用GraphLab Create构建音乐推荐系统
最近跟着大神在进行机器学习实战,用GraphLab Create做音乐推荐系统。在这里,我将构建两种方法的音乐推荐系统,分别为:基于流行度的推荐系统和基于个性化的推荐系统。并且对于构建的推荐系统,分别用准确率和召回率来进行评估。
下面我将详细介绍怎么用GraphLab Create来构建音乐推荐系统。
- 系统:Windows10系统
- 软件:GraphLab Create,Jupyter Notebook,python2,IPython
1、导入GraphLab Create包
import graphlab并将GraphLab Canvas的显示设置为显示在IPython Notebook中(PS:这一步纯属个人习惯)
graphlab.canvas.set_target('ipynb') 2、读取数据
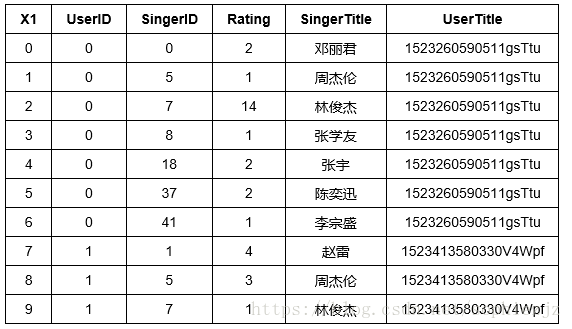
song_data = graphlab.SFrame('song_data.csv')我们的音乐数据格式如下图所示,由X1(每一行的行标)、UserID(用户名映射过来的ID)、SingerID(歌手名映射过来的ID)、Rating(用户点击歌手的次数,代表歌手的流行度)、SingerTitle(歌手名)、UserTitle(用户名)组成
3、探索数据
①查看数据集中最流行的歌手
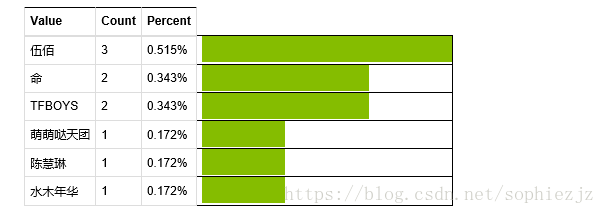
可知,伍佰是最流行的歌手,被三个用户点击,占比为0.515%
②分别计算数据集中数据和用户的个数
#计算数据集中数据的个数
len(song_data) #数据集中数据个数为583
#计算数据集中用户的个数
users = song_data['UserID'].unique()
len(users) #数据集中用户个数为804、构建推荐系统
①使用random_split函数,将数据集划分为训练数据集和测试数据集,其中训练集和测试集数据比例为8:2
train_data, test_data = song_data.random_split(.8, seed=0)②构建音乐推荐系统
a. 调用GraphLab Create中内置的popularity_recommender库中的create函数,构建基于流行度的音乐推荐模型
popularity_model = graphlab.popularity_recommender.create(train_data, user_id='UserID', item_id='SingerID')b. 调用GraphLab Create中内置的item_similarity_recommender库中的create函数,构建基于个性化的音乐推荐模型
personalized_model = graphlab.item_similarity_recommender.create(train_data, user_id='UserID', item_id='SingerID')③基于音乐推荐系统对用户进行预测
a. 调用recommend函数,利用基于流行度的音乐推荐系统对用户进行预测
分别对用户2和用户9进行预测,从结果中可看出,基于流行度的推荐系统对两个用户的预测很相似,符合基于流行度进行推荐的特点
popularity_model.recommend(users=[users[1]]) 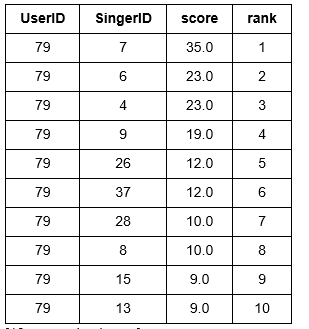
popularity_model.recommend(users=[users[8]])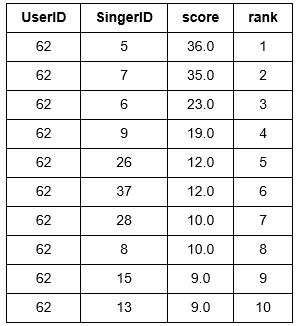
b. 调用recommend函数,利用基于个性化的音乐推荐系统对用户进行预测
分别对用户2和用户9进行预测,从结果中可看出,基于个性化的推荐系统对两个用户的预测很不相似,符合基于个性化进行推荐的特点
personalized_model.recommend(users=[users[8]])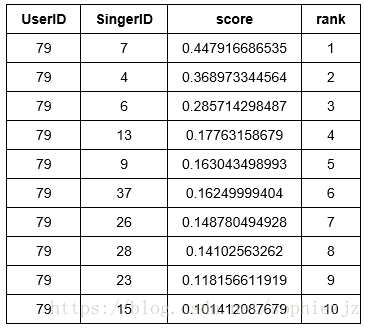
personalized_model.recommend(users=[users[8]])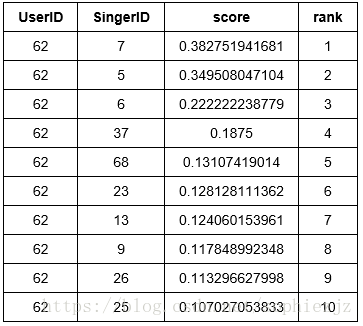
五、评估推荐系统
对构建的基于流行度的推荐系统和基于个性化的推荐系统从准确率和召回率两方面进行评估与比较,可以直接调用GraphLab Create中的compare函数
model_performance = graphlab.compare(test_data, [popularity_model, personalized_model], user_sample=1.0)结果为:

为了更直观的看到两个推荐系统的评估和比较结果,可以调用GraphLab Create中的show_comparison函数,将结果显示在GraphLab Canvas图表中
graphlab.show_comparison(model_performance, [popularity_model, personalized_model])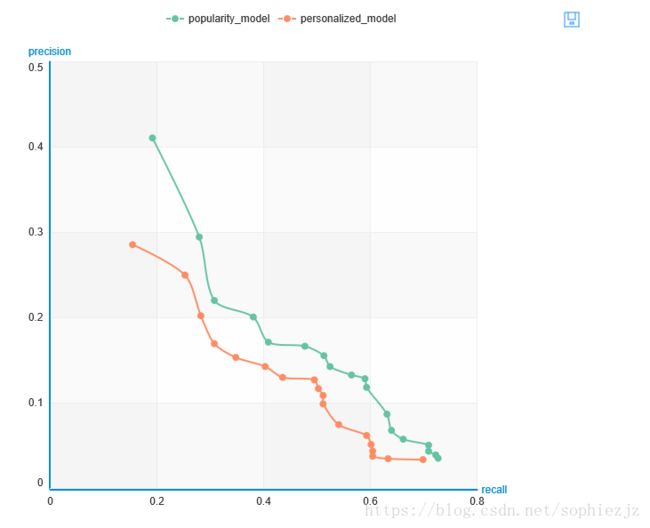
由图像可直观的看出,基于个性化的推荐系统比基于流行度的推荐系统性能更好。