MutualNet: Adaptive ConvNet via Mutual Learning from Network Width and Resolution论文学习
Abstract
本文提出了宽度-分辨率相互学习的方法(MutualNet),根据动态的资源约束来训练网络,实现运行时自适应的准确率-效率的平衡。该方法利用不同的宽度和输入分辨率,训练了多个子网络,每个网络都互相学习多尺度的特征表示。相对于目前SOTA的自适应网络 US-Net,本文方法在ImageNet上取得了更高的top-1准确率,要比最优的复合尺度的MobileNet和EfficientNet 高 1.5 % 1.5\% 1.5%。在COCO目标检测、实例分割和迁移学习任务上,该方法也进行了验证。MutualNet的训练策略可以提升单个网络的性能,在效率(GPU搜索时间:1500 vs. 0)和准确率(ImageNet: 77.6 % 77.6\% 77.6% vs. 78.6 % 78.6\% 78.6%)方面都显著超过了AutoAugmentation。代码位于:https://github.com/taoyang1122/MutualNet。
1. Introduction
深度神经网络在多项感知任务上都很成功。但是,深度网络通常需要大量的计算资源,很难部署到移动设备和嵌入式平台上。这就促使人们去研究,如何设计出更高效的卷积模块或裁剪掉不重要的网络连接,来降低神经网络中的冗余。但是,这些网络都忽略了一个事实,计算成本由网络的大小和输入的大小决定。只想着降低网络的大小是没法实现最优的准确率-效率平衡的。EfficientNet 已经认识到,平衡网络深度、宽度、分辨率的重要性。但是它只考虑了网络的大小和输入的大小。作者对不同的配置进行了网格搜索,选择最佳的配置,作者认为网络的大小和输入大小应该结合不同配置信息一起来考虑。
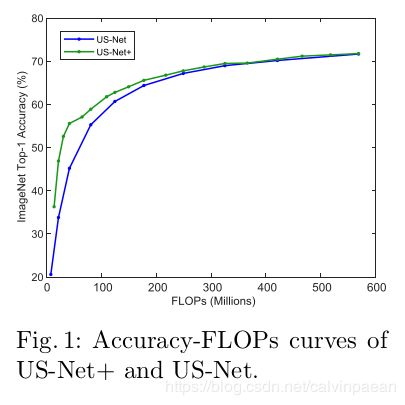

另一个妨碍网络实际部署的问题就是,在不同的应用平台上计算资源是变化的,而传统网络只能运行在特定的资源约束(如FLOPs)下。为了解决这个问题,有人提出了SlimNets,训练单个模型来满足运行时变动的资源预算。他们只降低了网络的宽度,来满足较低的资源预算。结果是,随着计算资源的降低,模型的表现会大幅度下降。这里,作者提供了一个具体例子,证明输入分辨率和网络宽度平衡的重要性,从而实现更优的准确率-效率平衡。为了在MobileNetV1主干网络上满足从13到569 MFLOPs 的动态资源要求,US-Net 在面对输入是 224 × 224 224\times 224 224×224的图片时,所需的网络宽度在 [ 0.05 , 1.0 ] × [0.05, 1.0]\times [0.05,1.0]×,而这个要求也可以在 { 224 , 192 , 160 , 128 } \{224,192,160,128\} {224,192,160,128}的范围内调节输入分辨率,而网络宽度在 [ 0.25 , 1.0 ] × [0.25,1.0]\times [0.25,1.0]×来得到满足。作者将第二个模型叫做US-Net+。如图1所示,推理时我们将不同的分辨率和网络宽度结合,可以实现更优的准确率-效率平衡。
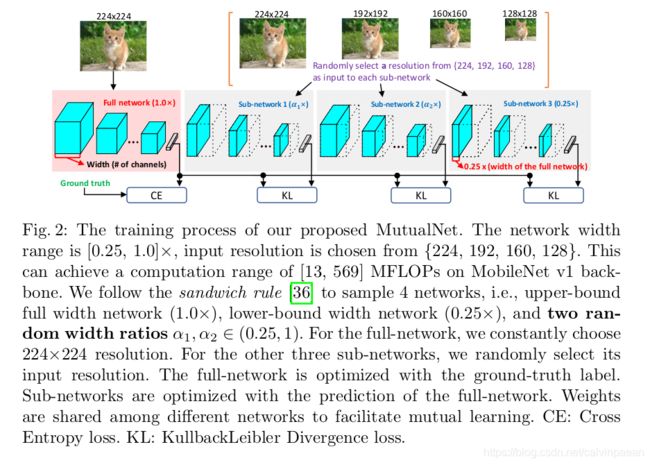
受上述发现启发,作者提出了一个相互学习的方法,将网络宽度和输入分辨率融入到一个统一的学习框架内。如图2所示,该框架的输入是不同输入分辨率的子网络。由于子网络之间共享权重,每个子网络都可以学习其它子网络的知识,从而使它们能够获取网络大小和输入分辨率的多尺度特征表示。表1提供了本文框架和其它方法的比较。总之,本文贡献如下:
- 强调了对于高效率网络设计,输入分辨率的重要性。之前的工作要么忽略了,要么脱离了网络结构而单独来看待它。相反,作者在一个统一的相互学习的框架中加入了网络宽度和输入分辨率信息,学习网络 MutualNet,它可以在准确率-效率之间实现自适应的平衡。
- 作者进行了大量的实验来证明MutualNet的有效性。在不同的资源约束下,在不同的网络结构、数据集、任务上,它都显著超越了单独训练的网络和其它US-Net。本文应该是第一个在目标检测和实例分割任务上对任意约束自适应网络做benchmark的。
- 作者进行了充分的研究,分析相互学习方式。作者进一步证明了该框架可以作为plut-and-play策略,提升单个网络的性能,它超越了流行的性能提升方法,如数据增广, SENet 和知识蒸馏等。
