Python Tensorflow + CNN + Opencv 英雄联盟小地图识别,LOL Minimap Scanner
Tensorflow + CNN + Opencv 英雄联盟小地图识别,LOL Minimap Scanner
- 本项目代码的展示
- 简介
- 思路
- 第一步:图像处理
- 1. 获取图像并转换
- 2. 过滤出图像中的红色通道
- 3. 识别圆圈
- 第二步:训练神经网络
- 1. 获得大量的可训练数据并整理
- 2. 搭建并训练神经网络
- 3. 检测以及保存模型
- 总结
- 亮丽之处:
- 缺点:
本项目代码的展示
简介
本人很热衷于英雄联盟这一款游戏,虽然水平一般但是玩起来乐趣十足。 与此同时,我又对AI有极大的兴趣,于是今年4月份开始大招这一款英雄联盟小地图识别器,目的是以一个小地图的图片为输入,检测到其中的英雄并标定他们的位置。
相似的项目 Farza Majeed 与 Ian Shoneveld 已经做过,有兴趣的可以去点击下面的链接来看他们写的文章
https://medium.com/@farzatv/deepleague-leveraging-computer-vision-and-deep-learning-on-the-league-of-legends-mini-map-giving-d275fd17c4e0
https://nlml.github.io/neural-networks/getting-champion-coordinates-from-the-lol-minimap/
在 Anaconda 中配置本文所需环境,terminal 中依次输入以下代码
conda install -c conda-forge opencv
conda install -c conda-forge numpy
conda install -c conda-forge tensorflow
conda install -c conda-forge pillow
conda install -c anaconda pil
如果不想阅读本文可以直接去 https://github.com/dcheng728/League-Minimap-Scanner 下载代码
思路
针对在小地图中区分并标定英雄图标的任务,有两种网络可以完成目的:图片分类(Image Classification),物体识别(Object Recognition)。 其中,图片分类要求在向神经网络输入图片前处理图像,并将英雄的头像提取,从而尽可能地减少图像中的相似之处,这种方法的优点是速度快,准确率高。 而以物体识别为目的的神经网络不需要提前提取英雄的图像,可以将整个小地图输入进神经网络,得到的是一系列的英雄名字以及他们的坐标。 物体识别好在不需要提前手写图像处理算法,弱在需要处理更多的像素,速度慢,且更多的相似特征将使其准确率降低。
博主的选择是采用图片分类算法基于本人对此算法更有经验且提取英雄的头像的图像处理算法并不复杂,利用OpenCV可以高速运行。
总的步骤可以分为以下几步
第一步:图像处理
1. 获取图像并转换
首先,在 python 中,截取屏幕并处理图像需要的拓展库为:PIL, Opencv, Numpy。我们依次引用,第一个函数是截取电脑屏幕的一部分的代码。PIL 的截图输入位置为我们显示器的像素位置,入代码中注释。
# 图像处理
#引用
from PIL import ImageGrab
from PIL import Image
import cv2
import numpy as np
def getimg():
image = ImageGrab.grab((1645,805,1920,1080))
image_array = np.array(image)
image_bgr = cv2.cvtColor(image_array,cv2.COLOR_RGB2BGR)
return image_bgr
"""
(x1,y1)
________________________
| |
| |
| |
| |
| Minimap |
| |
| |
| |
| |
|________________________|
(x2,y2)
"""
x1 = 1645
y1 = 805
x2 = 1920
y2 = 1080
