hadoop 的核心知识点 01 Hdfs,yarn的原理和执行流程图,以及一些简单的shell操作已经基本的API
Hdfs 原理和构架图
什么是hdfs 概述 以及实际的目标
1,在windows的文件管理系统是NTFS

2,Hadoop的文件管理系统是hdfs
设计理念
HDFS的设计理念源于非常朴素的思想;当数据集的大小超过单台计算机的存储能力时,就有必要将其进行分区并存储到若干台单独的计算机上,而管理网络中跨多台计算机存储的文件系统称为分布式文件系统。该系统架构与网络之上,势必会引入网络编程的复杂性,因此分布式文件系统比普通文件系统更为复杂。
准确地说,Hadoop有一个抽象的文件系统的概念,HDFS只是其中的一个实现
hdfs的特点
1,适合存储超大文件
2,运行于廉价硬件之上
3,易扩展,为用户提供性能不错的文件存储服务
3,流式数据访问
啧啧,缺点来了!!!!
1,实施数据访问弱
2,大量的小文件
3,多用户写入,任意修改文件
来看一下对比哈,下面的是普通系统文件系统设计思路

hdfs的设计思路

ps:(hadoop 2以后的128m)
一个典型的HDFS集群中,有要有一个NameNode,一个SecondaryNode和至少一个DataNode,而HDFS客户端数量并没有限制。所有的数据均存放在运行DataNode进程的节点块(block)里.
那么什么是 datanode ,namenode,secondarynode呢?
DataNode
DataNode被称为数据节点,它是HDFS的主从框架的从角色的扮演者,它在NameNode的指导下完成I/O任务。存放在HDFS的文件都是由HDFS的块组成,所有的块都存放于DataNode节点。实际上,对于DataNode所在的节点来说,块就是一个普通文件,我们可以去DataNode存放块的目录下观察,块的文件名为blk_bklID.
DataNode会不断向NameNode报告。初始化时,每个DataNode将当前存储的块告知NameNode,在集群正常工作时,DataNode任然会不断地的更新NameNode,为之提供本地修改的相关信息,同时接受来自NameNode的指令,创建、移动或者删除本地磁盘上的块。
块的好处
1,可以保存比存储节点单一磁盘大的文件
2,简化存储子系统
3,容错性高
NameNode
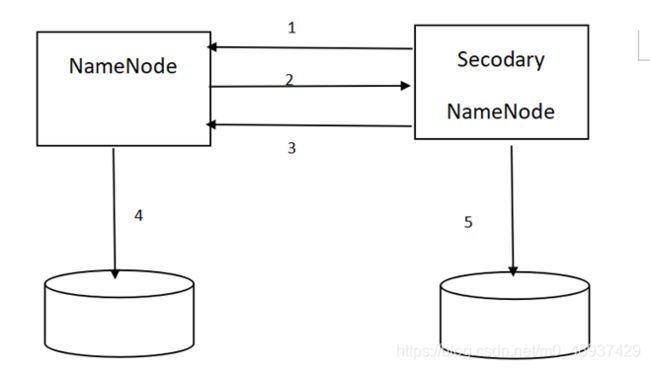
NameNode也被称为名字节点,是HDFS的主从架构的主角色的扮演者。NameNode是HDFS的大脑,它维护着整个文件系统的目录树,以及目录树里所有的文件和目录,这些信息以两种文件存储在本地文件中:一种是命名空间镜像(也称文件系统镜像File System Image,FSImage),即HDFS元数据的完整快照,每次NameNode启动的时候,默认加载最新的FSImage,另一种是命名控件镜像的编辑日志(edit log).
SecondaryNameNode
SecondaryNameNode,也称为第二名字节点,是用于定期合并命名空间镜像和命名空间镜像的编辑日志的辅助守护进程。每个HDFS集群有一个SecondaryNameNode,在生产环境下,一般SecondaryNameNode也会单独运行在一台服务器上.
NameNode和SecondaryNode交互
Hdfs 客户端
hdfs 的客户端是指用户和hdfs 交互的手段,hdfs提供了非常多的客户端,包括命令接口,Java Apl …
hdfs 容错
1,心跳机构
2,检查文件块的完整性
3,集群的负载均衡
4,namenode上的Fsimage 和编辑日志文件
5,文件的删除
yarn的原理和执行流程图

什么是yarn
YARN的全称(Yet Another Resource Negotiator)另一种资源协调者,它是一种统一资源管理和调度平台的实现,类似与本地PC的操作系统
ResourceManager
RM是集中所有资源的管理者,复杂集群中所有资源管理和调度。它定期会接收各个NodeManager的资源汇报信息,并进行汇总,并根据资源使用情况,将资源分配给各个应用的二级调度器(ApplicationMaster)。
在YARN中,RM主要的职责是资源调度,当多个作业同时提交时,RM在多个竞争的作业之间权衡优先级并进行仲裁资源,当资源分配完成后,RM就不关心应用内部的资源分配,也不关注每个应用的状态,这样的话,RM针对每个应用来说,只进行一次资源分配,大大减轻RM负荷,使得其扩展性大大增强
NodeManager
NM是YARN集群中单个节点的代理,它管理YARN集群中的单个计算节点,它负责保存与RM的同步,跟踪节点的健康状况,管理各个Container的生命周期,监控每个Container的资源使用情况,管理分布式缓存,管理各个Container生成的日志,提供不同YARN应用可能需要的辅助服务。其中Container的管理是NM的核心功能,NM可以接收RM和AM的命令来启动或者销毁容器。
NM的组件按照功能主要分为与RM进行交互、容器管理、容器操作、Web界面、删除服务、资源本地话、安全等。
ApplicationManager
YARN架构中比较特殊的组件,生命周期随着应用的开始而开始,结束而结束。
AM是协调集群中应用程序的进程,每个应用程序都有自己专属的AM,不同的计算框架的AM的实现是不同的,它负责向RM申请资源,在对应的NM上启动Container来执行任务,并在应用中不断地监控这些Container的状态。
AM的启动是由RM完成的。当作业被提交后,RM会在集群中任选一个Container,启动作为AM。
由于在作业执行过程中,AM会不断获取执行情况 ,所以用户可以访问AM来查看作业的执行情况。
明白了什么是Hdfs,开始一些简单的基本文件操作以及Hdfs的java api 操作
1,需要切换到sbin 目录下执行hadoop 命令
-help [cmd] :显示命令的帮助信息