- 该框架是一个通用的训练机制,与模型无关。它可以用在任何的网络上,而无需调整其结构。这就使得它可以和SOTA的技巧兼容(如NAS和AutoAugmentation)。
2. Related Work
轻量级网络。最近人们对设计轻量级网络给予了很多兴趣。MobileNet 将标准的 3 × 3 3\times 3 3×3卷积拆分为 3 × 3 3\times 3 3×3深度卷积和 1 × 1 1\times 1 1×1 pointwise卷积,将计算成本降低了数倍。ShuffleNet 将 1 × 1 1\times 1 1×1卷积分割为分组卷积,进一步提升计算效率。MobileNet V2 为低复杂度网络,提出了倒转残差和线性模块。ShiftNet 引入了 zero-flop shift操作,降低计算成本。[13,32,34] 采用了神经结构搜索方法来搜索高效率模型。但是,它们没有一个考虑到了在现实应用中,运行时不断变化的资源约束。为了满足不同的资源预算,这些方法需要部署多个模型,在它们中切换,扩展性很差。
自适应神经网络。为了满足现实应用中的动态约束,MSDNet 提出了一个多尺度、粗糙的方式来改良DenseNet框架。它有多个分类器,作出预测来满足不同的资源要求。NestedNet 使用一个nested稀疏网络,由多个层级构成,来进行nested学习。S-Net 引入了一个4-width框架,在单个网络中加入了不同的复杂度,为了最小化训练开支,提出了可切换的批归一化操作。[27] 使用知识蒸馏来训练一个多-出口的网络。但是,这些方法都只在有限个数的约束条件下执行。US-Net 可以迅速地调节运行时网络宽度,满足任意的准确率-效率平衡。但是随着计算资源的降低,模型表现就显著降低了。[3] 提出了一个渐进地收缩方法,从一个训练地很好的大模型中微调出一个子模型,但是该训练过程很繁琐且昂贵。
多尺度特征学习。在不同的任务上人们已经研究了多尺度特征的效果。FPN将金字塔特征融合起来,用于目标检测和实例分割。[17] 提出了一个多网格卷积,将信息传入到尺度空间。HRNet 设计了一个多分支结构,在不同分辨率之间交换信息。但是,这些工作都要用到多分支融合结构,该结构通常不适合并行。本文方法没有修改网络结构,学到的多尺度特征不仅来源于图像尺度,也来源于网络尺度。
3. Methodology
3.1 Preliminary
Sandwich Rule。US-Net 训练了一个可以在任意资源限制下执行的网络。解决方案就是,随机选取多个网络宽度来训练,积累其梯度来优化。但是,子网络的表现受到最小宽度( 0.25 × 0.25\times 0.25×)和最大宽度( 1.0 × 1.0\times 1.0×)约束。因此在每个iteration中,引入了sandwich rule来选取最小和最大的宽度,以及2个随机的宽度。
Inplace Distillation。知识蒸馏将知识从教师网络迁移到学生网络上。依据sandwich rule,由于在每个iteration中都选取一个最大的网络,很自然地就用这个最大的网络学习ground truth 标签,作为教师来指导子网络学习。这要比用ground truth标签来训练所有的子网络的效果好。
Post-statistics of BN。US-Net 提出,每个子网络都需要其自己的BN统计信息(均值和方差),但是保存所有子网络的统计信息是不充分的。因此在训练完成后,US-Net 会针对特定的子网络收集其BN信息。实验结果显示,要想获得准确的BN数据,2000个样本就足够了。
3.2 Rethinking Efficient Network Design
标准卷积的计算成本是 C 1 × C 2 × K × K × H × W C_1 \times C_2 \times K\times K\times H\times W C1×C2×K×K×H×W,其中 C 1 , C 2 C_1, C_2 C1,C2是输入和输出的通道数, K K K是卷积核大小, H , W H,W H,W分别是输出特征图的大小。之前的工作大多都关注在降低 C 1 × C 2 C_1\times C_2 C1×C2。最常用的分组卷积将标准卷积拆分为小组,将计算量降低为 C 1 × ( C 2 / g ) × K × K × H × W C_1 \times (C_2/g) \times K\times K\times H\times W C1×(C2/g)×K×K×H×W,其中 g g g是分组的个数。 g g g越大,计算量就越低,但是内存进入成本(MAC)就越高,使得网络在实际应用中不够高效。