Opencv 默认的图像是以 np.ndarray 的格式存在的,并且它的三通道分别是 Blue, Green, Red. 要想利用 Opencv 处理 PIL 获取的图片,我们首先需要将其转换成numpy的矩阵格式,然后利用 cv2.cvtColor 函数将原本的 RGB 格式 转换成 opencv 默认的 BGR 格式。
2. 过滤出图像中的红色通道
首先,玩过英雄联盟的朋友都知道,小地图中敌方英雄的头像都是用红色圆圈框住的,队友则是用蓝色框框住的,所以如果我们利用英雄联盟的这一特征我们是不是可以提取对方英雄的头像框?请看下图。
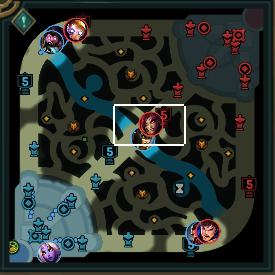
这张图片抓取的是一把正在进行的英雄联盟游戏的小地图,可以看到,游戏里敌方 ‘机器人’,‘婕拉’, ‘盖伦’ 头像旁都有一个红色的圈。这一特征为我们创造了极大的便利,也许在 3色道图中不够明显,请接着看下面的单个通道拆开的图片,注意观察 ‘机器人’ ,‘婕拉’ , ‘盖伦’ 这三个英雄在三个颜色通道里头像框的区别。

注意到了吗? 如果没有的话继续仔细观察这三个英雄头像框在三个通道里的区别。 这三个敌方英雄的头像框在 Red 通道里近乎是白色的,也就是说它拥有比它周围所有色块都显著的高的值。 如果我们把注意力集中到红色通道,设置一个阀值然后把它二值化(所有低于阈值的 = 0, 高于阀值 = 255),我们将得到理想的 ROI (Region of Interest, 感兴趣区域)。
但是首先我们得过滤掉红色通道中由其他颜色附加的红色值,在计算机视觉中,越是亮丽的颜色会更多的包含其他颜色的 RGB 值。什么意思呢? 打个比方,在图片的 (x,y), 坐标,它呈现给我们的是亮丽的绿色,它的 RGB 值为 (150,249,120). 在同图片的另一个坐标(x2,y2), 我们看见了深沉的红色,其 RGB 为 (140,50,50)。 如果我们单纯的看这张图片的红色通道,我们会认为 (x,y) 比 (x2,y2) 更红,因为 150 > 140。然而,很明显这是错的。 所以我们在提取红色通道之前需要考虑到这些亮丽的非红色很有可能被我们错误地认为是红色。
 RGB (150,255,100)
RGB (150,255,100)
 RGB (140,20,20)
RGB (140,20,20)
要避免这种情况很简单,代码如下
b,g,r = cv2.split(image) #提取 RGB 通道
#将图像二值化
inranger = cv2.inRange(r,120,255)
inrangeg = cv2.inRange(g,120,255)
inrangeb = cv2.inRange(b,120,255)
#用红色二值图减去其他两个通道的二值图
Red_channel = inranger - inrangeg - inrangeb
cv2.imshow('Red_channel',Red_channel)
运行后得到以下图片
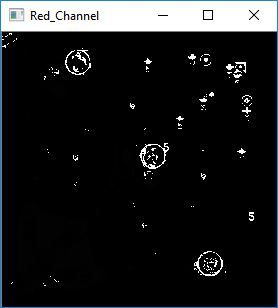
利用红色通道减去其他通道可以有效地抵消非红色在红色通道中占有的值,得到理想的图片,这里的 (120,255)是博主反复测试后得到的最佳值。图片中白色的圈均为上文中的英雄头像的红色框。接下来,我们只需要运行圆圈检测来获得这些白色圆圈的坐标。
3. 识别圆圈
对于识别圆圈, Opencv 提供了自己的算法 cv2.HoughCircle 就是利用霍夫算法检测圆圈的,因为本人对此算法没有了解这里就不多作评论了下面是代码的实现:
对霍夫算法感兴趣的可以看一下这一篇文章: https://blog.csdn.net/qq_25254777/article/details/78811342
coord = [] #list 保存找到的英雄的坐标
champion_list = [] #list 保存找到的英雄的头像
champion_list_text = [] #list 保存神经网络识别后的英雄名称
circles = cv2.HoughCircles(Red_channel,cv2.HOUGH_GRADIENT,1,10,param1 = 30,param2 =15,minRadius = 9, maxRadius = 30)
if(circles is not None):
