【综述论文】Salient Object Detection in the Deep Learning Era: An In-Depth Survey翻译整理
原论文地址:
深度学习时代的显著目标检测:一项深入调查
摘要:图像显著目标检测(SOD)作为计算机视觉中的一个重要问题,近年来引起了越来越多的研究关注。不出所料,SOD的最新进展主要是由基于深度学习的解决方案(称为SOD)主导的,并在数百篇发表的论文中得到了反映。为了促进对SOD的深入理解,在本文中,我们提供了一个全面的综述,涵盖了从算法分类学到尚未解决的开放问题的各个方面。特别地,我们首先从网络结构、监督级别、学习范例和对象/实例级别检测等不同角度对深度SOD算法进行了综述。在此基础上,总结了现有的SOD评价数据集和评价指标。然后,在前人工作的基础上,精心编制了一份详尽的SOD方法基准测试结果,并对比较结果进行了详细的分析。此外,我们通过构建一个具有丰富属性标注的新型SOD数据集,研究了SOD算法在不同属性下的性能,这些属性以前几乎没有被探索过。进一步分析了深度SOD模型的稳健性和可移植性,这在该领域尚属首次。对抗性攻击。我们还考察了输入扰动的影响,以及现有SOD数据集的泛化和硬性。最后,讨论了SOD研究中存在的几个问题和挑战,并指出了今后可能的研究方向。所有显著性预测地图、我们构建的带注释的数据集以及用于评估的代码都在以下网址公开提供
1引言
显著性检测(SOD)的目的是突出图像中视觉上显著的对象区域,它是由各个领域中广泛的对象级应用驱动和应用的。在计算机视觉中,代表性应用包括图像理解[1]、[2]、图像字幕[3]-[5]、对象检测[6]、[7]、无监督视频对象分割[8]、[9]、语义分割[10]-[12]、人物重新识别[13]、[14]、视频摘要[15]、[16]等。[21]机器人学中的示例应用,如人-机器人交互[22]、[23]和对象发现[24]、[25]也受益于SOD以实现更好的场景/对象理解。
与源于认知界和心理学研究界的注视预测(FP)不同,近年来随着深度学习技术的复兴,SOD有了显著的改善,多亏了强大的表征学习方法。自2015年[26]-[28]首次引入以来,基于深度学习的SOD(或Deep SOD)算法很快显示出优于传统解决方案的性能,并继续位居各种基准排行榜的榜首。另一方面,数百篇关于深度SOD的研究论文已经发表,这使得它对于有效理解最先进的技术来说并不是微不足道的。
本文对深度学习时代的SOD进行了全面、深入的调查。它的目标是彻底涵盖深度SOD的各个方面和相关问题,从算法分类到未解决的开放问题。除了对现有的深层SOD方法和数据集进行分类回顾外,它还研究了一些关键但在很大程度上未被探索的问题,如SOD中属性的影响,以及深层SOD模型的鲁棒性和可移植性。对抗性攻击。对于这些新颖的研究,我们构建了一个新的数据集和注释,并在以往研究的基础上推导出基线。所有显著性预测地图、我们构建的带注释的数据集以及用于评估的代码都在以下网址公开提供。
1.1历史和范围
人类能够快速地将注意力分配到视觉场景中的重要区域。理解和模拟这种惊人的能力,即视觉注意或视觉显著,是心理学、神经生物学、认知科学和计算机视觉的基础研究问题。视觉显著性的计算模型有两类,即固定预测(FP)和显著目标检测(SOD).FP起源于认知界和心理学研究界[50]-[52],即在观察场景时预测人的注视点。
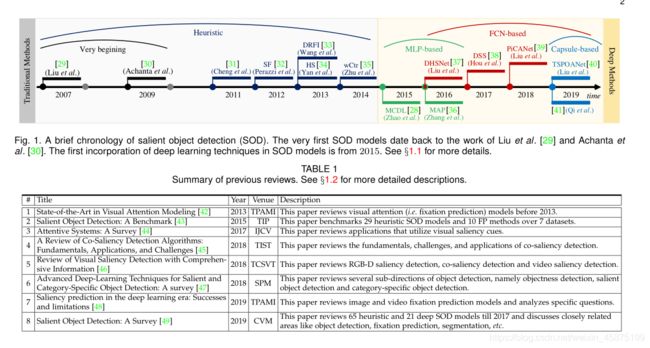
SOD的历史相对较短,可以追溯到[29]和[30]中的开拓性工作。SOD主要是由广泛的对象级计算机视觉应用驱动的。大多数早期的、非深度学习的SOD模型[35]、[53]-[55]都是基于低级特征并依赖于某些启发式方法(例如,颜色对比度[31]、背景先验[56])。为了获得均匀高亮的显著对象和清晰的对象边界,通常将生成区域[57]、超像素[58]、[59]或对象建议[60]的过分割过程集成到上述模型中。有关全面概述,请参阅[43]。
自2015年以来,随着深度学习技术在计算机视觉领域取得的令人瞩目的成功,越来越多的基于深度学习的SOD方法如雨后春笋般涌现出来。早期的深层SOD模型通常利用多层感知器(MLP)分类器来预测从每个图像处理单元[26]-[28]提取的深层特征的显著分数。最近,一种更有效、更高效的形式,即基于全卷积网络(FCN)的网络,成为SOD体系结构的主流。随后,在SOD中引入胶囊[61],以便更好地对对象属性[40]、[62]进行建模。不同的深层模型具有不同的监督水平,可能使用不同的学习范式。特别地,一些SOD方法在所有检测到的显著对象中区分单独的实例[36]、[63]。简略的年表如图1所示。
**调查范围。**尽管对深度显著目标检测的研究历史很短,但已经发表了数百篇论文,这使得回顾所有这些论文是不切实际的(幸运的是,也没有必要)。取而代之的是,我们仔细而彻底地挑选在著名期刊和会议上发表的有影响力的论文。这次调查主要集中在最近五年的主要进展,但为了完整性和更好的可读性,也包括了一些早期的相关著作。值得注意的是,我们将这项调查限制在单个图像对象级别的SOD方法上,而将实例级别的SOD、RGB-D显著性检测、共显著性检测、视频SOD、FP、社会凝视预测等作为单独的主题。本文从网络结构、监管水平、学习范式的影响等多个方面对现有的研究方法进行了分类,这种全面的、多角度的分类将有助于理解以往对深度显著目标检测的研究。更深入的分析在§1.3中总结。
1.2以前相关的回顾和调查
表1列出了与我们的论文密切相关的现有调查。在这些著作中,Borji等人提出了自己的观点。[43]全面回顾2015年前的SOD方法,因此不是指最近基于深度学习的解决方案。张某等人。[45]回顾共分割的方法,共分割是视觉显著性的一个分支,从多于一个相关图像中检测并分割共同和突出的前景。Cong et al.。[46]回顾几个扩展的SOD任务,包括RGB-D SOD、共显著性检测和视频SOD。汉等人。[47]探讨了目标检测的子方向,总结了目标检测、显著目标检测(SOD)和特定类别目标检测的最新进展。Borji等人。总结了视觉显著性的另一个重要分支FP的启发式模型[42]和深层模型[48],并分析了几个特殊问题。Nguyen等人。[44]主要对视觉显著性(包括SOD和FP)在不同领域的应用进行分类。最近发表的一项调查[49]涵盖了传统的非深度方法和直到2017年的深度方法,并讨论了它们之间的关系。其他几个密切相关的研究领域,如特殊目的物体检测、注视预测和分割。
与以往的SOD研究不同,本文对基于深度学习的显著目标检测方法进行了系统、全面的综述。我们的调查的特点是在各个方面进行了深入的分析和讨论,据我们所知,其中许多都是这一领域的首次。特别地,我们总结了现有的基于几种分类的深度SOD方法,通过基于属性的评估加深了对SOD模型的理解,讨论了输入扰动的影响,分析了深度SOD模型的鲁棒性。对抗性攻击,研究现有SOD数据集的概括性和难度,并为基本的开放问题、挑战和未来方向提供见解。我们期待我们的调查能为深入理解SOD提供新的见解和启发,并对提出的诸如SOD的对抗性攻击等公开问题的研究起到启发作用。