在本文方法中,作者将注意力放到了降低 H × W H\times W H×W上,降低输入分辨率。首先,如图1所示,平衡网络宽度和分辨率可以取得更好的准确率-效率平衡。其次,降采样输入分辨率并不会损害模型表现。它有时甚至可以提升表现。[6] 指出,较低分辨率的图像可能产生更优的检测准确率,因为没有很多冗余的细节。第三,不同分辨率包含着不同的信息。较低分辨率的图像可能包含更多全局结构,而较高分辨率可能包含更多细粒度的规则。从不同尺度的图像和特征中学习多尺度表示,被证明是有效的。但是这些方法都要用到多分支结构,这对并行并不友好。受这些观察启发,作者提出了一个相互学习的框架,同时考虑网络大小和输入分辨率,实现网络准确率-效率的平衡。
3.3 Mutual Learning Framework
**Sandwich Rule and Mutual Learning.**如3.2节讨论的,不同分辨率包含不同的信息。作者想利用该特性,学到鲁棒的特征表示和更优的宽度-分辨率平衡。US-Net里的sandwich rule 可以看作为相互学习的一个机制,协作学习一组网络。由于子网络之间共享权重,协同优化,它们的知识可以互相迁移。较大的网络能够利用较小网络的特征。同样,较小网络也可以受益于较大网络的特征。因此,作者给各子网络输入不同的分辨率输入。通过共享知识,每个子网络都可以获取多尺度表示。
Model Training. 作者在图2中提供了一个例子,来介绍该框架。作者训练了一个网络,其宽度范围从 0.25 × 0.25\times 0.25×到 1.0 × 1.0\times 1.0×。作者首先按照sandwich rule选择了2个子网络,即最小的 ( 0.25 × ) (0.25\times) (0.25×),最大的 ( 1.0 × ) (1.0\times) (1.0×),和2个随机宽度比值的 α 1 , α 2 ∈ ( 0.25 , 1 ) \alpha_1, \alpha_2 \in (0.25,1) α1,α2∈(0.25,1)。然后,与传统的用 224 × 224 224\times 224 224×224作为输入的ImageNet训练不同,作者将输入图像缩放到 { 224 , 196 , 160 , 128 } \{224,196,160,128\} {224,196,160,128},将它们输入进不同的子网络中。作者将子网络的权重表示为 W 0 : w W_{0:w} W0:w,其中 w ∈ ( 0 , 1 ] w\in(0,1] w∈(0,1]是子网络的宽度, 0 : w 0:w 0:w意思是子网络会采用原网络每一层权重的 w × 100 % w\times 100\% w×100%。 I R = r I_{R=r} IR=r代表一个 r × r r\times r r×r输入图片。然后 N ( W 0 : w , I R = r ) N(W_{0:w}, I_{R=r}) N(W0:w,IR=r)表示子网络的输出,宽度是 w w w,分辨率是 r × r r\times r r×r。对于最大的子网络(即图2中的原网络),作者总是用最高的分辨率输入和ground truth标签来训练它。原网络的损失是:
l o s s f u l l = C r o s s E n t r o p y ( N ( W 0 : 1 , I R = 224 ) , y ) loss_{full} = CrossEntropy(N(W_{0:1}, I_{R=224}), y) lossfull=CrossEntropy(N(W0:1,IR=224),y)
对于其它的子网络,作者随机从 { 224 , 196 , 160 , 128 } \{224,196,160,128\} {224,196,160,128}中选择一个输入分辨率,用原网络的输出来训练它。第 i i i个子网络的损失是:
l o s s s u b i = K L D i v ( N ( W 0 : w i , I R = r i ) , N ( W 0 : 1 , I R = 224 ) ) loss_{sub_i} = KLDiv(N(W_{0:w_i}, I_{R=r_i}), N(W_{0:1}, I_{R=224})) losssubi=KLDiv(N(W0:wi,IR=ri),N(W0:1,IR=224))
其中KLDiv是 Kullback-Leibler散度。原网络和子网络的总的损失是:
