京东手机评论文本挖掘与数据分析(Python)
这里写自定义目录标题
- 目的
- 工具
- 爬虫
- 数据预处理
- 数据分析
目的
随着网上购物的流行,各大电商竞争激烈,为了提高客户服务质量,除了打价格战外,了解客户的需求点,倾听客户的心声也越来越重要,其中重要的方式就是对消费者的文本评论进行数据挖掘。
工具
1、Python3.7 + Pycharm
2、Google浏览器
爬虫
1、获取相应的URL
①本文对京东平台的手机进行爬虫,首先进入京东商城,选择一款手机,这里以华为P30为例
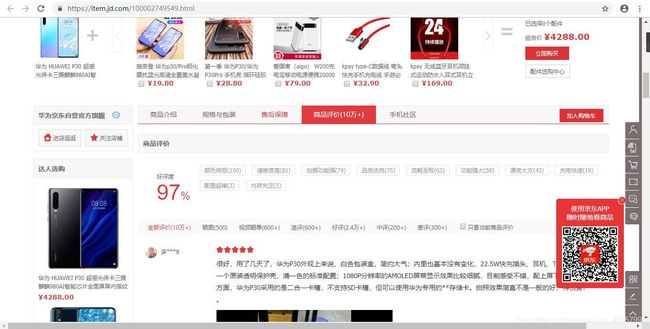
②按下F12,进入开发者工具,选择Network,点击下一页评论,刷新网页,在Name一栏找到productPageComments京东评论所在的数据包,复制Headers这里的URL并保存在一个txt中用于分析,并找到user-agent用于爬取时的浏览器伪装
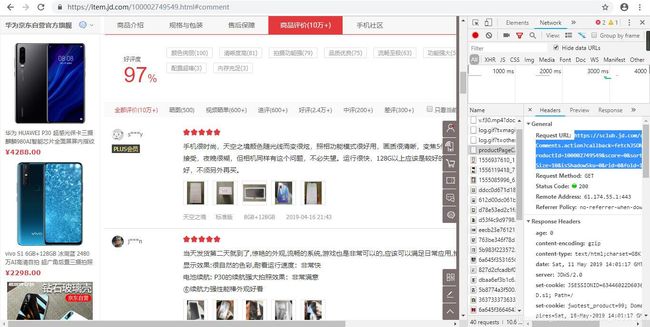
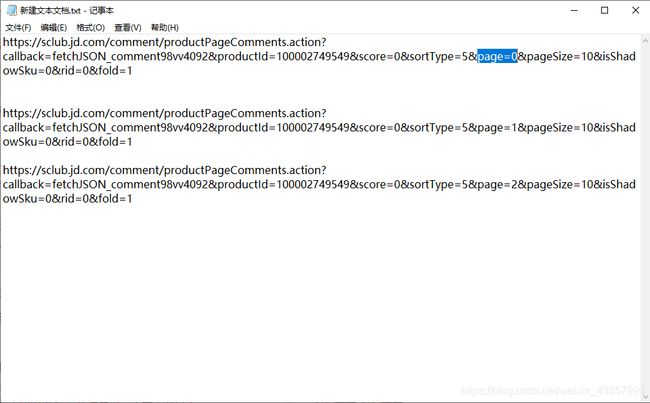
③通过前三页的Request URL可以分析出京东手机每一页的评论都是根据page的增加来获取
④通过preview可以看到评论被服务器放在comments标签下,这里有每一位用户的评论信息,包括用户id、评论时间、产品型号和颜色等等,其中content对应的就是用户评论的内容。这样我们就能通过正则表达式解析出我们需要的内容。

⑤下面我们就通过上面的准备工作,开始爬取数据
import urllib.request
import re
import requests
import time
import random
import json
# 设置请求头
headers = ('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36')
opener = urllib.request.build_opener()
opener.addheaders = [headers]
urllib.request.install_opener(opener)
# 获取URL
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=&productId=100002749549&score=0&sortType=5&pageSize=10&isShadowSku=0&fold=1'
f = open('E:/comments/华为P30.txt', 'w', encoding='utf-8')
for i in range(0, 20):
t = str(time.time()*1000).split('.')
pagram = {
'page': i+1,
'callback': 'fetchJSON_comment98vv4092%s' % (int(t[1])+1)
}
# print(pagram)
# 随机休眠 行为分析
time.sleep(random.random())
# 发送http请求
response = requests.get(url, params=pagram)
# 入库,文件
data = response.text
# 解析数据
data = re.findall(r'{.*}', data)[0]
# 格式成字典
data = json.loads(data)
data = data['comments']
comment_data = {}
for item in data:
comment_data['手机型号'] = item['referenceName']
comment_data['昵称'] = item['nickname']
comment_data['评论内容'] = item['content']
f.write('手机型号:'+item['referenceName']+'\n'+'昵称:'+item['nickname']+'\n'+'评论内容:'+item['content']+'\n')
f.close()
数据预处理
当我们通过爬虫获取到我们想要的数据之后,进行简单的观察,可以发现评论的一些特点:
文本短,基本上大量的评论就是一句话.
情感倾向明显:明显的词汇 如”好” “可以”
语言不规范:会出现一些网络用词,符号,数字等
重复性大:一句话出现词语重复
数据量大.
故我们需要对这些数据进行数据预处理
数据预处理包括:去重、分词等
下面我们将进行数据清洗
import jieba
# 评论内容进行去重
def quchong(infile, outfile):
infopen = open(infile, 'r', encoding='utf-8')
outopen = open(outfile, 'w', encoding='utf-8')
lines = infopen.readlines()
list_1 = []
for line in lines:
if line not in list_1:
list_1.append(line)
outopen.write(line)
infopen.close()
outopen.close()
quchong("E:/comments/华为P30.txt", "E:/comments/P30去重.txt")
# jieba.load_userdict('userdict.txt')
# 创建停用词list
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 对评论内容进行分词
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('stopwords.txt') # 这里加载停用词的路径
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr
inputs = open('E:/comments/P30去重.txt', 'r', encoding='utf-8')
outputs = open('E:/comments/P30分词.txt', 'w')
for line in inputs:
line_seg = seg_sentence(line) # 这里的返回值是字符串
outputs.write(line_seg + '\n')
outputs.close()
inputs.close()
print('分词完毕')
数据分析
上面我们已经通过去重和jieba分词将爬取的内容进行了预处理,接下来就开始对处理过的数据进行分析,包括词频统计、关键词提取以及词云的生成等
# 词频统计
import jieba.analyse
from collections import Counter # 词频统计
with open('E:/comments/P30分词.txt', 'r', encoding='utf-8') as fr:
data = jieba.cut(fr.read())
data = dict(Counter(data))
with open('E:/comments/P30词频.txt', 'w', encoding='utf-8') as fw: # 读入存储wordcount的文件路径
for k, v in data.items():
fw.write('%s, %d\n' % (k, v))
import jieba.analyse
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 生成词云
with open('E:/comments/P30词频.txt') as f:
# 提取关键词
data = f.read()
keyword = jieba.analyse.extract_tags(data, topK=50, withWeight=False)
wl = " ".join(keyword)
# 设置词云
wc = WordCloud(
# 设置背景颜色
background_color = "white",
# 设置最大显示的词云数
max_words=2000,
# 这种字体都在电脑字体中,一般路径
font_path='C:/Windows/Fonts/simfang.ttf',
height=1200,
width=1600,
# 设置字体最大值
max_font_size=100,
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=30,
)
myword = wc.generate(wl) # 生成词云
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('E:/comments/P30.png') # 把词云保存下