检测大写字字母
题目:给定一个单词,你需要判断单词的大写使用是否正确。我们定义,在以下情况时,单词的大写用法是正确的:
全部字母都是大写,比如"USA"。
单词中所有字母都不是大写,比如"leetcode"。
如果单词不只含有一个字母,只有首字母大写, 比如 "Google"。
否则,我们定义这个单词没有正确使用大写字母。
示例 1:
输入: "USA"
输出: True
示例 2:
输入: "FlaG"
输出: False
注意: 输入是由大写和小写拉丁字母组成的非空单词。
思路:这道题简单的让我觉得我理解错题目了?是就一个单词吧?单词之间不能有空格吧?不然不是叫句子么?我先去试试题目是不是我想的这样。
可喜可贺,想法正确:
class Solution {
public boolean detectCapitalUse(String word) {
if(word.toLowerCase().equals(word)) return true;
if(word.toUpperCase().equals(word)) return true;
String sub = word.substring(0,1).toUpperCase()+word.substring(1).toLowerCase();
if(sub.equals(word)) return true;
return false;
}
}
果然性能好的人家都是从底层开始写,我这个调用现成大小写api的性能就不那么好了。下面是自己判断的代码:
class Solution {
public boolean detectCapitalUse(String word) {
char first = word.charAt(0);int num = 0;
boolean daxie = first >= 'A' && first <= 'Z' ? true : false;
for (int i = 1; i < word.length(); i++) {
if (word.charAt(i) >= 'A' && word.charAt(i) <= 'Z') num ++;
}
if (daxie && (num == 0 || num == word.length() - 1)) return true;
if (!daxie && num == 0) return true;
return false;
}
}
最长特殊序列1
题目:给定两个字符串,你需要从这两个字符串中找出最长的特殊序列。最长特殊序列定义如下:该序列为某字符串独有的最长子序列(即不能是其他字符串的子序列)。子序列可以通过删去字符串中的某些字符实现,但不能改变剩余字符的相对顺序。空序列为所有字符串的子序列,任何字符串为其自身的子序列。输入为两个字符串,输出最长特殊序列的长度。如果不存在,则返回 -1。
示例 :
输入: "aba", "cdc"
输出: 3
解析: 最长特殊序列可为 "aba" (或 "cdc")
说明:
两个字符串长度均小于100。
字符串中的字符仅含有 'a'~'z'。
思路:讲真,这个题我认认真真看了三遍,然后现在还怀疑我的理解能力:最长子序列?是不是只要两个字符串完全一样,多的那个就是最长子序列?实在看不明白题目了,我去试试吧
试完了,这个题是来搞笑的,鉴定完毕!

就当看了个笑话吧,这个系列的2是个会员加锁题,所以除了佩服出题人没话讲,下一题。
二叉搜索树的最小绝对差
题目:给定一个所有节点为非负值的二叉搜索树,求树中任意两节点的差的绝对值的最小值。
示例 :
输入:
1
3
/
2
输出:
1
解释:
最小绝对差为1,其中 2 和 1 的差的绝对值为 1(或者 2 和 3)。
注意: 树中至少有2个节点。
思路:这个题没有进阶要求,脑残思路:遍历节点存list,然后排序元素间最小差值。别管性能咋样起码实现是可以完美实现的。
写的过程中越看二叉搜索树这个题干,越觉得其实可以不这么麻烦,如果是搜索树肯定要保证唯一性和左小右大的天性。一定是有什么方式判断的,但是我这个第一版还是无脑得了。
无脑解完了,简单粗暴:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int getMinimumDifference(TreeNode root) {
List list = new ArrayList();
getAllNode(root,list);
Collections.sort(list);
int min = Integer.MAX_VALUE;
for(int i = 0;i list){
if(root==null) return;
list.add(root.val);
getAllNode(root.left,list);
getAllNode(root.right,list);
}
}
额,第一版本做出来了可以安心放心的去优化了。刚刚我就说了这个应该是有一定规律的,毕竟这个是二叉查找树。规律就是中间节点在左右节点之间,如果说最小差也会是在中间节点和左右节点之间,所以在方法里设置一个最小值的变量,每次判断一下,遍历的同时就获取了最小差值,如下代码:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
TreeNode pre = null;
int res = Integer.MAX_VALUE;
public int getMinimumDifference(TreeNode root) {
inOrder(root);
return res;
}
public void inOrder(TreeNode root) {
if(root == null) {
return;
}
inOrder(root.left);
if(pre != null) {
res = Math.min(res, root.val - pre.val);
}
pre = root;
inOrder(root.right);
}
}
数组中的K-diff数对
题目:给定一个整数数组和一个整数 k, 你需要在数组里找到不同的 k-diff 数对。这里将 k-diff 数对定义为一个整数对 (i, j), 其中 i 和 j 都是数组中的数字,且两数之差的绝对值是 k.
示例 1:
输入: [3, 1, 4, 1, 5], k = 2
输出: 2
解释: 数组中有两个 2-diff 数对, (1, 3) 和 (3, 5)。
尽管数组中有两个1,但我们只应返回不同的数对的数量。
示例 2:
输入:[1, 2, 3, 4, 5], k = 1
输出: 4
解释: 数组中有四个 1-diff 数对, (1, 2), (2, 3), (3, 4) 和 (4, 5)。
示例 3:
输入: [1, 3, 1, 5, 4], k = 0
输出: 1
解释: 数组中只有一个 0-diff 数对,(1, 1)。
注意:
数对 (i, j) 和数对 (j, i) 被算作同一数对。
数组的长度不超过10,000。
所有输入的整数的范围在 [-1e7, 1e7]。
思路:这个题应该先判断给定的k是不是0,如果是0则判断数组中有多少对相同的数字。如果不是0则将数组中相同的元素去重。毕竟只返回不同的数对的数量。其次的判断其实我个人觉得先排序,然后直接判断数对的另一个是不是存在。。先按照思路写着,其实思路对不对,能不能实现,性能好不好算是三个东西。可能思路对,但是超时不能实现,也可能实现了但是性能贼差。但是想到了先去试试写代码总没错。
嗯,回来了,我每次都觉得把出题人想的挺明白了,显示总能狠狠的打我的脸。气得我脑壳痛!!!!