l o s s = l o s s f u l l + ∑ i = 1 3 l o s s s u b i loss = loss_{full} + \sum_{i=1}^3 loss_{sub_i} loss=lossfull+i=1∑3losssubi
用最高分辨率来训练原网络的原因是,最高分辨率包含着更多的细节信息。同样,原网络也具有最强的学习能力,获取图像数据的判别信息。
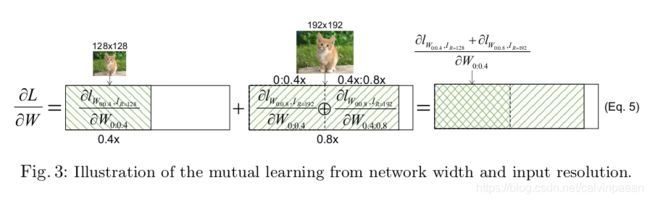
Mutual learning from width and resolution. 这一部分,作者解释了为何该框架能够从不同的宽度和分辨率中相互学习。为了展示简单些,作者只考虑了2个网络宽度, 0.4 × , 0.8 × 0.4\times, 0.8\times 0.4×,0.8×,2个分辨率 128 , 192 128, 192 128,192。如图3所示, 0.4 × 0.4\times 0.4×的子网络选择输入分辨率为128,而 0.8 × 0.8\times 0.8×的子网络选择输入分辨率为192。然后,作者将 0.4 × 0.4\times 0.4×的子网络定义为 ∂ l W 0 : 0.4 , I R = 128 ∂ W 0 : 0.4 \frac{\partial l_{W_{0:0.4}, I_{R=128}}}{\partial W_{0:0.4}} ∂W0:0.4∂lW0:0.4,IR=128,将 0.8 × 0.8\times 0.8×的子网络定义为 ∂ l W 0 : 0.8 , I R = 192 ∂ W 0 : 0.8 \frac{\partial l_{W_{0:0.8}, I_{R=192}}}{\partial W_{0:0.8}} ∂W0:0.8∂lW0:0.8,IR=192。由于 0.8 × 0.8\times 0.8×的子网络与 0.4 × 0.4\times 0.4×的子网络共享权重,我们可以将它的梯度拆分为:
∂ l W 0 : 0.8 , I R = 192 ∂ W 0 : 0.8 = ∂ l W 0 : 0.8 , I R = 192 ∂ W 0 : 0.4 ⊕ ∂ l W 0 : 0.8 , I R = 192 ∂ W 0.4 : 0.8 \frac{\partial l_{W_{0:0.8}, I_{R=192}}}{\partial W_{0:0.8}} = \frac{\partial l_{W_{0:0.8}, I_{R=192}}}{\partial W_{0:0.4}} \oplus \frac{\partial l_{W_{0:0.8}, I_{R=192}}}{\partial W_{0.4:0.8}} ∂W0:0.8∂lW0:0.8,IR=192=∂W0:0.4∂lW0:0.8,IR=192⊕∂W0.4:0.8∂lW0:0.8,IR=192
其中 ⊕ \oplus ⊕是向量concat操作。因为这2个子网络的梯度在训练时会积累起来,总的梯度计算如下:
∂ L ∂ W = ∂ l W 0 : 0.4 , I R = 128 ∂ W 0 : 0.4 + ∂ l W 0 : 0.8 , I R = 192 ∂ W 0 : 0.8 = ∂ l W 0 : 0.4 , I R = 128 ∂ W 0 : 0.4 + ( ∂ l W 0 : 0.8 , I R = 192 ∂ W 0 : 0.4 ⊕ ∂ l W 0 : 0.8 , I R = 192 ∂ W 0.4 : 0.8 ) = ∂ l W 0 : 0.4 , I R = 128 + ∂ l W 0 : 0.8 , I R = 192 ∂ W 0 : 0.4 ⊕ ∂ l W 0 : 0.8 , I R = 192 ∂ W 0.4 : 0.8 \frac{\partial L}{\partial W} = \frac{\partial l_{W_{0:0.4}, I_{R=128}}}{\partial W_{0:0.4}} + \frac{\partial l_{W_{0:0.8}, I_{R=192}}}{\partial W_{0:0.8}} = \frac{\partial l_{W_{0:0.4}, I_{R=128}}}{\partial W_{0:0.4}} + (\frac{\partial l_{W_{0:0.8}, I_{R=192}}}{\partial W_{0:0.4}} \oplus \frac{\partial l_{W_{0:0.8}, I_{R=192}}}{\partial W_{0.4:0.8}}) = \frac{\partial l_{W_{0:0.4}, I_{R=128}} + \partial