for n in range(circles.shape[1]):
x = int(circles[0][n][0])
y = int(circles[0][n][1])
coords.append([x,y])
radius = int(circles[0][n][2])
cropped = image[y-radius:y+radius,x-radius:x+radius].copy()
to_append = cv2.resize(cropped,(24,24))
champion_list.append(to_append)
cv2.rectangle(image,(x - radius , y - radius),(x + radius , y + radius),(255,255,255),1)
champion_list = np.stack(champion_list,axis = 0,)
champion_list = champion_list.reshape((champion_list.shape[0], 24, 24, 3))
"""
以下代码是使用训练好的神经网络识别截取的英雄头像
champion_list_text = league_scanner.predict(champion_list)
for n in range(len(champion_list_text)):
cv2.putText(image,class_names[champion_list_text[n]],(coords[n][0]-12,coords[n][1]-12), cv2.FONT_HERSHEY_SIMPLEX,1,(255,255,255),1)
"""
其中red channel 是上一步骤图像处理后的的小地图图像,这一步骤完成后,执行
champs = np.concatenate((champion_list[0],champion_list[1],champion_list[2]),axis = 1)
cv2.imshow('champions', champs)
cv2.waitKey(0)
获得以下结果

好的,现在我们已经完成了提取英雄联盟中的英雄图像,下一步就是将他们放入神经网络,进行卷积以及训练了。
第二步:训练神经网络
1. 获得大量的可训练数据并整理
这个问题最初难倒了我,虽然我有一个可以从小地图中提取英雄头像的算法,我总不可能疯狂地打英雄联盟并且手动标定每个图像是什么英雄吧? 英雄联盟的训练营和 脚本软件 AutoHotKey 可帮到了我。、
众所周知,英雄联盟的训练营可以让玩家和一个电脑对线,比拼。既然如此,我可以开启一个英雄联盟训练营,与比方说稻草人对线5 分钟,并且在这个区间内截取 2000张小地图的图片。 然后利用上一步骤说讲述的 opencv 算法将敌方稻草人头像提取,这样我唯一得到的英雄就是我开始游戏前为敌方阵营选择的稻草人。我只需将所有从这2000张图片里提取的英雄头像存入一个文件夹,并将它命名为 ‘稻草人’ 即可。
但是我又不可能坐在那把训练营每一个英雄都开一把游戏,录完屏后再开下一把。我懒,又不想花这么多时间,于是利用 AutoHotKey 写了一个脚本,它会在客户端中点击开始游戏,选择训练营,选择英雄,开始游戏, 开始录屏,重复。目前类似的快捷键软件很多,我只是比较随便地选择了一个。
就这样,写好脚本第二天早上我把我的电脑开启,运行了脚本然后去了学校。期间我多次远程我的电脑来确保 AutoHotKey 在正常运行,一切完美。到了中午11点,程序报告所有数据已经录取成功,于是我获得了以下的文件夹们。
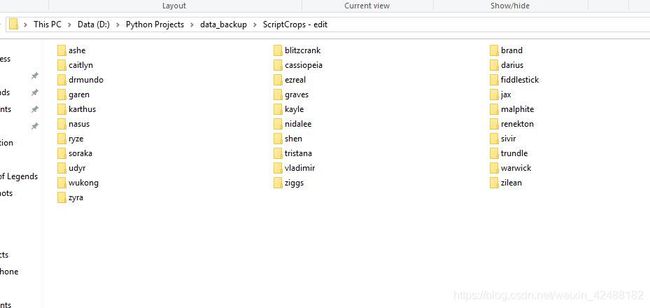
其中,每个文件夹大概有 1 mb 不到,包含 600 到 8000 张该英雄的图片,所有数据整体 包含 20000 张以上图片,50 mb 不到。 数据量可观,占用大小可以接受,接下来为了更快速地让 tensorflow 读取这些文件,我把它们以 8:2 的比例分割成了训练图片集以及测试图片集,并保存成了 numpy 矩阵的 ‘.npy’ 格式。
使用如下代码
#首先给所有英雄的类以一个数字标定
class_names = ['ashe','blitzcrank','brand','caitlyn','cassiopeia','darius','drmundo','ezreal','fiddlestick',