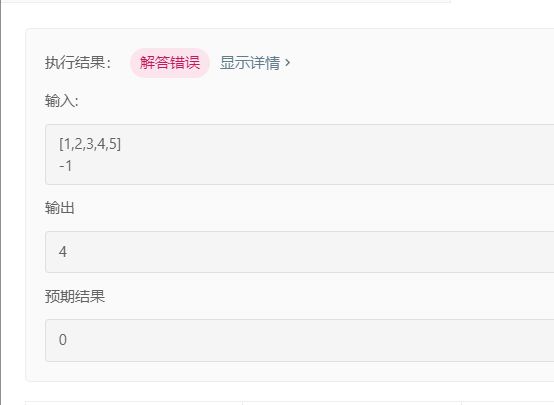
说好了K是差的绝对值,你给我提交个-1,还能怪我错了??????????没办法,胳膊拗不过大腿,我自己做判断吧。
好了,加个对K的判断通过了,分三种情况,大于0小于0等于0.直接上代码:
class Solution {
public int findPairs(int[] nums, int k) {
if(k<0) return 0;
Set set = new HashSet();
Arrays.sort(nums);
if(k==0){
for(int i=0;i 其实也不复杂,最多O(n)的时间复杂度。小于0直接返回,等于0判断一样的个数。大于0判断一对的另一个是否存在。性能超过八十多人,我其实挺满意了,但是顺便看看排名第一的代码:
class Solution {
public int findPairs(int[] nums, int k) {
if(k < 0) return 0;
Arrays.sort(nums);
int start = 0;
int count = 0;
int prev = 0x7fffffff;
for (int i = 1; i < nums.length; i++) {
if(prev == nums[start] || nums[i] - nums[start] > k) {
start++;
if (start != i) {
i--;
}
}else if (nums[i] - nums[start] == k) {
prev = nums[start];
start++;
count++;
}
}
return count;
}
}
得出的结论就是能不调用api就不调用api,能自己写就自己写。我自己都知道我的性能应该在各种contains判断中消耗巨大,但是架不住方便啊。瞻仰完了大神代码,下一题。
把二叉搜索树转换为累加树
题目:给定一个二叉搜索树(Binary Search Tree),把它转换成为累加树(Greater Tree),使得每个节点的值是原来的节点值加上所有大于它的节点值之和。