l_{W_{0:0.8}, I_{R=192}}}{\partial W_{0:0.4}} \oplus \frac{\partial l_{W_{0:0.8}, I_{R=192}}}{\partial W_{0.4:0.8}} ∂W∂L=∂W0:0.4∂lW0:0.4,IR=128+∂W0:0.8∂lW0:0.8,IR=192=∂W0:0.4∂lW0:0.4,IR=128+(∂W0:0.4∂lW0:0.8,IR=192⊕∂W0.4:0.8∂lW0:0.8,IR=192)=∂W0:0.4∂lW0:0.4,IR=128+∂lW0:0.8,IR=192⊕∂W0.4:0.8∂lW0:0.8,IR=192
因此, 0.4 × 0.4\times 0.4×的子网络的梯度就是 ∂ l W 0 : 0.4 , I R = 128 + ∂ l W 0 : 0.8 , I R = 192 ∂ W 0 : 0.4 \frac{\partial l_{W_{0:0.4}, I_{R=128}} + \partial l_{W_{0:0.8}, I_{R=192}}}{\partial W_{0:0.4}} ∂W0:0.4∂lW0:0.4,IR=128+∂lW0:0.8,IR=192,由2部分组成。第一部分来自于它自己 ( 0 : 0.4 × ) (0:0.4\times) (0:0.4×),分辨率是128。第二部分来自于 0.8 × 0.8\times 0.8×子网络(即 0 : 0.4 × 0:0.4\times 0:0.4×部分),分辨率是192。因此,子网络能够从不同的输入分辨率和网络尺度中获取多尺度特征表示。因为网络宽度的随机选取,该框架的每个子网络都可以学习多尺度特征表示。
模型推理。训练好的模型可以在不同的宽度-分辨率配置上执行。目的是在给定资源下找到最佳的配置。一个简单的实现方式就是query table。特别地,作者用step-size 0.05 × 0.05\times 0.05× 来从 0.25 × 0.25\times 0.25×到 1.0 × 1.0\times 1.0×中选取网络的宽度,从 { 224 , 192 , 160 , 128 } \{224,192,160,128\} {224,192,160,128}中选择分辨率。作者在验证集上测试了所有的宽度-分辨率配置,根据约束条件(FLOPs或延迟)选择最佳的一个。因为无需重复训练,整个流程只要训练一次。
4. Experiments
本部分,作者首先在ImageNet上进行了分类实验,来证明MutualNet的性能。然后,作者进行了消融实验,分析相互学习机制。最后,作者在迁移学习数据集、COCO目标检测及实例分割任务上应用MutualNet,证明其鲁棒性和泛化能力。
4.1 在ImageNet分类任务上的评价
在ImageNet数据集上,作者将MutualNet和US-Net等独立训练的网络进行了比较。作者也在两个轻量级模型MobileNetV1和MobileNetV2上评价了该框架。这2个网络也分别代表了非残差和残差结构。
实现细节。在动态FLOPs约束条件(MobileNetV1 为 [ 13 , 569 ] [13,569] [13,569]MFLOPs,MobileNetV2 为 [ 57 , 300 ] [57,300] [57,300] MFLOPs)下,作者之与US-Net进行比较。给定 224 × 224 224\times 224 224×224的输入分辨率,US-Net对MobileNetV1使用的宽度大小是 [ 0.05 , 1.0 ] × [0.05, 1.0]\times [0.05,1.0]×,对MobileNetV2使用的宽度大小是 [ 0.35 , 1.0 ] × [0.35, 1.0]\times [0.35,1.0]×。为了符合一样的动态约束条件,本文方法在MobileNetV1上使用的宽度大小是 [ 0.25 , 1.0 ] × [0.25, 1.0]\times [0.25,1.0]×,在MobileNetV2上使用的宽度是 [ 0.7 , 1.0 ] × [0.7,1.0]\times [0.7,1.0]×,下采样输入分辨率是 { 224 , 192 , 160 , 128 } \{224,192,160,128\} {224,192,160,128}。由于输入分辨率较低,本文方法能够使用比US-Net 更高的宽度下界( 0.25 × , 0.7 × 0.25\times, 0.7\times 0.25×,0.7×)。其它的训练设定和US-Net一样。