1.3我们的贡献
本文的主要贡献如下:1)从不同角度对深层SOD模型进行了系统的综述。我 们从网络结构、监管水平、学习范式等方面对现有的深层SOD模型进行了分类和总结,旨在帮助研究人员更深入地理解深层SOD模型的关键特征。2)提出了一种新的基于属性的深度SOD模型性能评价方法。我们编写了一个混合基准,并提供了考虑对象类别、场景类别和挑战因素的注释属性。我们在此基础上评价了六种流行的SOD模型,并讨论了这些属性对不同算法的影响以及深度学习技术带来的改进。3)关于输入摄动影响的讨论。我们考察了不同类型的扰动对6个典型SOD模型的影响,这是对故意设计的扰动(如对抗性扰动)研究的补充。4)首次对SOD模型进行了对抗性攻击分析。通过精心设计的基线攻击和评估,我们首次对这一问题进行了研究,这可以作为未来深入研究深度SOD模型的稳健性和可移植性的基线。5)跨数据集泛化研究。为了研究SOD数据集[43]中存在的偏差,我们使用具有代表性的基线模型对现有的SOD数据集进行了跨数据集泛化研究。6)有待解决的问题和未来发展方向概述。我们深入研究了模型设计、数据集收集以及SOD与其他主题的关系等几个基本问题,为未来的研究指明了潜在的方向。所有这些贡献带来了详尽的、最新的和深入的调查,并将其与以前的综述论文显著区分开来。论文的其余部分安排如下。§2解释建议的分类法,并相应地进行全面的文献回顾。§3检查最显著的SOD数据集,而§4描述几个广泛使用的SOD度量。§5对几个深度SOD模型进行基准测试,并提供深入的分析。§6提供讨论,并提出该领域的开放问题和研究挑战。最后,§7对本文进行了总结。
2.基于深度学习的SOD模型
在详细回顾最近的深度SOD模型之前,我们首先给出了基于图像的SOD问题的一般表达式。给定尺寸为W×H的输入图像I∈RW×H×3,SOD模型f将输入图像I映射到连续显著图S=f(I)∈[0,1]W×H。
对于基于学习的SOD,模型f是通过一组训练样本来学习的。给定一组N个静态图像I={in∈RW×H×3}Nn=1,并且相应的二进制地面实况注释G={Gn∈{0,1}W×H}Nn=1,学习的目标是找到最小化预测误差的f∈F,即,Pn n=1‘(Sn,Gn),其中’是一定的距离度量(例如,在§4中定义),Sn=f(In),F是潜在映射函数的集合。深度超氧化物歧化酶方法通常通过现代深度学习技术建立f模型,本节将对此进行回顾。基本事实G可以通过不同的方法收集,即直接人工注释或眼睛注视引导标记,并且可以具有不同的格式,即像素或边界框级别,这将在§3中讨论。
在本节的其余部分中,我们将回顾四个分类中的深度SOD方法。我们首先描述SOD的典型网络架构(§2.1)。接下来,我们根据监督级别对SOD方法进行分类(§2.2)。然后,在§2.3中,我们从学习范式的角度来研究SOD方法。最后,根据是否区分不同的对象,将深度SOD方法分为对象级和实例级(§2.4)。我们按类型对重要的模型进行分组,并按大致的时间顺序对它们进行描述。表2提供了所审查模型的综合摘要。
2.1 SOD的典型网络架构
根据采用的主要网络结构,我们将深度SOD模型分为基于多层感知器(MLP)的(§2.1.1)、基于全卷积网络(FCN)的(§2.1.2)、基于混合网络的(§2.1.3)和基于胶囊的(§2.1.4)四类。
2.1.1基于多层感知器(MLP)的方法
如图2(A)所示,基于MLP的方法通常为图像的每个处理单元提取深度特征,以训练用于显著性分数预测的MLP分类器。通常采用的处理单元包括超像素/补丁[28]、[64]、[67]和通用对象建议[26]、[27]、[36]、[75]。1)基于超像素/面片的方法使用规则(面片)或接近规则(超像素)的图像分解。
·MCDL[28]使用两条路径从两个不同大小的以超像素为中心的窗口中提取局部和全局上下文,并将其送入MLP进行前景/背景分类。
·ELD[67]将深度卷积特征和编码的低级距离图(ELD-MAP)连接起来,以构建每个超像素的特征向量。ELD图是使用CNN从所查询的超像素的初始手工制作的特征距离图中生成的。
·MDF[26]使用预先训练的图像分类DNN提取每个图像段的多尺度特征向量。对MLP进行训练以回归段级显著性。最终的地图是每个比例尺的三个地图的组合。

·SuperCNN[64]为每个超像素构造两个手工制作的输入特征序列,由两个CNN列分别进一步处理,以使用1D卷积而不是完全连接的层来产生显著性分数。
2)基于对象建议的方法利用对象建议[26]、[27]或边界框[36]、[75]作为自然编码对象信息的基本处理单元。
·LEGS[27]从像素级深度特征构造段级特征向量,然后使用MLP从段级特征预测显著分数。
·MAP[36]使用CNN模型生成一组评分的边界框,然后选择优化的紧凑型边界框子集作为显著对象。
·SSD[75]首先生成区域建议,然后使用CNN将每个建议分类为具有标准二进制地图的预定义形状类。最后的显著图在所有提案的二进制图上求平均。
2.1.2基于全卷积网络(FCN)的方法
尽管基于MLP的SOD模型的性能优于以往的非深度学习SOD模型和具有深度学习特征的启发式模型,但由于需要逐个处理所有视觉子单元,因此不能很好地捕捉关键的空间信息,并且非常耗时。受全卷积网络(FCN)[118]在语义分割方面的巨大成功的启发,最近的深度SOD解决方案采用流行的分类模型,如VGGNet[119]和ResNet[120],直接输出整体显著图。这样,这些深度SOD解决方案受益于端到端的空间显著性表示学习,并在单个前馈过程中有效地预测显著图。典型的体系结构包括五类:单流网络、多流网络、侧融合网络、自下而上/自上而下网络和分支网络。
1)单流网络是由卷积层、汇聚层和非线性激活操作的顺序级联组成的标准体系结构(参见图2(B))。
·RFCN[77]基于输入图像和来自前一时间步的启发式计算或预测的显著性先验递归地细化显著性预测。展开后可视为级联结构。
·RACDNN[69]使用编解码器流生成粗略的显著图,并逐步细化不同的局部对象区域。它利用空间变换器[121]在每次迭代时关注图像区域以进行细化。
·DLS[81]利用卷积和膨胀的堆栈卷积图层以生成初始显著图,然后在超像素级别对其进行细化。水平集损失函数用于辅助二值分割图的学习。
·UCF[88]使用编码器-解码器架构来产生更高分辨率的预测。它通过解码器中重新制定的丢弃来学习不确定性,并通过在解码器中使用混合上采样方案来避免伪影。
·DUS[94]基于Deeplab[122]算法,该算法是顶部具有膨胀卷积层的FCN。它通过像素级监督从几种启发式显著性方法中学习潜在显著性和噪声模式。
·LICNN[92]通过组合预先训练的图像分类网络的前5个特定类别的关注图来生成“后自组织”显著图。侧向抑制增强了注意图的辨别能力,使其从SOD注释中解脱出来。
·SuperV AE[101]用背景超像素训练变分自动编码器(V AE)。使用每个超像素的重建误差来估计最终的显著图,因为VAE期望以比前景对象的误差更小的误差来重建背景。
