统计学习方法逻辑斯蒂回归
逻辑斯谛回归(logistic regression) 是统计学习中的经典分类方法。 最大熵是概率模型学习的一个准则, 将其推广到分类问题得到最大熵模型(maximum entropy model) 。逻辑斯谛回归模型与最大熵模型都属于对数线性模型。本文只介绍逻辑斯谛回归。
设X是连续随机变量, X服从Logistic distribution,
分布函数: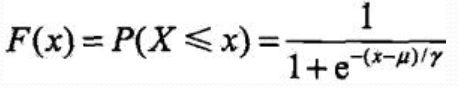
密度函数:
μ为位置参数, γ大于0为形状参数, (μ,1/2)中心对称

Sigmoid:


双曲正切函数(tanh):

二项逻辑斯蒂回归
Binomial logistic regression model
由条件概率P(Y|X)表示的分类模型
形式化为logistic distribution
X取实数, Y取值1,0
事件的几率odds: 事件发生与事件不发生的概率之比为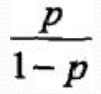 称为事件的发生比(the odds of experiencing an event),
称为事件的发生比(the odds of experiencing an event),
对数几率:
对逻辑斯蒂回归:
似然函数
logistic分类器是由一组权值系数组成的, 最关键的问题就是如何获取这组权值, 通过极大似然函数估计获得, 并且
Y~f(x;w)
似然函数是统计模型中参数的函数。 给定输出x时, 关于参数θ的似然函数L(θ|x)(在数值上) 等于给定参数θ后变量X的概率: L(θ|x)=P(X=x|θ)
似然函数的重要性不是它的取值, 而是当参数变化时概率密度函数到底是变大还是变小。
极大似然函数: 似然函数取得最大值表示相应的参数能够使得统计模型最为合理。
那么对于上述m个观测事件, 设
其联合概率密度函数, 即似然函数为:
目标: 求出使这一似然函数的值最大的参数估, w1,w2,…,wn,使得L(w)取得 最大值。
对L(w)取对数。
对数似然函数
对L(w)求极大值, 得到w的估计值。
通常采用梯度下降法及拟牛顿法, 学到的模型:
直接上代码吧,w的极大值采用梯度下降法,用的iris的数据集:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
class LogisticsRegression:
def __init__(self):
"""初始化Logistics Regression模型"""
self.coef_ = None
self.intercept_ = None
self._theta = None
def _sigmoid(self, t):
return 1. / (1. + np.exp(-t))
def accuracy_score(self, y_true, y_predict):
"""计算y_true和y_predict之间的准确率"""
assert len(y_true) == len(y_predict), \
"the size of y_true must be equal to the size of y_predict"
return np.sum(y_true == y_predict) / len(y_true)
def fit(self, X_train, y_train, eta=0.01, n_iters=1e4):
"""根据训练数据集X_train, y_train, 使用梯度下降法训练Logistics Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
def J(theta, X_b, y):
'''
损失函数
'''
y_hat = self._sigmoid(X_b.dot(theta))
try:
return np.sum(y*np.log(y_hat) + (1-y)*np.log(1 - y_hat)) / len(y)
except:
return float('inf')
def dJ(theta, X_b, y):
'''
求梯度
'''
return X_b.T.dot(self._sigmoid(X_b.dot(theta)) - y) / len(X_b)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
'''
梯度下降
'''
theta = initial_theta
cur_iter = 0
while cur_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
cur_iter += 1
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta, n_iters)
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict_proba(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果概率向量"""
assert self.intercept_ is not None and self.coef_ is not None, \
"must fit before predict!"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return self._sigmoid(X_b.dot(self._theta))
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self.intercept_ is not None and self.coef_ is not None, \
"must fit before predict!"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
proba = self.predict_proba(X_predict)
return np.array(proba>=0.5, dtype = 'int')
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return self.accuracy_score(y_test, y_predict)
def __repr__(self):
return "LogisticsRegression()"
iris = load_iris()
X = iris.data
y = iris.target
# 二项LogisticsRegression只适用二分类
X = X[y<2, :2]
y = y[y<2]
# # 画出数据
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color="red")
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color="blue")
# plt.show()
def train_test_split(X, y, test_ratio=0.2, seed=None):
"""将数据 X 和 y 按照test_ratio分割成X_train, X_test, y_train, y_test"""
assert X.shape[0] == y.shape[0], \
"the size of X must be equal to the size of y"
assert 0.0 <= test_ratio <= 1.0, \
"test_ration must be valid"
if seed:
np.random.seed(seed)
shuffled_indexes = np.random.permutation(len(X))
test_size = int(len(X) * test_ratio)
test_indexes = shuffled_indexes[:test_size]
train_indexes = shuffled_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = train_test_split(X, y, seed = 888)
log_reg = LogisticsRegression()
log_reg.fit(X_train, y_train)
print('测试集预测准确率:'+ str(log_reg.score(X_test, y_test)))
print('测试集合预测概率:'+ str(log_reg.predict_proba(X_test)))
print('测试集合标签:'+ str(y_test))
print('测试集合预测标签:' + str(log_reg.predict(X_test)))结果:

多项logistic回归
设Y的取值集合为
多项logistic回归模型