Comparison with US-Net。作者首先在MobileNetV1和MobileNetV2主干网络上将本文框架与US-Net做比较。图4是准确率-FLOPs的曲线。可以看到本文框架一直要比US-Net效果好。在较小的计算开支下,MutualNet 取得了显著的提升。这是因为,MutualNet 既考虑了网络宽度,也考虑了输入分辨率,能够在二者间找到平衡。例如,假设资源限制在150 MFLOPs,给定输入分辨率为224,US-Net 必须降低其网络宽度到 0.5 × 0.5\times 0.5×,而MutualNet 可以通过平衡的配置 ( 0.7 × − 160 ) (0.7\times - 160) (0.7×−160) 来满足该预算,实现更高的准确率( 65.6 % 65.6\% 65.6%(MutualNet) vs. 62.9 % 62.9\% 62.9%(US-Net),如图4a)。另一方面,MutualNet 能够学习多尺度特征,进一步提升每个子网络的性能。可以看到,即使对于相同的配置( 1.0 × − 224 1.0\times - 224 1.0×−224),MutualNet 也要超过US-Net,即在MobileNetV1上 72.4 % 72.4\% 72.4%(MutualNet) vs. 71.7 % 71.7\% 71.7% (US-Net),在MobileNetV2上 72.9 % 72.9\% 72.9%(MutualNet) vs. 71.5 % 71.5\% 71.5% (US-Net),如图4。

Comparison with independently Trained Networks。在[14,29]中,不同尺度的MobileNets 是单独训练的。作者将宽度和分辨率作为单独的因素考虑,因而无法利用不同配置包含的信息。在图5不同的宽度-分辨率配置下,作者将MutualNet和单独训练的MobileNets比较。对于MobileNet-V1,从 { 1.0 × , 0.75 × , 0.5 × , 0.25 × } \{1.0\times, 0.75\times, 0.5\times, 0.25\times \} {1.0×,0.75×,0.5×,0.25×}中选择一个宽度,从 { 224 , 192 , 160 , 128 } \{224,192,160,128\} {224,192,160,128}中选择分辨率,这样共有16个配置。相同地,MobileNetV2从 { 1.0 × , 0.75 × , 0.5 × , 0.35 × } \{1.0\times, 0.75\times, 0.5\times, 0.35\times \} {1.0×,0.75×,0.5×,0.35×}和 { 224 , 192 , 160 , 128 } \{224,192,160,128\} {224,192,160,128}中选择。图5中,该框架的表现一直要比MobileNets高。对于相同的宽度-分辨率配置(尽管它对于MutualNet不一定是最佳的配置),MutualNet仍然可以实现更优的性能。这就证明MutualNet不仅能实现更优的宽度-分辨率平衡,也能通过互相学习机制学到更强的特征表示。
4.2 Ablation Study
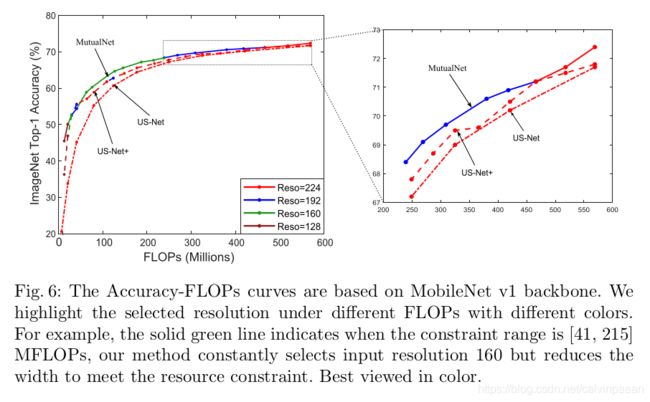
通过相互学习来平衡宽度-分辨率配置。图1中很清楚,在推理时,我们可以对US-Net使用不同的分辨率,改进原始的US-Net。但是因为没有用宽度-分辨率相互学习的机制,无法实现最佳的宽度-分辨率平衡。实验中,作者在宽度大小 [ 0.25 , 1.0 ] × [0.25, 1.0]\times [0.25,1.0]×和输入分辨率 { 224 , 192 , 160 , 128 } \{224,192,160,128\} {224,192,160,128}上测试了US-Net,将它叫做US-Net+。图6中,基于MobileNetV1主干网络,作者plot了MutualNet和US-Net+的准确率-FLOPs曲线,用不同颜色表示输入分辨率。由于作者降低了FLOPs( 549 → 468 549\rightarrow 468 549→468 MFLOPs),MutualNet首先降低了网络宽度,满足其约束条件,保留了 224 × 224 224\times 224 224×224分辨率(图6红线)。在468 MFLOPs后,MutualNet 选择了较低的输入分辨率(192),并不断降低网络宽度来满足约束条件。另一方面,US-Net+ 无法找到这样的平衡。随着FLOPs逐渐降低,它一直在缩小网络的宽度,使用的分辨率(224)相同。这是因为,US-Net+没有将输入分辨率融入到框架中去。推理时,只使用不同的分辨率是无法实现最佳的宽度-分辨率平衡的。

