音频处理与压缩技术漫谈
作者:崔承宗,网易资深开发工程师,主要负责直播Android端和WebRTC音频处理和编解码的开发维护工作。个人技术擅长领域:音视频处理和编解码,以及相关的网络传输技术。
一、音频处理与压缩的意义
在视频或者音频通话过程中,一方面为了减小原始声音数据的传输码率,需要进行音频压缩,另一方面为了得到更高质量的音质,需要进行音频处理。
音频处理的方法主要包括:音频降噪、自动增益控制、回声抑制、静音检测和生成舒适噪声,主要的应用场景是音视频通话领域。音频压缩包括各种音频编码标准,涵盖ITU制定的电信领域音频压缩标准(G.7xx系列)和微软、Google、苹果、杜比等公司制定的互联网领域的音频压缩标准。(iLBC、SILK、OPUS、AAC、AC3等)。
二、音频基础概念
在进一步了解音频处理和压缩之前需要明确如下几个概念。
- 音调:泛指声音的频率信息,人耳的主观感受为声音的低沉(低音)或者尖锐(高音)。
- 响度:声音的强弱。
- 采样率:声音信息在由模拟信号转化为数字信号过程中的精确程度,采样率越高,声音信息保留的越多。
- 采样精度:声音信息在由模拟信号转化为数字信号过程中,表示每一个采样点所需要的字节数,一般为16bit(双字节)表示一个采样点。
- 声道数:相关的几路声音数量,常见的如单声道、双声道、5.1声道。
- 音频帧长:音频处理或者压缩所操作的一段音频信息,常见的是10ms,20ms,30ms。
三、音频处理基础
3.1 噪声抑制(Noise Suppression)
手机等设备采集的原始声音往往包含了背景噪声,影响听众的主观体验,降低音频压缩效率。以Google著名的开源框架WebRTC为例,我们对其中的噪声抑制算法进行严谨的测试,发现该算法可以对白噪声和有色噪声进行良好的抑制。满足视频或者语音通话的要求。
其他常见的噪声抑制算法如开源项目Speex包含的噪声抑制算法,也有较好的效果,该算法适用范围较WebRTC的噪声抑制算法更加广泛,可以在任意采样率下使用。
3.2 回声消除(Acoustic Echo Canceller)
在视频或者音频通话过程中,本地的声音传输到对端播放之后,声音会被对端的麦克风采集,混合着对端人声一起传输到本地播放,这样本地播放的声音包含了本地原来采集的声音,造成主观感觉听到了自己的回声。
回声产生的原理如下图所示:

以WebRTC为例,其中的回声抑制模块建议移动设备采用运算量较小的AECM算法,该算法的处理步骤如下图所示。有兴趣的读者可以参考AECM的源代码进行研究,这里不展开介绍了。
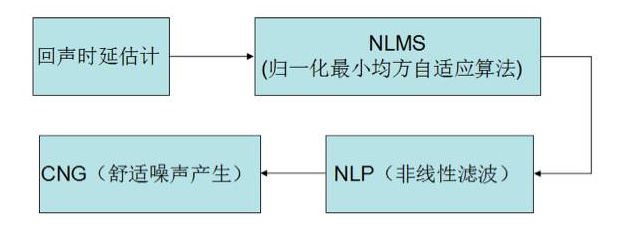
3.3 自动增益控制(Auto Gain Control)
手机等设备采集的音频数据往往有时候响度偏高,有时候响度偏低,造成声音忽大忽小,影响听众的主观感受。自动增益控制算法根据预先配置的参数对输入声音进行正向/负向调节,使得输出的声音适宜人耳的主观感受。
以WebRTC为例,它的自动增益控制算法的基本流程图如下所示:
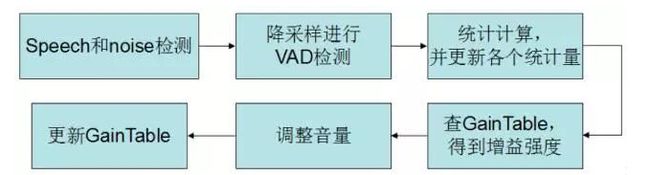
3.4 静音检测(Voice Activity Detection)
静音检测的基本原理:计算音频的功率谱密度,如果功率谱密度小于阈值则认为是静音,否则认为是声音。静音检测广泛应用于音频编码、AGC、AECM等。
3.5 舒适噪声产生(Comfortable NoiseGeneration)
舒适噪声产生的基本原理:根据噪声的功率谱密度,人为构造噪声。广泛适用于音频编解码器。在编码端计算静音时的白噪声功率谱密度,将静音时段和功率谱密度信息编码。在解码端,根据时间信息和功率谱密度信息,重建随机白噪声。
它的应用场景:完全静音时,为了创造舒适的通话体验,在音频后处理阶段添加随机白噪声。
四、音频编码基础
介绍了音频处理基础,再向大家介绍一下音频的另一个广泛应用的领域:音频编码。
首先看一下当前应用最广泛的一些音频编码标准,如下图所示:

图中横轴是音频编码码率,纵轴是音频频带信息。从图中我们可以获得如下几方面信息。
(1)对于固定码率的编码标准,如G.711或者G.722,图中采用单点表示,说明这两个编码标准是固定码率编码标准。其他如Opus、Speex,它们的曲线是连续的,说明这类编码标准是可变码率的编码标准。
(2)从频带方面看,G.711、G.722、AMR和iLBC等标准适用于narrowband(8khz采样率)和wideband(16khz采样率)范围,针对普通的语音通话场景。AAC和MP3适用于fullband(48khz采样率)范围,针对特殊的音乐场景。而Opus适用于整个频带,可以进行最大范围的动态调节,适用范围最广。
(3)从标准的收费情况看,适用于互联网传输的iLBC、Speex和Opus都是免费且开源的;适用于音乐场景的MP3和AAC,需要license授权,而且不开源。
五、结语
随着音频处理和压缩技术的不断发展,效果更好、适用范围更广、性能更高的算法和新的技术必将不断涌现,不断改善我们的生活。
本文转载自:http://netease.im/blog/457/