**2)如图2©**所示的多流网络通常具有多个网络流,用于从各种分辨率或具有不同结构的输入中显式地学习多尺度显著特征。一些多流网络在不同的路径上处理不同的任务。来自不同流的输出被组合以形成最终预测。
·MSRNet[63]由三个自下而上/自上而下的网络结构流组成,用于处理输入图像的三个缩放版本。这三个输出最终通过一个可学习的注意模块进行融合。
·SRM[87]通过阶段性地将显著特征从较粗的流传递到较细的流来提炼显著特征。每个流的最上面的特征使用地面真实显著对象遮罩进行监督。金字塔合并模块还便于多级显著性融合和细化。
·FSN[85]考虑到显著对象通常获得大部分人的注视[66],将注视流[123]和语义流[119]的输出融合到开始分割模块中以预测显著对象分数。
·HRSOD[114]通过两条自下而上/自上而下的路径捕获全局语义和局部高分辨率细节,分别用于处理整个图像和参与的图像补丁。补丁采样由整个图像的显著结果指导。
·DEF[102]根据顶部的初始显著图将主干中的多尺度特征嵌入到公制空间中。嵌入的特征稍后引导自顶向下路径以阶段性地生成显著地图。3)侧融合网络利用CNN层次固有的多尺度表示,将骨干网络的多层响应融合在一起进行SOD预测(图2(D))。侧面输出通常由地面实况来监督,从而导致深度监督策略[124]。
·DSS[38]增加了几个从较深侧输出到较浅侧输出的短连接。这样,较高级别的特征可以帮助较低的副输出更好地定位显著区域,而较低级别的特征可以帮助用更精细的细节来丰富较高级别的副输出。
·NLDF[82]以自上而下的方式融合多层特征和对比度特征,生成局部显著图,然后将其与顶层产生的全局显著图相结合,生成最终的预测。对比度特征是通过从其平均汇集中减去该特征来获得的。
·Amulet[84]将多级特征聚合为多个分辨率。以自上而下的方式进一步细化多个聚集特征。在最终融合之前,在每个聚集特征处引入边界细化。·DSOS[83]分别使用两个子网来检测显著对象和细分结果。检测子网是具有侧融合的U-Net[125],其瓶颈参数由另一个子网动态确定。
·RADF[89]利用集成的侧面特征来改进自身,并重复这样的过程以逐渐产生更精细的显著性预测。
·RSDNet-R[97]在选通机制下将初始的粗略表示与较早层的较精细特征相结合,以阶段性地精炼侧面输出。来自所有阶段的地图被融合以获得总体显著图。
·CPD[105]将骨干中更深层次的特征进行整合,得到初始显著图,通过整体注意模块生成最终的地图后,用来提炼骨干的特征。
·MWS[107]将来自特征提取器的四个扩张卷积层的四个显著图相加,其被去卷积为输入图像的大小。
·EGNet[113]使用自下而上/自上而下的结构提取多尺度特征,该结构通过向下位置传播增强,然后由显著边缘特征引导进行侧向输出并融合到最终地图中。
4)自下而上/自上而下的网络改进了粗略的显著性估计通过逐步合并来自较低层的空间细节丰富的特征来细化前馈传递中的粗略显著性估计,并在最顶层产生最终地图(参见图2(E))。
·DHSNet[37]通过使用递归层逐步组合较浅的特征来细化粗略显著图。所有的中间地图都受地面事实的监督[124]。
·SBF[86]借鉴了DHSNet[37]的网络结构,但训练是在几种无监督启发式SOD方法提供的弱基础真理下进行的。
·BDMP[93]使用具有各种接收字段的卷积层改进了多层特征,并通过门控双向路径实现了层间消息交换。改进后的特征以自上而下的方式进行融合。
·RLN[95]使用类似初始的模块来净化低级特性。自上而下路径中的循环机制进一步完善了组合特征。通过边界细化网络增强显著性输出。·PAGR[96]通过引入多路径递归连接来将高层语义传递到较低层,从而增强了特征提取路径的学习能力。自上而下的路径嵌入了几个通道空间注意模块,用于提炼特征。
·ASNet[98]在前馈通道中学习粗略的固定图,然后利用一堆ConvLSTM[126]通过合并来自连续较浅层的多层特征来迭代地推断像素方向的显著图。
·PICANet[39]分层地将全局和局部像素级上下文注意模块嵌入到U-Net[125]结构的自上而下路径中。
·RAS[100]在自上而下路径中嵌入反向注意(RA)块,以引导剩余显著学习。RA块使用深层输出的补充来强调非对象区域。
·AFNet[103]使用全局感知器模块全局改进了最显著的特征,并利用注意反馈模块(AFM)在相应的编码器和解码器块之间传递消息。在最后两个AFM中应用了边界增强损耗。
·Basnet[62]首先使用深度监督的自下而上/自上而下结构进行粗略的显著性预测,然后使用另一个自下而上/自上而下的模块来细化显著性图的残差。考虑分层线索的混合损失隐含地有助于准确的边界预测。 ·MLSLNet[106]分层嵌入相互学习模块和边缘模块,每个模块分别由显著性和边缘线索进行深度监督。自下而上和自上而下的路径以交织的方式进行训练。
PAGE-NET[109]为典型的自下而上/自上而下结构配置了金字塔关注模块和边缘检测模块。前者扩大了接受视野,提供了多尺度线索。后者利用显式边缘信息定位并锐化显著对象边界。
·PoolNet[111]从最上面的特征生成全局指导,以指导自上而下路径中的显著对象定位。嵌入在自上而下路径中的特征聚集模块进一步细化融合的特征,从而产生更精细的预测图。
·PS[110]提出了一种迭代的自上而下和自下而上的显著性推理框架。特别地,RNN被用作推理路径的构建块,以迭代地优化静态图像的特征。
·JDFPR[115]在结构的每个级别嵌入CRF块,以从较粗的尺度到较细的尺度联合细化特征和预测地图。CRF块允许特征-特征、特征-预测和预测-预测的消息传递,增强了用于预测的特征。
5)分支网络是一种单输入多输出的结构,底层共享处理公共输入,上层专门处理不同的输出。其核心方案如图2(F)所示。
·SU[72]在分支网络中执行注视预测(FP)和SOD。共享层捕获语义和全局显著上下文。FP分支学习从顶部特征推断注视,而SOD分支聚合侧面特征以更好地保存空间线索。
·WSS[79]由图像分类分支和SOD分支组成。SOD分支受益于在图像级监督下训练的特征,并以自上而下的方式产生初始显著图,该初始显著图通过迭代CRF进行细化,并用于对SOD分支进行微调。
·ASMO[90]与WSS[79]执行相同的任务,也在弱监督下接受培训。主要区别在于ASMO中的共享网络使用多流结构来处理不同比例的输入图像。
·C2S-Net[99]是通过在预先训练的轮廓检测模型(即CEND[127])中添加SOD分支来构造的。这两个分支机构在由彼此提供的监督信号的交替方案下进行训练。
·CapSal[104]包含一个图像捕获子网和一个共享主干的SOD子网,后者由一个局部感知和一个全局感知分支组成,它们的输出被融合以进行最终预测。
·BANET[112]通过在不同的流上处理显著对象的边界和内部来满足不同的特征需求,从而解决了SOD中的选择性-不变性困境[128]。第三个流补充了在两者之间的过渡区域处可能出现的故障。
·SCRN[116]为SOD和边缘检测提取了两个具有共享主干的独立多尺度特征,这些特征由允许在两个任务之间双向消息传递的一组交叉细化单元逐渐细化。
