hands on machine learning with scikit-learn and tensorflow
reading note
CHAPTER 14: RNN
分析任意长度的序列化(sequences)数据
循环神经元
在传统神经元的基础上, 添加了上阶段输出作为本阶段的一个输入
因此, 循环神经元的输入包含两部分, 1)特征输入; 2)上阶段的输出
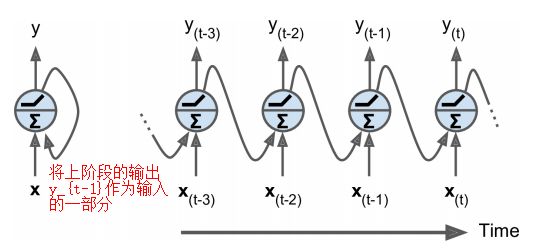
循环神经元数据的计算公式如下(也就是多了一份输入)
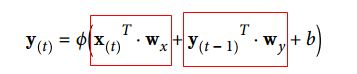
当由一层循环神经元构成时, 输出的y为一个向量(一个神经元对应一个输出)
其中, 黄色的框为一个cell(单元)

对应的计算公式为
注1: RNN输入X的形式

形象一点的输入形式
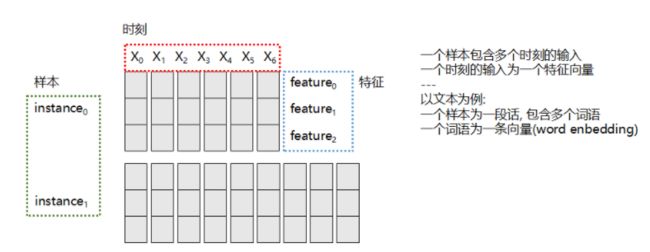
在训练模型时, 既是对参数的更新:
- 使用一个或多个样本去更新参数(SGD, MB-SGD)
- 每个样本包含多个时间的输入
- 每个时间的输入为一个向量(Word Enbedding)
注2: NN, LR与树模型的区别
- NN和LR模型的结构是确定的, 通过样本(一个或多个)去更新模型的参数, 来训练模型
- 树模型的结构是不确定的, 因此需要全部的样本来确定结构
输入与输出序列
- seq2seq(输入为序列, 输出为序列)
- 时间序列的预测, 序列生成
- 机器翻译(Encoder2Decoder)
- 语音2文字
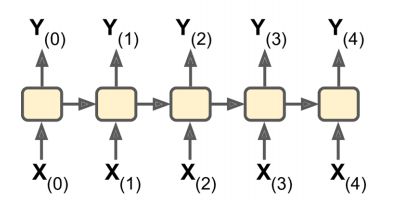
- seq2vec(输入为序列, 输出为向量(仅保留了最后的一个(输出)状态))
- 分类任务(音乐分类, 情感分类)
- 预测用户下次可能观看的电影(协同过滤)
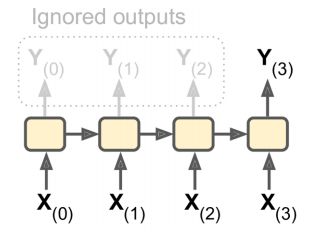
- vec2seq(输入为向量, 输出为序列)
- 给图片添加描述
- 输入歌手, 创建播放列表

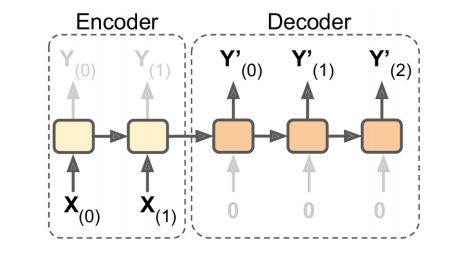
- encoder2decoder(输入为序列, 输出为序列)
- seq2seq的一种特殊形式
- 机器翻译
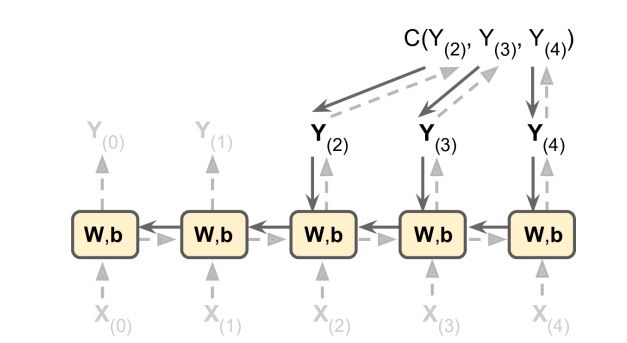
训练RNN模型
RNN的训练技巧(BPTT)
- 按时间展开
- 反向传播
虚线为正向预测过程, 实线为反向训练过程(反向传播), 每个时刻向损失函数的负梯度更新模型, 比如计算了$Y_{(2)}$的梯度, 只更新$Y_{(2)}$, 不会更新$Y_{(1)}, Y_{(0)}$; 另外, $W, b$在每个阶段都是一致的(参数共享, 这也是梯度爆炸和梯度消失的原因)
参考: RNN训练详解
当RNN用作分类时, 直接输出最后一个的状态向量, 然后连接一个全连接层, 转换为一个普通的NN模型