Difference with EfficientNet。EfficientNet 指出了平衡网络宽度、深度、分辨率的重要性。但是它是单独考虑这些因素。作者在这3个维度上使用网格搜索法,单独地训练每个配置,根据约束条件来找到最佳的配置。而MutualNet则是在一个统一的框架中融入宽度和分辨率。当资源约束在 2.3 BFLOPs,作者用最佳的EfficientNet来改造MobileNetV1,并与之比较。与该尺度设定类似,作者用宽度范围 [ 1.0 × , 2.0 × ] [1.0\times, 2.0\times] [1.0×,2.0×] 来训练MutualNet,从 { 224 , 256 , 288 , 320 } \{224,256, 288, 320\} {224,256,288,320}中选择一个分辨率。这样MutualNet 的 BFLOPs 就在 [ 0.57 , 4.5 ] [0.57, 4.5] [0.57,4.5] BFLOPs。我们选择表现最好的宽度-分辨率配置,在2.3 BFLOPs情况下。表2中比较了结果。MutualNet的表现要比EfficientNet好许多,因为它能够获取多尺度的特征表示,通过宽度-分辨率相互学习。
Difference with Multi-scale Data Augmentation. 在目标检测和分割任务上,多尺度数据增广也很流行。首先,作者从原则方面介绍MutualNet与多尺度数据增广不同。其次,本文方法要远比多尺度数据增广好。
在多尺度数据增广中,网络在不同的iterations中所接受的图像,分辨率不同。但是在每个iteration中,训练优化的输入分辨率是一样的。MutualNet 随机选取4个子网络,彼此间共享权重。因为子网络可以选择不同的输入分辨率,在每个iteration中,权重优化就是用不同的分辨率,如图3所示。这就使得每个子网络可以从宽度和分辨率信息中有效地学习多尺度特征表示。为了验证相互学习机制的优点,作者在MobileNet和US-Net上使用了多尺度数据增广。
MobileNet + Multi-scale data augmentation。作者利用多尺度图片训练了MobileNetV2( 1.0 × 1.0\times 1.0× 宽度)。为了公平比较,输入图片随机从 { 224 , 192 , 160 , 128 } \{224,192,160,128\} {224,192,160,128}选择,其他的设定与MutualNet一样。如表3所示,多尺度数据增广只会提升基线模型(MobileNetV2)一点点,而MutualNet(主干网络是MobileNetV2)则可以提升许多。
US-Net+多尺度数据增广。MutualNet框架会将不同大小的图像输入进各子网络,与它不同,在实验中,作者随机从 { 224 , 192 , 160 , 128 } \{224,192,160,128\} {224,192,160,128}选择一个尺度,在每个iteration中将同样大小的图像输入进所有的子网络。也就是,每个子网络所获取的图像分辨率一样。这样,在单个iteration中,权重仍然是朝着单个分辨率来优化,但是不同iterations中是不同的。该实验基于MobileNetV2。宽度与分辨率设定和4.1节一样。如图7所示,在所有的FLOPs比较中,该方法要比 US-Net+多尺度数据增广好。这些实验证明了,相互学习机制所带来的提升要比多尺度数据增广更多。
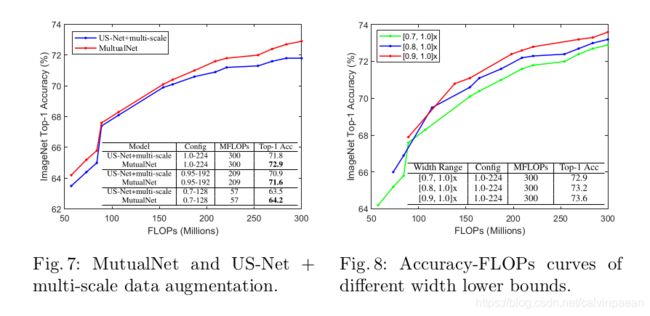


Effects of Width Lower Bound. 约束条件的范围和模型性能也会受模型宽度的下界影响。为了研究此影响,作者通过3个不同的下界( 0.7 × , 0.8 × , 0.9 × 0.7\times,0.8\times, 0.9\times 0.7×,0.8×,0.9×)在MobileNetV2上做实验。图8结果显示,下界值越高,整体性能越好,但是条件范围就越窄。一个有去的发现是,整体网络( 1.0 × − 224 1.0\times -224 1.0×−224)的性能也会随着下界的值变大(从 0.7 × 0.7\times 0.7×到 0.9 × 0.9\times 0.9×)而得到提升。该特性在US-Net中没有发现。作者认为,这是因为多尺度特征表示更加鲁棒而泛化性强,可以被整个网络有效地重复利用。而在US-Net中,整个网络是无法有效地从子网络中获益的。