·SSNet[117]由共享特征提取器的语义分割分支和SOD分支组成。前者由图像级标签和细化的伪像素级标签联合监督。后者受到全面监督。

2.1.3基于混合网络的方法
一些深度SOD方法结合了基于MLP和FCN的子网,旨在产生具有多尺度上下文的边缘保持检测(参见图2(G))。
·DCL[68]结合了侧融合FCN流的像素级预测和通过基于深度特征对多尺度超像素进行分类而产生的段级图。这两个分支共享相同的特征提取网络,并且在训练期间交替优化。
·CRPSD[76]还结合了像素级和超像素级显著效果。前者是通过融合FCN的最后和倒数第二个边输出特征来生成的,而后者是通过将MCDL[28]应用于自适应生成的区域来获得的。只有FCN和融合层是可训练的。
2.1.4胶囊化方法
最近,Hinton et al.。[61],[129],[130]提出了一种新型的网络,称为胶囊。胶囊由一组神经元组成,这些神经元接受和输出向量,而不是CNN的标量值,从而允许对实体属性进行全面建模。这种优势激发了一些研究人员探索SOD中的胶囊[40]、41。·TSPOANet[40]强调了两流胶囊网络的部分-对象关系。使用自下而上/自上而下的卷积网络提取胶囊的输入深层特征,将其转换为低层胶囊并分配给高层胶囊,最终识别出显著的或背景的特征。
2.2监督级别
根据是否使用人类标注的显著对象掩模进行训练,深度SOD方法可分为全监督方法和无监督/弱监督方法。
2.2.1全监督方法
大多数深度SOD模型都是使用大规模像素化人类注释进行训练的。但是,对于SOD任务,手动标记大量像素方向的显著性注释非常耗时,并且需要大量密集的人工标记。此外,在精细标记的数据集上训练的模型往往过度拟合,并且对真实图像的泛化能力较差。因此,如何在较少人工标注的情况下训练SOD成为一个日益热门的研究方向。
2.2.2无/弱监督方法
无/弱监督学习是指没有特定任务的基础事实监督的学习。为了摆脱费力的人工标记,一些SOD方法努力使用图像级分类标签[79]、[92]或由启发式非监督SOD方法[86]、[90]、[94]或从其他应用程序[99]、[107]生成的伪像素方式的显著性注释来预测显著性。
**1)分类监管。**结果表明,用图像级标签训练的分层深层特征能够定位包含对象[131]、[132]的区域,这有望为检测场景中的显著对象提供有用的线索。
·WSS[79]首先使用ImageNet[80]预先训练一个双分支网络来预测一个分支上的图像标签,同时估计另一个分支上的显著图。估计的图谱由CRF细化,并用于微调SOD分支。
·LICNN[92]转向ImageNet预先训练的图像分类网络来生成“后自组织”显著图。由于侧向抑制机制,它不需要使用任何其他SOD注释进行显式训练。
·SuperVAE[101]通过感知损失训练超像素VAE,其中学习到的隐藏特征被强制与预先训练的模型一致。2)伪像素级监控。虽然图像级标签信息丰富,但过于稀疏,无法产生精确的像素级显著蒙版。一些研究人员提出利用传统的无监督SOD方法[86]、[90]、[94]、轮廓信息[99]或多源线索[107]来生成噪声显著图,并对其进行细化并用于训练。
·SBF[86]通过融合由几个经典的无监督显著对象检测器[34]、[133]、[134]在图像内和图像间级别产生的弱显著图来生成显著预测。
·ASMO[90]用图像分类标签和启发式无监督SOD方法的噪声映射训练多任务FCN。将前3类激活图[132]的粗显著性和平均图馈入CRF模型,以获得用于微调SOD子网的更精细的图。
·DUS[94]从几种传统的无监督SOD方法[34]、[35]、[135]、[136]生成的噪声显著图中联合学习潜在显著图和噪声模式,并为下一次训练迭代生成更精细的显著图。
·C2S-NET[99]使用CEDN[127]从轮廓[137]生成像素方向的显著对象遮罩,并训练SOD分支。轮廓线和SOD分支交替地彼此更新,并逐步输出更精细的SOD预测。
·MWS[107]从图像分类网络和字幕生成网络学习多源监督下的显著性预测。
2.3学习范式
从不同的学习范式来看,SOD网络可以分为单任务学习方法(STL)和多任务学习方法(MTL)。
2.3.1基于单次提问学习(Single-Task Learning,STL)的方法
在机器学习中,标准方法是一次学习一个任务,即单任务学习[138]。大多数深度SOD方法都属于这一学习范式领域。它们利用来自单个知识域的监督来使用SOD域或诸如图像分类的其他相关域来训练SOD模型[92]。
2.3.1基于多任务学习(Multi-Task Learning)的方法
在机器学习中,标准方法是一次学习一个任务,即单任务学习[138]。大多数深度SOD方法都属于这一学习范式领域。它们利用来自单个知识域的监督来使用SOD域或诸如图像分类的其他相关域来训练SOD模型[92]。
多任务学习(Multi-Task Learning,MTL)[138]受到人类学习过程的启发,即从相关任务中学到的知识可以用来帮助学习一项新的任务,目的是同时学习多个相关的任务。通过引入相关任务额外训练信号中的特定领域信息,提高了模型的泛化能力。任务间的样本共享也缓解了训练重参数模型的数据匮乏问题。
1)突出对象细分[74]。人类快速列举少量项目的能力称为子化[139]。一些SOD方法同时学习显著目标细分和检测。
·MAP[36]首先输出一组与显著对象的数目和位置相匹配的已评分边界框,然后执行基于最大后验的子集优化公式,以联合优化显著对象提案的数目和位置。
·DSOS[83]使用辅助网络学习显著对象细分,通过改变其自适应权层的参数来影响SOD子网。
·RSDNet[97]与上面将显著对象细分显式建模为分类问题的方法不同,它应用一堆显著级别感知的地面真相掩码来训练网络,该网络隐式学习计算出显著对象的数量以及它们的相对显著性。
2)固定预测的目的是对人的注视位置进行预测。由于其与超氧化物歧化酶的密切联系,从这两个紧密相关的任务中学习共享知识有望提高两者的性能。
·SU[72]在分支网络中执行注视预测和SOD。共享层学习捕获语义和全局显著上下文。分支层经过特殊训练,以处理特定于任务的问题。
·ASNet[98]通过联合训练自下而上的路径来预测注视,从而学习SOD。自上而下路径通过结合由注视线索引导的多水平特征来逐步细化对象水平显著性估计。
3)图像分类。图像类别标签可以帮助定位通常包含显著对象候选的区分区域[131]、[132]、[140]。因此,一些方法利用图像类别分类来辅助SOD任务。
·WSS[79]学习用于预测图像类别并估计所有类别的前景地图的前景推理网络(FIN)。FIN与CRFrefined前景图进一步微调,以预测显著图。
·ASMO[90]从传统的无监督SOD方法中学习了在类别标签和伪地面真实显著图的监督下同时预测显著图和图像类别。
4)噪声模式建模从现有启发式无监督SOD方法生成的噪声显著图中学习噪声模式,目的是提取“纯”显著图用于指导SOD训练。
·DUS[94]建议从传统的无监督SOD方法中对有噪监督的噪声模式进行建模,而不是去噪。在统一损耗下,联合优化SOD和噪声模式建模任务。