RNN对于长序列的训练困难
问题: 当序列较长时, 会出现
- 训练时间长(收敛困难)
- 序列越长, 相当于展开的RNN更深, 又因为RNN权值共享, 因此容易造成梯度爆炸/消失问题
- 解决方法: 限制序列长度, 但会丢失长期记忆
- 序列越长, 相当于展开的RNN更深, 又因为RNN权值共享, 因此容易造成梯度爆炸/消失问题
- 长期记忆退化, 仅保留了短期记忆
引出: 如何保存长期记忆? -> LSTM, GRU
[1] 训练时间慢: 1. 初始化参数方法; 2. 不饱和的激活函数; 3. BN; 4. 梯度修建; 5. 更快的优化方法.
LSTM Cell
LSTM对RNN的提升: 收敛更快, 能够检测出长期依赖信息
LSTM的关键思想: 网络有能力学习到哪些长期信息应该被丢弃, 哪些应该被记忆
LSTM管理了两条状态向量, 一条为长期记忆, 一条为短期记忆
LSTM包含了四个全连接层(一个输出, 三条控制), 三个门(遗忘门, 输入门, 输出门), 两条状态向量(长期记忆, 短期记忆)
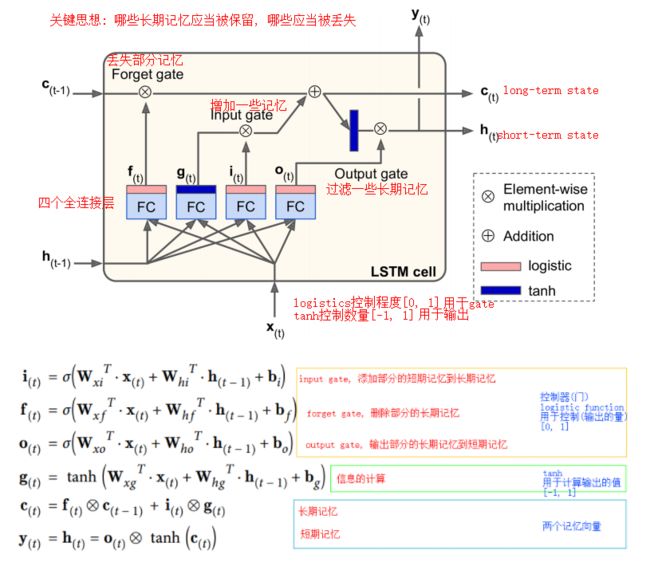
[注1] 这里可以对logistic和tanh两个激活函数的作用做一个思考:
- logistic的取值范围[0, 1], 用于gate(控制), 控制输出的量, 相当于过滤
- tanh的取值范围[-1, 1], 用于计算, 计算出输出的值
GRU Cell
LSTM的精简版本
- 合并两条状态向量为一条状态向量
- 合并了遗忘门和输入门的计算(遗忘与输入的对立)
- 没有输出门, 但是多了一个对状态输入进行过滤的门
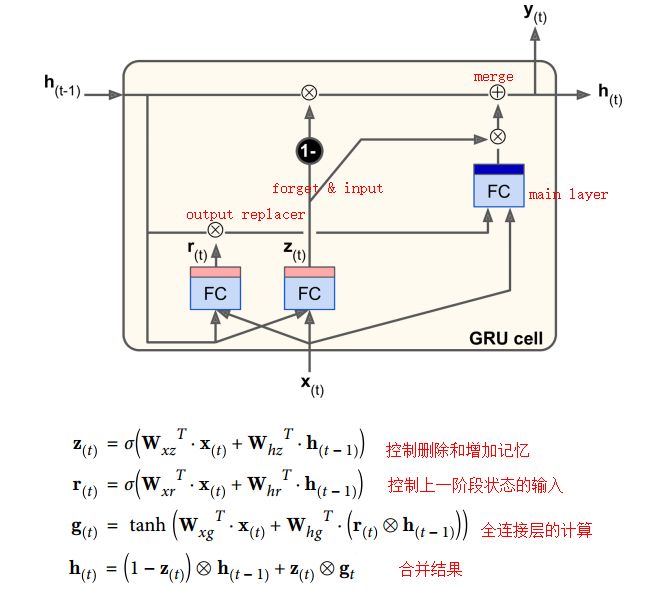
[注] 书上的最后一个公式存在错误, 付上的为修改后的公式
Word Embeddings
降低维度, 使相同的词语有相同的表示, 表示具有泛化能力, 有距离的性质
机器翻译过程(Encoder-Decoder 网络)
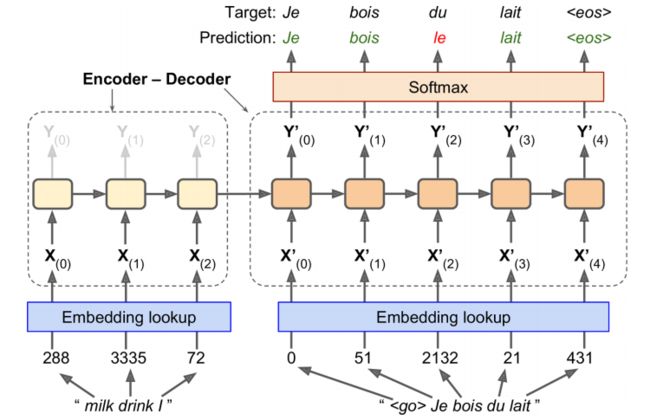
训练过程:
- 对单词进行Embedding, 转换每个单词为向量
- 训练时输入包含两个部分, 一个是原始的输入, 一个是翻译的输入
- 翻译的输入比原始的输入延后一步
- 原始的输入逆序(这里并不是绝对的, 逆序输入是为了让翻译有总结的能力, 双向的网络则有更多的信息)
- 使用softmax计算概率, 选择概率最高的词语(因此这里有一个词语个数的问题, 词语过多会造成计算复杂(解决方法, 抽样))
测试过程: 不再有翻译的输入