-mkdir :创建文件夹

-ls® :显示当前目录下所有文件,path是hadoop 下的路径

-put:本地文件复制到hdfs

如果在上传文件过程中出现以上信息,表示操作hdfs的权限不够,可以在在haoop 配置文件中hdfs-site.xml 中设置权限为false




![]()
-du(s) :显示目录中所有文件大小

-count[-q] :显示目录中文件数量

-mv:移动多个文件到目录

-cp:复制多个文件到目标目录
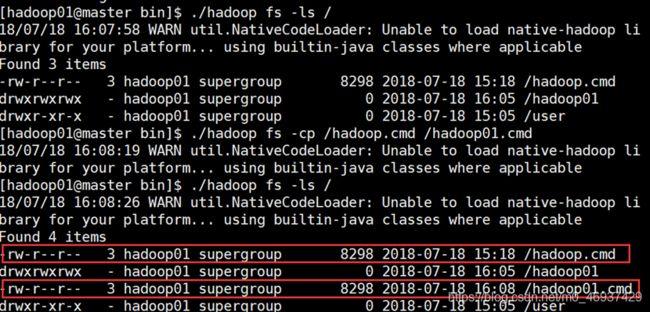
-rm®:删除文件
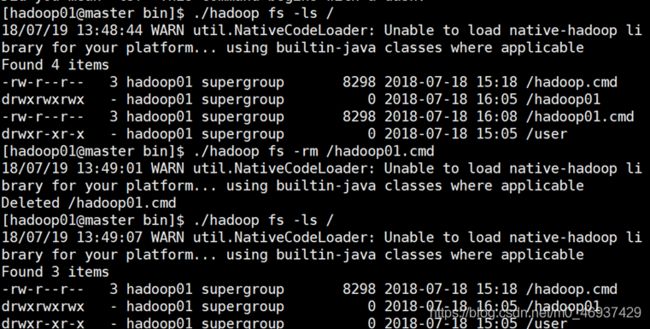
-moveFromLocal /-moveToLocal :从本地文件移动到hdfs/从hdfs把文件移动到本地

-get [-ignoreCrc] :复制文件到本地,可以忽略crc校验
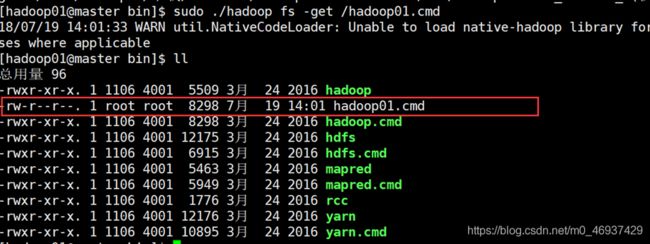
Hdfs的java api操作
处理使用Shell方式操作hdfs,通用软件开发者可以通过一组java api来通过java代码操作hdfs
1,使用eclipse连接hdfs
2,安装插件
在…\eclipse\plugins\导入hadoop插件如图:这些插件可在hadoop原生态安装包中找到。具体在apache官网下载对应版本的hadoop安装包的lib中以及cdh的lib

3,CDH路径导入
弱第二部插件导入成功的话,在下图会显示hadoop Map/Reduce目录
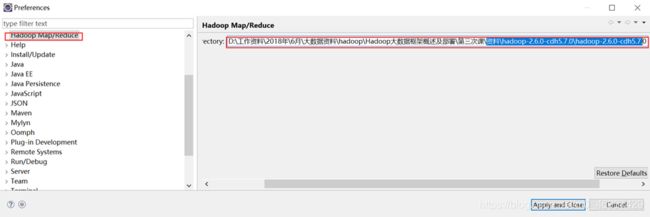
4,配置属性编辑
完成第三步之后左击Window–>Show View–>other–>MapReduce Tools显示右下角文本框,左击最下方CDH–>Edit填写General属性,CDH5自定义sdzn-cdh01为hadoop集群中主节点所在的主机名称,8021、8020为cdh版本的HDFS访问端口,apache版本9001、9000

5,成功连接hdfs

6,使用eclipse操作hdfs
导入hadoop 操作的jar包

8,使用api操作的hdfs
Configuration类
FileSystem类
mkdirs()方法
create()方法
open()方法
rename()方法
copyFromLocalFile()方法
copyToLocalFile()方法
listStatus()方法
delete()方法
- 昨天顺序写反了,·····
- 明天写hive