5)语义分割是从一组预定义的类别中为每个图像像素分配一个标签。SOD可以被视为与类别无关的语义分割,其中每个像素被分类为要么属于显著对象,要么不属于显著对象。高层语义在区分显著对象和背景方面起着重要作用。
·RFCN[77]首先在分割数据集[78]上训练以学习语义,然后在SOD数据集上微调以预测前景和背景图。显著图是这两种图的Softmax组合。
·SSNet[117]通过将所有类别的分割掩码与预测的类别显著性得分进行融合来获得显著性图。显著性聚合模块和分段网络联合训练。
6)轮廓/边缘检测响应于属于对象的边缘而不考虑背景边界,这有助于定位和分割显著对象区域。
·NLDF[82]计算预测边界像素和实际边界像素之间的欠条损失。这一惩罚损失项对更精细的边界有很大贡献。
·C2S-Net[99]对共享底层的等高线和SOD的共同特征进行编码,并在不同的分支上执行这两个任务。前者是对预先训练的模型进行微调,而后者是从头开始训练。
·AFNet[103]在没有显式预测边缘的情况下,计算了从显著图获得的边缘图与地面真实图之间的边界增强损失。
·MLSLNet[106]从连接到编码器路径较浅层的边缘模块输出边缘检测。此外,在解码路径上,轮廓线监督也与显著线索交替使用。
·PAGE-NET[109]分层嵌入边缘检测模块,这些模块被显式训练用于检测显著的对象边界。这种额外的监督强调突出边界对齐。
·PoolNet[111]通过使用高质量的边缘数据集[145]、[146]进行训练以捕获销售对象的更多细节来进一步提高预测性能。
·BANET[112]用边界图监督边界定位流,以强调检测边界时的特征选择性。通过显著图对内部感知流和最终预测进行监督。
·EGNet[113]在最终的显著边缘特征处应用显式边缘监督,从而指导显著特征以更好地分割和定位显著对象。
·SCRN[116]通过在两个特定于任务的特征集之间交换消息来提取边缘检测和SOD这两个任务之间的互补线索,并逐渐细化用于预测的特征。
7)图像字幕可以为学习主要对象的高级语义提供额外的监督。
·CapSal[104]与SOD子网联合训练图片字幕子网。将来自字幕子网的语义上下文与局部和全局视觉提示合并,以提高显著性预测性能。
2.4对象级/实例级SOD
SOD的目标是定位和分割图像中最引人注目的目标区域。如果输出遮罩只表示每个像素的显著性,而不区分不同的对象,则该方法属于对象级SOD方法;否则,它是实例级SOD方法。
2.4.1对象级方法
大多数SOD方法都是对象级方法,即,被设计为检测属于显著对象的像素,而不知道各个实例。
2.4.2实例级方法
实例级SOD方法生成具有不同对象标签的显著掩码,以执行更详细的显著区域解析。实例级信息对于许多需要更精细区分的实际应用程序至关重要。·MAP[36]强调不受约束图像中的实例级SOD。它首先生成大量的候选对象,然后选择排名最靠前的候选对象作为输出。·MSRNet[63]将显著实例检测分解为像素级显著性预测、显著对象轮廓检测和显著实例识别三个子任务。

3.SOD数据集
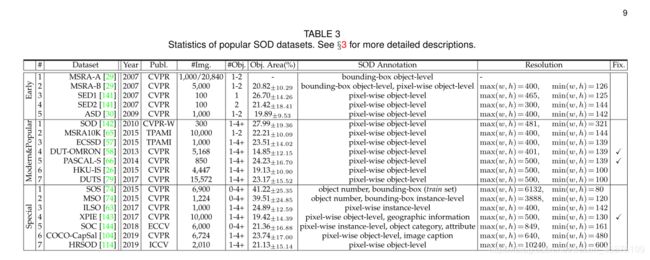
随着SOD的快速发展,大量的数据集被引入。表3总结了19个有代表性的数据集。图3显示了18个可用数据集的注释分布。
3.1早期SOD数据集
早期的SOD数据集通常包含简单的场景,其中1个∼2突出的对象从简单的背景中脱颖而出。
·MSRA-A[29]包含从各种图像论坛和图像搜索引擎收集的20,840张图像。每幅图像都有一个清晰、毫不含糊的对象,相应的注释是由三个用户提供的边界框的“多数协议”。
·MSRA-B[29],作为MSRA-A的子集,有5,000幅图像,由9个用户使用边界框重新标记。与MSRA-A相比,MSRA-B具有更少的w.r.t.歧义。突出的物体。在MSRA-A和MSRA-B上的性能变得饱和,因为大多数图像只包括中心位置附近的单一且清晰的显著对象。
·SED[141]1由单对象子集SED1和双对象子集SED2组成,每个子集包含100个图像,并具有像素级注释。图像中的对象通过各种低级提示(如强度、纹理等)与其周围环境不同。每幅图像由三个对象分割并投票给前景。
·ASD[30]2包含1,000张具有像素级地面真相的图像。图像选自MSRA-A
1.http://www.wisdom.weizmann.ac.il/VISION/SEG评估DB/dl.html
2… https://ivrlwww.epfl.ch/supplementary material/RK CVPR09/DataSet
其中仅提供显著区域周围的边界框。ASD中的精确显著遮罩是基于对象轮廓创建的。
3.2现代流行SOD数据集
最近出现的数据集往往包括具有相对复杂背景的更具挑战性和一般性的场景,并且包含多个显著对象。在这一部分中,我们回顾了七个最流行和使用最广泛的方法。
·SOD[142]3包含来自Berkeley分割数据集的300幅图像[147]。每幅图像都由七个对象进行标记。许多图像具有多个与背景或触摸图像边界具有低颜色对比度的突出对象。可以使用像素方式的注释。
·MSRA10K[65]4,也称为THUS10K,包含从MSRA[29]中选择的10,000个图像,并覆盖ASD[30]中的所有1,000个图像。图像具有一致的边界框标签,并使用像素级注释进一步增强。由于其规模大、标注精确,被广泛用于训练深度SOD模型(参见表2)。
·ECSSD[57]5由1000幅具有语义意义但结构复杂的自然内容的图像组成。地面真相面具由5名参与者注释。
·DUT-OMRON[58]6包含相对复杂背景和高含量变化的5,168幅图像。每幅图像都附有像素级的地面真实注释。
·PASCAL-S[66]7由从PASCAL VOC 2010的VAL集合中选择的850张具有挑战性的图像组成[78]。除了眼睛注视记录之外,还提供像素方式的非二进制显著对象注释,其中像素的显著值被计算为选择包含该像素作为显著的片段的对象的比率。
·HKU-IS[26]8包含4,447个复杂场景,这些场景通常包含多个空间分布相对不同的不连续对象,即至少有一个显著对象触及图像边界。此外,相似的前台/后台外观增加了此数据集的难度。
·DUTS[79]9,最大的SOD数据集,包含10,553个训练图像和5,019个测试图像。从ImageNet Det Train/Val集合[80]中选择训练图像,从ImageNet测试集合[80]和太阳数据集合[148]中选择测试图像。自2017年以来,越来越多的深度SOD模型在DUT的训练集上进行训练(参见表2)。
3.3其他特殊SOD数据集
除了“标准”的SOD数据集之外,最近还提出了一些特殊的数据集,这些数据集有助于捕捉SOD的不同方面,并引导相关的研究方向。
·SOS[74]10是为SOD亚化[139]创建的,即预测显著对象的数量,而无需昂贵的检测过程。它包含从[78]、[80]、[91]、[148]中选择的6900幅图像。每幅图像都被标记为包含0、1、2、3或4+个显著对象。SOS随机分为训练(5520张图像)和测试集(1380张图像)。
