.num_classes = num_classes
self.background_label = bkg_label
self.top_k = top_k
self.nms_thresh = nms_thresh # 非极大值抑制阈值
if nms_thresh <= 0:
raise ValueError('nms_threshold must be non negative.')
self.conf_thresh = conf_thresh # 置信度阈值
self.variance = Config['variance']
def forward(self, loc_data, conf_data, prior_data): # [batch,8732,4],[batch,8732,21],[8732,4]
loc_data = loc_data.cpu()
conf_data = conf_data.cpu()
num = loc_data.size(0) # batch size的大小
num_priors = prior_data.size(0) # 8732个框
output = torch.zeros(num, self.num_classes, self.top_k, 5) # top_k表示最多取top_k个锚点框进行输出,论文中值为200;5表示[置信度,左上角x,左上角y,右下角x,右下角y]
conf_preds = conf_data.view(num, num_priors,
self.num_classes).transpose(2, 1) # 变成[batch, 21, 8732]
# 对每一张图片进行处理
for i in range(num):
# 对先验框解码获得预测框
decoded_boxes = decode(loc_data[i], prior_data, self.variance) # [8732, 4]
conf_scores = conf_preds[i].clone() # [21, 8732]
for cl in range(1, self.num_classes):
# 对每一类进行非极大抑制
c_mask = conf_scores[cl].gt(self.conf_thresh) # torch.gt(a)函数,大于a设为true,小于a设为false
scores = conf_scores[cl][c_mask] # 得到置信度大于阈值的那些锚点框置信度
if scores.size(0) == 0: # 说明锚点框与这一类的groundtruth不匹配
continue
l_mask = c_mask.unsqueeze(1).expand_as(decoded_boxes) # 扩展成[8732,4],元素都是true和false
boxes = decoded_boxes[l_mask].view(-1, 4) # 得到置信度大于阈值的那些锚点框
# 进行非极大抑制
ids, count = nms(boxes, scores, self.nms_thresh, self.top_k) # 对置信度大于阈值的那些锚点框进行nms,得到最终预测结果的index
output[i, cl, :count] = \
torch.cat((scores[ids[:count]].unsqueeze(1),
boxes[ids[:count]]), 1) # [置信度,左上角x,左上角y,右下角x,右下角y]
return output