'garen','graves','jax','karthus','kayle','malphite','nasus','nidalee','renekton','ryze','shen',
'sivir','soraka','tristana','trundle','udyr','vladimir','warwick','wukong','ziggs','zilean','zyra']
training_images = [] #两个待填充的 list
training_labels = []
for champion_folders in os.listdir('ScriptCrops - edit/'):
for imgs in os.listdir(champion_folders):
if imgs[len(imgs)-4:len(imgs)] == '.jpg':
image = cv2.imread(champion_folders+imgs)
training_images.append(image)
training_labels.append(class_names.index(champion_folders)
#将填入图像的list文件转换成numpy矩阵文件
np_images = np.stack(train_images,axis = 0,)
np_labels = np.stack(train_labels,axis = 0,)
np_images = np_images.reshape((np.shape[0], 24, 24, 3))
#保存这些numpy矩阵文件
np.save(save_path+"3dtrain_images_2424.npy", np_images)
np.save(save_path+"3dtrain_labels_2424.npy",np_labels)
2. 搭建并训练神经网络
使用tensorflow搭建神经网络并不复杂,本人觉得还不如安装 tensorflow gpu 复杂。 本人推荐大家使用 anaconda 在 windows 和 mac 上配置 python 的环境,非常方便,几行代码。这里使用的是 tensorflow-gpu,训练用的是 Acer Predator Helios 500 笔记本电脑,显卡是英伟达的 GTX 1070。
如果使用的是 GTX 系列显卡,配置tensorflow-gpu前首先需要安装 CUDA,安装 CUDA 后需要查看你的gpu 驱动是否支持你的CUDA 版本,不支持的话需要更新gpu驱动。
用 conda 配置 tensorflow gpu:https://towardsdatascience.com/tensorflow-gpu-installation-made-easy-use-conda-instead-of-pip-52e5249374bc , 这个是英文版,之后我看看有没有时间把它概括一下翻译成中文。
废话不多说,下面开始搭建并训练网络—>
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import numpy as np
from tensorflow import keras
# 从本地文件夹导入数据
train_images = np.load("numpy_saves/3dtrain_images_2424.npy")
train_labels = np.load("numpy_saves/3dtrain_labels_2424.npy")
test_images = np.load("numpy_saves/3dtest_images_2424.npy")
test_labels = np.load("numpy_saves/3dtest_labels_2424.npy")
使用了 tensorflow 的 keras 模块来搭建模型。 keras 是tensorflow 底下第一个函数库,它的目的是将创建模型,神经网络层,处理数据简化。使用keras搭建神经网络模型常用的层只需要一行代码就可以,非常适合初学者。
#i = train_images[0]
#确保导入的数据中没有空的矩阵,一个空的矩阵数据可以把使整次训练失败