提升单个网络表现。如上所述,当我们增加网络宽度的下界时,整个网络的表现会明显提升。作者将MutualNet与主流的性能提升方法比较(如AutoAugmentation, SENet, 知识蒸馏)来显示其优越性。作者使用Wide-ResNet 在Cifar-10和Cifar-100上进行实验,使用ResNet-50在ImageNet上进行实验。MutualNet 采用的宽度范围是 [ 0.9 , 1.0 ] × [0.9,1.0]\times [0.9,1.0]×,在图8中这样它的表现是最佳的。在Cifar10和Cifar100数据集上,分辨率是从 { 32 , 28 , 24 , 20 } \{32,28,24,20\} {32,28,24,20}中选取,而对于ImageNet数据集,分辨率是从 { 224 , 192 , 160 , 128 } \{224,192,160,128\} {224,192,160,128}中选取。Wide-ResNet训练了200个epochs。ResNet训练了100个epochs。表4和表5中比较了结果。MutualNet相对于其它方法,取得了显著提升。请注意,MutualNet是一个通用的训练机制,无需昂贵的搜索流程或额外的网络模块或强大的教师网络。而且,MutualNet 训练与正常训练一样简单,与其它性能提升方法可以正交,如AutoAugmentation。因此,它可以很容易地与其它方法结合。
4.3 迁移学习
为了评价该方法的特征学习能力,作者进一步在3个主流的迁移学习数据集(Cifar-100, Food-101, MIT-Indoor67)上做了实验。Cifar-100是级别较高的目标分类数据集,Food-101 是一个细粒度较高的分类数据集,MIT-Indoor67 是一个场景分类数据集。数据集的类别多样,很适合评价学到的特征的鲁棒性。作者将MutualNet和US-Net、MobileNetV1进行比较。作者微调了ImageNet上预训练的模型,batch size为256,初始学习率为0.1,采用cosine 退火机制,总共训练100个epochs。MutualNet和US-Net都采用宽度范围 [ 0.25 , 1.0 ] × [0.25, 1.0]\times [0.25,1.0]×来训练,用分辨率 { 224 , 192 , 160 , 128 } \{224,192,160,128\} {224,192,160,128}来测试。图9显示了结果。MutualNet的表现要比US-Net和MobileNet好许多。这证明MutualNet学到的特征泛化能力不错。
4.4 目标检测和实例分割
作者也在COCO数据集和实例分割任务上做了评测。基于Mask-RCNN-FPN和以VGG-16作为主干网络的MMDetection toolbox做的实验。这两个方法都使用宽度范围 [ 0.25 , 1.0 ] × [0.25, 1.0]\times [0.25,1.0]×训练。然后,作者在COCO数据集上微调预训练模型。FPN neck 和检测head在各子网络间共享。为了简洁,作者没有使用inplace distillation。相反,每个子网络都用ground truth训练。其它的训练流程和ImageNet分类训练一样。延续目标检测上的常见设定,US-Net是在分辨率为 1000 × 600 1000\times 600 1000×600的图像上训练的。本文方法随机从 1000 × { 600 , 480 , 360 , 240 } 1000\times \{600,480,360,240\} 1000×{600,480,360,240}中选择分辨率。所有的模型都训练 2 × 2\times 2×时间,为了收敛的更好,用不同图像分辨率来训练。mAP( I o U = 0.50 : 0.05 : 0.95 IoU=0.50:0.05:0.95 IoU=0.50:0.05:0.95时的AP)在表10中列出来了。结果显示,MutualNet要比US-Net好许多。对于整个网络 ( 1.0 × − 600 ) (1.0\times -600) (1.0×−600)来说,MutualNet要比US-Net和其它独立训练的网络好。这又一次验证了宽度-分辨率相互学习机制的作用。图11提供了几个例子,反映MutualNet对于小尺度和大尺度物体比US-Net更鲁棒。