·MSO[74]11是覆盖1,224幅图像的SOS测试的子集。它具有更均衡的显著对象数量分布。每个对象都有一个边界框注释。·ILSO[63]12有1,000幅具有像素级实例显著性注释和粗略轮廓标注的图像,其中基准结果是使用MSRNet[63]生成的。大多数ILSO图像选自[26]、[34]、[58]、[74],以减少显著对象区域上的模糊性。
·XPIE[143]13包含10,000张带有明确突出对象的图像,这些图像使用像素级基本事实进行注释。它有三个子集:SET-P包含625幅带有地理信息的名胜图像;SET-I包含8799幅带有对象标签的图像;以及SET-E包括576幅带有眼睛固定注释的图像。
·SOC[144]14有6,000张图像,共80个常见类别。一半的图像包含显著的对象,其他的则不包含。每个包含显著对象的图像都用实例级SOD基本事实、对象类别和挑战因素进行了注释。非显著对象子集具有783个纹理图像和2217个真实场景图像。
·Coco-CapSal[104]15由MS Coco[91]和SALICON[73]构建。利用SALICON中的人的凝视数据对粗略的显著区域进行定位。选择5,265个训练图像和1,459个测试图像以包含其类别被COCO类别覆盖并且与字幕一致的显著区域。最终的显著对象遮罩来自CoCo中的实例遮罩,其凝视注释的IOU得分超过特定阈值。
·HRSOD[114]16是SOD的第一个高分辨率数据集。它包含从网站收集的1610个训练图像和400个测试图像。以像素为单位的地面真相由40名受试者标注。
4.评价方法
有几种方法可以衡量模型预测和人类注释之间的一致性。我们回顾了几种普遍认同和普遍采用的SOD模型评价方法。**·Precision-Recall(PR)**是基于二值化的显著对象掩码和地面事实计算的:

其中Tp、Tn、Fp、Fn分别表示真阳性、真阴性、假阳性和假阴性。应用一组阈值([0−255])将预测二值化。每个阈值产生一对精度/调回值,以形成用于描述模型性能的PR曲线。
·F-MEASURE[30]通过计算加权调和平均值综合考虑精度和召回率:
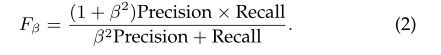
根据经验,β2设置为0.3[30],以更加强调精度。代替报告整个F测量图,一些方法直接使用来自图的最大Fβ值,而另一些方法使用自适应阈值[30],即预测显著图的平均值的两倍,来二值化显著图并报告平均F值。
·平均绝对误差(MAE)[32]。尽管这两个度量很受欢迎,但它们没有考虑到真正的负像素。MAE通过测量归一化地图S∈[0,1]W×手部显著遮罩G∈{0,1}W×H之间的平均像素方向绝对误差来解决此问题:

**· Weighted Fβmeasure (Fbw) ** 通过交替计算准确率和召回率的方法直观地推广了F-测度。它将四个基本量Tp、Tn、Fp和Fn扩展为实值,并考虑邻域信息对不同位置的不同误差赋予不同的权重(ω),定义如下:

**·Structural measure (S-measure) **[150]不是仅处理像素方向的误差,而是评估实值显著图和二进制基本事实之间的结构相似性。S-MEASURE(S)考虑对象感知(SO)和区域感知(SR)结构相似性:
![]()
其中,根据经验将α设置为0.5%。
·Enhanced-alignment measure (E-measure)[151]同时考虑图像和局部像素匹配的全局平均:

其中,φS是增强的对准矩阵,其分别反映在减去S和G的全局平均值之后的相关性。
·Salient Object Ranking (SOR)[97]用于评估显著对象细分中显著对象的排序,其计算为地面真实排序rgG和预测排序rgs之间的归一化Spearman排序相关性:

5基准测试和分析
5.1整体性能基准测试结果
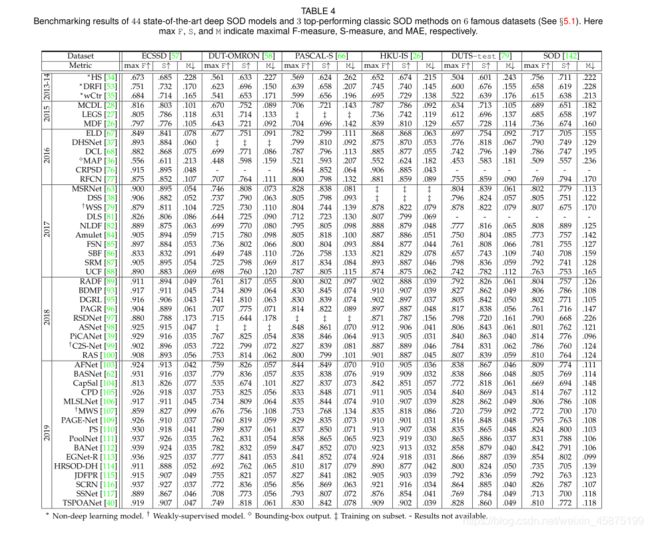
表4显示了44个最先进的深度SOD模型和3个性能最好的经典SOD方法在6个最流行的数据集上的性能。采用最大F-β[30]、S-Measure[150]和MAE[32]三个评价指标来评价像素级显著性预测精度和显著区域的结构相似性。所有47个基准模型都具有代表性,并且在选定的6个数据集上具有公开可用的实现或显著性预测结果。·深V。S。非深度学习。将表4中性能最好的3种启发式SOD方法与深度模型进行比较,我们观察到深度模型在很大程度上一致地提高了预测性能。这证实了深度神经网络具有很强的学习能力。·深度SOD的性能评估。自2015年以来,视觉显著性计算模型的性能随着时间的推移逐渐提高。在深度模型中,2016年提出的MAP[36]性能最差,因为它只输出显著对象的边界框。这表明需要准确的注释以进行更有效的培训和更可靠的评估[30]、[152]。
5.2基于属性的评估
将DNN应用到SOD上已经带来了显著的性能提升,但与前台和后台属性相关的挑战仍然有待克服。在这一部分中,我们将对选定的SOD方法的性能进行详细的基于属性的分析。
5.2.1模型、基准和属性
我们选择了三个性能最好的启发式模型,即HS[34],DRFI[53]和wCtr[35],以及最近著名的三种深度方法,即DGRL[95],PAGR[96]和PICANet[39]执行基于属性的分析。所有的深层模型都是在相同的数据集上训练的,即DUT[79]。
我们从SOD[142]、ECSSD[57]、DUT-OMRON[58]、PASCAL-S[66]、HKU-IS[26]和DUT测试集[79]6个SOD数据集中随机选取1800幅图像作为混合基准。请注意,该基准也将在§5.3和§5.4中使用。
在[66]、[144]、[153]的启发下,我们考虑了突出的对象类别、挑战和场景类别,用一组丰富的属性对每幅图像进行了标注。突出对象分为人、动物、人工制品和NatObj(自然对象),其中NatObj包括水果、植物、山脉、冰山、水(如湖泊、条纹)等自然对象。挑战描述了经常给SOD带来困难的因素,如遮挡、背景群集、复杂形状和对象规模,如表5所总结。图像场景包括室内、城市和自然,后两者表示不同的室外环境。请注意,这些属性并不是互斥的。一些样本图像如图4所示。
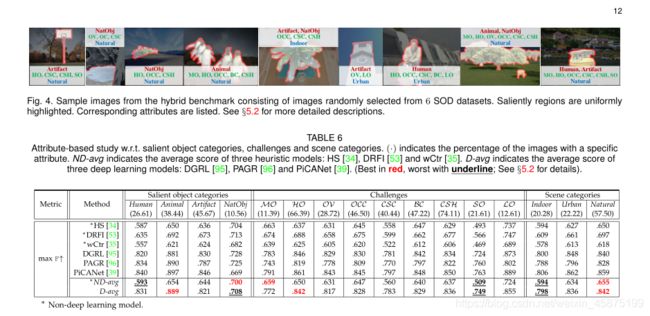

5.2.2分析
**• ‘Easy’ and ‘Hard’ object categories.**深度和非深度SOD模型查看对象类别的方式不同(表6)。对于深度SOD方法,NatObj显然是最具挑战性的方法,这可能是由于训练样本数量较少所致。动物似乎是最容易的,尽管这一部分并不是最大的,主要是因为它的特定语义。相比之下,启发式方法一般擅长分割主导的NatObj,而不擅长分割Human,这可能是由于缺乏高层语义学习造成的。
·最具挑战性和最不具挑战性的因素。表6显示,由于DNN强大的高级语义提取能力,深层方法预测Ho的精度更高。启发式方法对于MO表现良好,因为手工局部特征有助于区分不同对象的边界。由于难以精确标注小尺度对象,深度和非深度方法对SO的性能都较低。