assert not np.any(np.isnan(train_images))
assert not np.any(np.isnan(test_images))
#Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
在tensorflow中如果训练中有一个训练数据的矩阵的值为空,它会对整个模型的weights造成极大的错误的改变,所以需要用 assert 来确认训练及测试数据集中没有为 ‘nan’ 的数据。
为了防止模型过度拟合(模型中的变量远大于它实际所需的变量,优化器过快的优化),这里将每个图片的值都从 0-255 整数 调整到了 0-1 的 float。一般来说如果一个神经网络过度拟合,它会在前几个轮回快速达到很高的准确率然后在接下来的所有轮回中止步不前。过度拟合也很有导致一个神经网络找到数据集标定的小漏洞,使其在训练集中达到高准确率但是面临实际数据低准确率。
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(24, 24,3)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(32,kernel_regularizer=keras.regularizers.l2(0.001), activation='relu'))
model.add(keras.layers.Dense(31, activation='softmax'))
model.summary()
model.compile(optimizer= "Adam",
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
以 LeNet 格式表达此神经网络
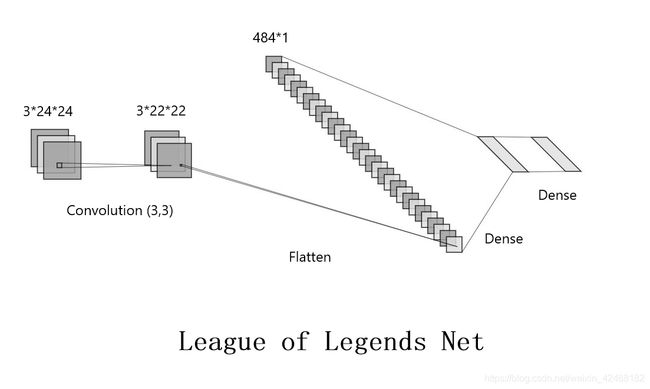
因为输入的数据比较小,所以只采用了一层卷积然后直接展开放入 Fully Connected 训练。 这个网络非常简单,第一层 Convolution 将图像的像素转换成成特征,flatten 将卷积后的 22*22 图像展开并且将一张张的图片输入进fully connected,然后使用‘’sparse_categorical_crossentropy‘’方法计算‘’loss‘’并且利用 ‘’adam’优化器来优化dense层中的比重。
至于为什么利用 33 的矩阵卷积 2424 的图像后输出会为 22*22 请看下图:
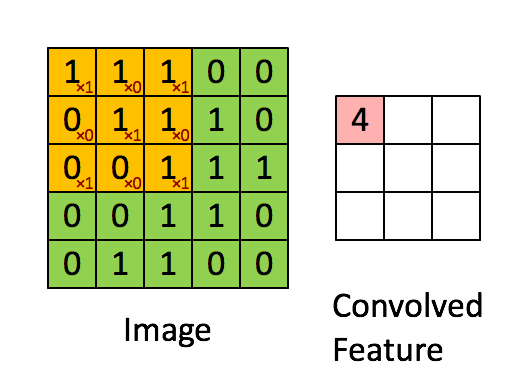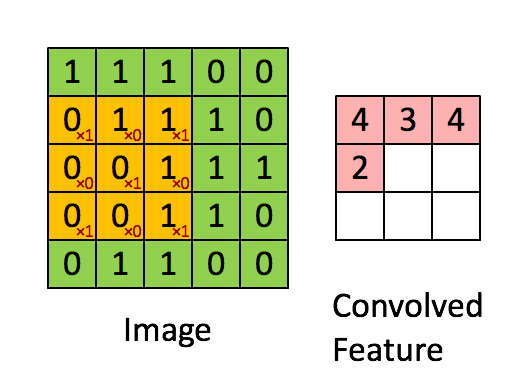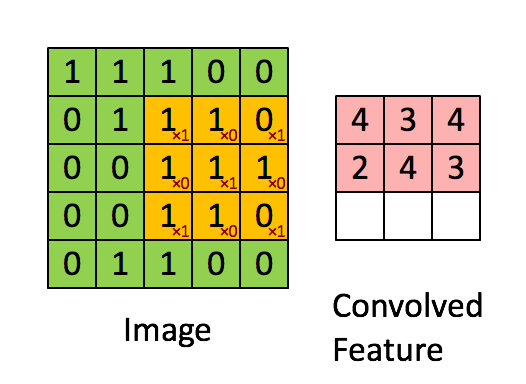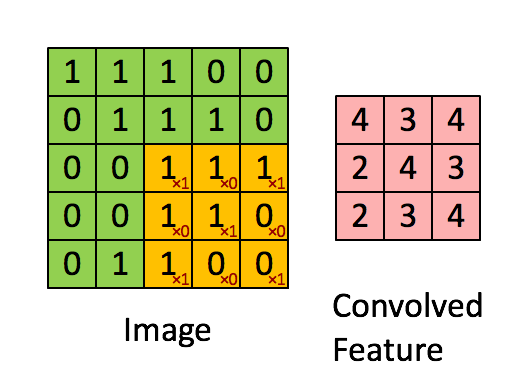
图片取自:https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
3. 检测以及保存模型
好了大功告成,让我们利用训练数据集来检测一下我们训练完的模型的准确率吧!
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('测试准确率:' + str(test_acc*100) + '%')
model.save('model/my_model.h5')
测试准确率:99.65612%
总结
亮丽之处:
- 利用图像处理提取 roi,效率高
- 训练数据量少,训练速度快
缺点:
- 目前只支持 31 个英雄
- 实际准确率有待提高
目前这个英雄联盟小地图识别器可以达到输入一张小地图图片,输出里面存在的敌方英雄以及他们的位置。这在将来有很大的计算机方面延伸研究空间,比如:
- 根据已知敌方英雄位置判断隐藏英雄位置,利用线上英雄位置的移动来判断打野位置 (CNN,RNN)
- 在职业赛场上学习某一个选手或者队伍的操作风格,帮助职业队伍针对这一风格 (RNN)
- 创建更加智能的AI,以供人类玩家锻炼提升 (RNN)
- 运用到更多的游戏,为游戏公司提供游戏中需要肉眼观测的数据
将来我会更新这个程序,让它支持更多的英雄,拥有更高的判断准确率。
谢谢阅读
3/28/2020: 我更新了新的一代,这篇文章的后续:League-X。