思路:这里说了是所有大于它的节点值之和。因为是二叉搜索树,所以大于它的节点值的特点就是所有它右边的节点。所以遍历也要按照左->根->右来遍历累加。我去尝试写代码。
emmm。。没写出来,看了题解,原来我跟正确答案就差那么一个思路的转换,只能说看了正确代码恍然大悟,自己写了一两个小时都没思路。直接上代码吧:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
private int sum;
public TreeNode convertBST(TreeNode root) {
if(root==null) return root;
convertBST(root.right);
root.val += sum;
sum = root.val;
convertBST(root.left);
return root;
}
}
要怎么说?其实逻辑很简单,就是严格按照顺序累加?先加右边的,然后左边的。反正我是没想到,只能争取死记硬背下次一看这个类型能有个思路。
反转字符串2
题目:给定一个字符串和一个整数 k,你需要对从字符串开头算起的每个 2k 个字符的前k个字符进行反转。如果剩余少于 k 个字符,则将剩余的所有全部反转。如果有小于 2k 但大于或等于 k 个字符,则反转前 k 个字符,并将剩余的字符保持原样。
示例:
输入: s = "abcdefg", k = 2
输出: "bacdfeg"
要求:
该字符串只包含小写的英文字母。
给定字符串的长度和 k 在[1, 10000]范围内。
思路:额,首先说题目很是复杂啊,看了两三遍才看懂。其次就剩下实现了,反正我个人感觉这种反转字符串的题目。实现和实现的好是完全不同的。而我就是那个能实现但是不见得好的人。接下来去写代码了。
嗯,不出所料的写出来了。不出所料的性能不咋地。这种题目的好出就是不考虑性能的话最笨的办法也可以做出来。直接上代码:
class Solution {
public String reverseStr(String s, int k) {
int len = s.length();
StringBuffer sb = new StringBuffer();
int n = 0;
while(len>2*k){
sb.append(reverse(s.substring(n*k,k*(n+1))));
sb.append(s.substring(k*(n+1),k*(n+2)));
n += 2;
len = len - k*2;
}
if(len如上面代码,我这里用了一个专门的方法 用来反转字符串。然后根据不同的段(比如是处于k之内,k到2k之间,2k到3k之间判断是正序追加还是倒叙追加。)然后下面的是优化一点点的版本:
class Solution {
public String reverseStr(String s, int k) {
int len = s.length();
StringBuffer sb = new StringBuffer();
int i = 0;
while(i*k其实思路没变化,只不过逻辑更加清晰了而已。其实在写的过程中隐约想起来好像做过类似的题目,当时好像是倒叙再倒叙就正了。。不过放在这个题目上还没想好要怎么用。我还是直接看题解吧。
大概上的性能我这里的反转是返回新字符串。而性能好的是在原字符串的基础上反转的。剩下的我这里的反转是从头到尾的遍历。人家的反转是前后位置交换。只能说一看就懂,自己写不出。附上代码瞻仰:
class Solution {
public String reverseStr(String s, int k) {
char[] ch = s.toCharArray();
int n = 0;
for(int i = 0;i二叉树的直径
题目:给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过根结点。

思路:关于这个题是题目,我还不是很理解,是不是说树左右两边最深度的和就是直径?因为接触的少也不知道理解的对不对,我先去写代码试试。
嗯,写完回来了,是我想的太简单了。不仅仅是根节点左右两边的深度和。上个图吧,如图所示红色部分才是直径。所以这个是要递归套递归的,每一个节点都可能是最长直径的根节点。(不要吐槽我话的不标准,能对付看就行了。这个树是根据测试案例画的)

我简直了,,,,对付递归+递归的做出来了,性能只超过百分之十二???哎呦,心疼自己。贴上第一版本代码:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int diameterOfBinaryTree(TreeNode root) {
int max = 0;
if(root!=null){
int left = treeD(root.left,0);
int right = treeD(root.right,0);
if(right>left){
return Math.max(left+right,diameterOfBinaryTree(root.right));
}else{
return Math.max(left+right,diameterOfBinaryTree(root.left));
}
}
return 0;
}
//层数,边数比层数少1
public int treeD(TreeNode root,int d){
if(root==null) return d;
return 1+Math.max(treeD(root.left,d),treeD(root.right,d));
}
}
其实我感觉代码逻辑很清晰,无论是求深度还是选取不同节点当中心点,天晓得大神的代码怎么写的,我自己又看了看,觉得可能是方法中的递归不对。直接看看排行第一的代码吧。
看完回来了,几行代码,改一点不行,改一句不行。本来是看了眼知道思路就努力自己做的,结果测测改改,最后完成版和人家的一样一样的。中间我不想用left,right表示,直接用方法,结果max中和返回值中都用到了,完美的超时了,所以改成这样。除了膜拜还能说什么?
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
private int max = 0;
public int diameterOfBinaryTree(TreeNode root) {
treeD(root);
return max;
}
//层数,边数比层数少1
public int treeD(TreeNode root){
if(root==null) return 0;
int left = treeD(root.left);
int right = treeD(root.right);
max = Math.max(left+right,max);
//这个返回值用于上面的比较
return 1+Math.max(left,right);
}
}
这边笔记就记录到这里吧,之前因为周末整整玩了两天,所以决定这几天要补回来。一天五道题算,emmmm。。继续刷题了,如果稍微帮到你了记得点个喜欢点个关注。也祝大家工作顺顺利利!