**·最困难和最不困难的场景。**深度方法和启发式方法在面对不同场景时执行类似(表6)。对于这两种方法,自然法是最简单的,这是合理的,因为它占据了一半以上的样本。室内比城市要难,因为前者通常在有限的空间内包含大量物体,而且经常受到高度不均匀的照明的影响。
**·深度模型的其他优势。**首先,如表6所示,深度模型在动物和工件这两个对象类别上取得了很大的改进,显示了其从大量示例中学习的能力。其次,深层模型对不完整的对象形状(HO和OV)不那么敏感,因为它们学习了高级语义。第三,深度模型缩小了不同场景类别之间的差距(室内v.s.。自然),在各种背景下表现出健壮性。
**·顶部和底部预测。**从表7可以看出,启发式方法对混合自然对象(NatObj)比对人类执行得更好。相反,除了动物,深层方法似乎还受到NatObj的影响。对于挑战因素,深度方法和启发式方法在处理复杂场景(CSC)和小对象(SO)时都会遇到问题。最后,启发式方法在室外场景(即城市场景和自然场景)上表现最差,而深层方法对室内场景的显著性预测相对较差。

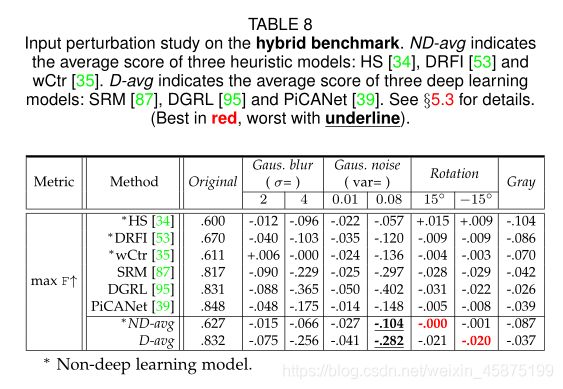
5.3输入扰动的影响
模型的稳健性在于它对被破坏的输入的稳定性。随机扰动的图像(例如带有加性噪声或模糊的图像)可能会导致较差的输出。另一方面,最近出现的敌意例子,即恶意构造的欺骗训练模型的输入,会显著降低深度图像分类模型的性能。在这一部分中,我们分析了一般输入扰动的影响。在§5.4中,我们将研究手动设计的对抗性示例如何影响深度SOD模型。
实验的输入扰动包括高斯模糊、高斯噪声、旋转和灰度。对于模糊,我们使用σ为2或4的高斯核函数来模糊图像。对于噪声,我们选择两个方差值,即0.01和0.08来覆盖微小和中等幅度。对于旋转,我们分别将图像旋转为+15◦和−15◦,并剪切出具有原始纵横比的最大方框。利用Matlabrgb2灰度函数生成灰度图像。
与§5.2中一样,我们选择了三个流行的启发式模型[34]、[35]、[53]和三个深度方法[39]、[87]、[95]来研究输入扰动的影响。表8显示了结果。总的来说,与深度方法相比,启发式方法对输入扰动的敏感度较低,这在很大程度上是由于手工超像素级特征的鲁棒性。具体地说,启发式方法很少受旋转的影响,但对强高斯模糊、强高斯噪声和灰度效应的性能较差。深层方法最容易受到高斯模糊和强高斯噪声的影响,这严重影响了浅层接收场的信息质量。由于要素等级中的空间池化,深层方法对旋转具有相对鲁棒性。
5.4对抗性攻击分析
DNN模型在包括SOD在内的各种任务中都取得了优异的性能。然而,现代DNN被显示出令人惊讶地容易受到对抗性攻击,在这种攻击中,输入的视觉上不可察觉的扰动不是很明显图像会导致完全不同的预测[154]。尽管人们在分类任务中对SOD进行了深入的研究,但对SOD中的敌意攻击的研究却明显不足。
在这一部分中,我们通过对三个有代表性的深度模型进行对抗性攻击来研究深度SOD方法的鲁棒性。我们还分析了针对不同SOD模型的对抗性实例的可移植性。我们期望我们的观察能够揭示SOD的敌意攻击和防御,并有助于更好地理解模型漏洞。
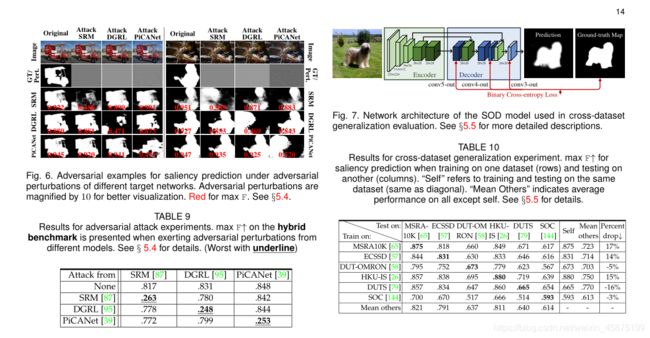
5.4.1 SOD对敌方攻击的健壮性
我们选择了三个有代表性的深度模型,即SRM[87]、DGRL[95]和PICANet[39]来研究其对对手攻击的鲁棒性。所有这三个模型都是在DUT上进行训练的[79]。我们使用这三种型号的ResNet[120]主干版本进行实验。实验在§5.2中介绍的混合基准上进行。
由于SOD可以被视为具有两个预定义类别的语义分割的特例,因此我们求助于针对语义分割而设计的敌意攻击算法-密集对手生成(DAG)[155],来衡量深层SOD模型的鲁棒性。
示例性对抗性案例如图6所示。量化结果如表9所示。可以看出,小的对抗性扰动会导致所有三种模型的性能急剧下降。与随机施加的噪声相比,这种对抗性的例子往往会导致更差的预测(参见表8和表9)。
5.4.2 跨网络传输能力
可转移性是指针对一个模型生成的敌意示例无需任何修改即可误导另一个模型的能力[156],广泛用于针对现实系统的黑盒攻击。有鉴于此,我们通过攻击一个模型来分析SOD的可转移性,利用为另一个模型生成的对抗性扰动来攻击另一个模型。
表9显示了所研究的3个模型(SRM[87]、DGRL[95]和PICANet[39])之间的可转移性评估。结果表明,DAG攻击很少在不同的SOD网络之间传输。这可能是因为不同的SOD模型之间攻击的空间分布非常不同。
5.5跨数据集泛化评估
数据集对于训练和评估深层模型非常重要。在这一部分中,我们通过执行交叉数据集分析[157]来研究几个主流SOD数据集的泛化和难易程度,即在一个数据集上训练一个具有代表性的简单SOD模型,并在另一个数据集上对其进行测试。
简单的SOD模型被实现为流行的自下而上/自上而下的体系结构,其中编码器部分借用VGG16[119],而解码部分由三个卷积层组成,用于逐步做出更精确的像素级显著性预测。为了提高输出分辨率,将第4块中的最大合并层的步长减少到1,将第5卷积块的扩张率修改为2,并且排除了pool5层。侧面输出由Sigmoid激活的Conv(1×1,1)层获得,并受到深度监控。最终的MAP来自第三层解码器层。见图7。
对于这项研究,我们选择了六个有代表性的数据集[26],[57],[58],[65],[79],[144]。对于每个数据集,我们用800个随机选择的训练图像来训练SOD模型,并在另外200个验证图像上进行测试。请注意,考虑到选定的最小数据集ECSSD[57]的大小,1,000是可能的最大总数。
表10总结了使用最大F进行跨数据集泛化的结果。每一列都显示了在一个数据集上测试的所有训练模型的性能,表明了测试数据集的硬度。每一行显示了一个训练模型在所有数据集上的测试性能,表明了训练数据集的泛化能力。我们发现SOC144是最困难的数据集15(最低列意味着其他0.619)。这可能是因为与其他数据集相比,SOC[144]被收集为具有独特的位置分布,并且可能包含极大或极小的显著对象。MSRA10K[65]似乎是最简单的数据集(最高列平均其他0.811),并且概括了最差的数据集(最高行百分比下降17%)。DUTS[79]的泛化能力最好(最低行百分比下降−为16%)。
6讨论
6.1模型设计
在下文中,我们讨论了SOD模型设计的几个重要因素和方向。
**·功能聚合。**分层深层特征的有效聚集对于像素级的标记任务是非常重要的,因为它被认为有利于集成“多尺度”的抽象信息。现有的SOD方法带来了多种特征聚合策略,如多流/多分辨率融合[63]、自上而下自下而上融合[37]或边输出融合[38]、[84]、[89]。与来自其他领域的特征(例如固定预测)的融合也可以增强特征表示[85]。它还有望借鉴其他密切相关的研究任务的特征聚合方法,如语义分割[158]-[160]。
**·损失函数。**损失函数的精心设计对于训练更有效的模型也起着重要作用。在[98]中,从SOD评估度量导出的损失函数被用于捕获质量因素,并且已经被经验证明可以提高显著性预测性能。最近的其他工作[62],[161]建议直接优化平均交集超过并集损失。设计合适的SOD损失函数是进一步提高模型性能的重要考虑因素。
**·网络拓扑。**网络拓扑决定了直接影响训练难度和参数使用的网内信息流,例如各种跳跃连接设计[120]、[162]。作为证据,对于相同的SOD方法,使用ResNet[120]作为主干通常比基于VGG[119]的方法获得更好的性能。除了人工一直向上确定网络拓扑之外,一个很有前途的方向是自动机器学习(AutoML),它的目标是在尽可能少的人工干预下找到性能最好的算法。例如,神经体系结构搜索(NAS)[163]能够从头开始为图像分类和语言建模生成具有竞争力的模型。现有的设计良好的网络拓扑结构和AutoML技术都为构建未来新颖有效的SOD体系结构提供了新的思路。
**·动态推理。**DNN特征之间的丰富冗余有利于其对扰动输入的鲁棒性,但在推理过程中不可避免地引入额外的计算代价。除了使用诸如核分解[164]或参数修剪[165]之类的一些静态方法之外,一些研究还研究在测试期间通过选择性地激活网络的一部分[166]、[167]或执行提前停止[168]来动态改变计算量。与静态方法相比,这些动态方法在不减少网络开销的情况下提高了效率参数,因此容易对基本的对抗性攻击具有健壮性[167]。对于SOD模型的设计,合理有效的动态结构对于提高效率和性能是很有希望的。

6.2数据集集合
**·数据选择偏向。**大多数现有的SOD数据集收集在相对干净的背景中包含显著对象的图像,而丢弃不包含任何显著对象或其背景过于聚集的图像。然而,现实世界中的应用通常会面临更复杂的情况,这会给在这些数据集上训练的SOD模型带来严重的麻烦。因此,创建能够真实反映现实世界挑战的数据集对于提高SOD的泛化能力至关重要[43]。
**·注释不一致。**尽管现有的SOD数据集在训练和评价现代SOD模型方面发挥了重要作用,但不同SOD数据集之间的不一致性也不容忽视。数据集内部的不一致主要是由于在数据集标注过程中独立的主题和规则/条件造成的。参见图8·粗略v.s。很好的注解。对于数据驱动学习,标注质量是训练可靠的SOD模型并对其进行忠实评估的关键。SOD标注质量的第一个改进是用像素掩码代替边界框来表示显著对象[30]、[152],大大提高了SOD模型的性能。然而,像素级标签的精度因数据集而异(参见图8中的自行车)。一些研究集中在精细标记的训练数据对模型性能的影响[144],[169],[170]。
**·特定于领域的SOD数据集。**超氧化物歧化酶在自动驾驶汽车、视频游戏、医学图像处理等领域有着广泛的应用。由于视觉外观和语义成分的不同,这些应用中的突显机制可能与传统的自然图像有很大的不同。因此,特定于领域的数据集在某些应用中可能有益于SOD,正如已经在FP for Crowds[171]、网页[172]或在驾驶期间[173]所观察到的那样。
6.3显著性排名和相对显著性
传统上,显著对象通常指场景中最显著的对象或区域。然而,对于具有多个显著对象的图像,这种“简单”定义可能会令人混淆。因此,如何评估共存对象或区域的显著性对于SOD模型的设计和SOD数据集的标注具有重要意义。一种可能的解决方案是使用固定数据[66]对对象或区域的显著性进行排序。另一种解决方案是由几个观察者投票表决多个显著实例的相对显著性[97]。
6.4与固定装置的关系
FP和SOD都与计算机视觉领域中的视觉显著性概念密切相关。FP可以追溯到20世纪90年代早期[52],它的目的是预测人类观众第一眼关注的视点。SoD的历史略短,可追溯到[29]、[30],并尝试识别和分割场景中的显著对象。FP直接来源于认知和心理学领域,而SOD更多的是由对象级应用驱动的“计算机视觉”。由于显著性检测的不同目的,两者生成的显著图实际上是显著不同的。
FP和SOD之间的强相关性在历史[43]、[66]、[174]-[176]中已经被探索过。而只有少数模型同时考虑FP和SOD任务[12]、[66]、[72]、[85]。探索SOD和FP关系背后的理论基础是一个很有前途的方向,因为它有助于更好地理解人类的视觉选择机制。
6.5利用语义改进SOD
语义在高层视觉任务(如语义分割、对象检测、对象类发现等)中起着至关重要的作用。人们已经致力于利用语义信息来简化SOD[77],[117]。除了用分割数据集[77]预先训练SOD模型,或者利用多任务学习来同时训练SOD和语义分割[117]之外,一个有希望的方向是通过拼接[177]或使用激活[178],通过合并某些对象检测方法中所做的分割特征来增强显著性特征。
6.6在无/弱监督的情况下学习SOD
大多数现代深度SOD方法都是在完全监督的方式下训练的,带有过多精细注释的像素级地面真相。然而,构建大规模的SOD数据集成本高、耗时长。因此,在无监督或弱监督的情况下学习SOD具有重要的研究价值和实际应用价值。虽然已经做了一些努力,即求助于类别级标签[79]、[92]、[101],利用伪像素级标注[86]、[90]、[94]、[99]、[107],但在完全监督的标注方面仍有很大差距。因此,我们可以期待在未来几年朝着这个方向进行的一系列创新。
6.7在实际场景中应用SOD
DNN通常被设计成深度和复杂的,以增加模型的容量,并在各种任务中取得更好的性能。然而,为了满足机器人、自动驾驶、增强现实等移动和嵌入式应用的需求,需要更精巧、更轻量级的网络体系结构,并希望将由于模型尺度推导而导致的精确度和泛化能力的降低降至最低。为了便于SOD在现实场景中的应用,利用模型压缩[179]或知识提取[180]、[181]技术来学习具有竞争性预测精度的紧凑、快速的SOD模型是相当有意义的。这样的压缩技术在训练用于目标检测的更快的模型182时,在改进泛化和减轻欠拟合方面显示了有效性。利用这些技术对SOD模型进行快速、准确的显著性预测是值得探索的。
7结论
据我们所知,我们首次对SOD进行了全面的综述,重点介绍了深度学习技术。我们首先从网络结构、监管水平等几个不同的角度对基于深度学习的SOD模型进行了仔细的回顾和整理,然后总结了流行的SOD数据集和评价标准,并对主要的SOD方法进行了深入的性能基准测试。接下来,我们将在基准和基线方面进行新的努力,调查几个以前探索不足的问题。特别地,我们通过编译和注释一个新的数据集并测试几种有代表性的SOD方法来执行基于属性的性能分析。我们还研究了SOD方法的鲁棒性。输入扰动。此外,在超氧化物歧化酶领域,我们首次研究了深度超氧化物歧化酶模型w.r.t的稳健性和可移植性。对抗性攻击。此外,通过跨数据集泛化实验,对现有SOD数据集的泛化能力和难易程度进行了评估。最后,我们对深度学习时代超氧化物歧化酶面临的几个开放问题和挑战进行了展望,并对未来可能的研究方向进行了深入的探讨。
所有用于评估的显著性预测地图、我们构建的数据集、注释和代码都在
上公开提供。综上所述,由于深度学习技术的突飞猛进,超氧化物歧化酶取得了显著的进步,但仍有很大的改进空间。我们期待这项调查能够提供一种有效的方式来了解最新的情况,更重要的是,为未来对SOD的探索提供洞察力。