Spark学习笔记—Spark工作机制
一.Spark执行机制
1.执行机制总览
Spark应用提交后经历一系列转变,最后成为task在各个节点上执行。

RDD的Action算子触发job的提交,提交到Spark的Job生成RDD DAG,由DAGScheduler转换为Stage DAG,每个Stage中产生相应的Task集合,TaskScheduler将任务分发到Executor执行。每个任务对应的数据块,使用用户定义的函数进行处理。
2.Spark应用的概念
Spark应用(application)是用户提交的应用程序,执行模式有Local,Standalone,YARN,Mesos。根据Application的Driver Program是否在集群中运行又分为Cluster模式和Client模式。包含的组件如下:
Application:用户自定的Spark程序,提交后Spark为App分配资源将程序转换并执行。
Driver Program:运行Application的main()函数并创建SparkContext.
RDD Graph:当RDD遇到Action算子,将之前所有算子形成一个有向无环图DAG,在Spark中转换为Job并提交到集群中处理,一个App可以包含多个Job.
Job:一个RDD Graph触发的作业,在SparkContext中通过runJob方法提交。
Stage:每个Job会根据RDD的宽依赖关系被切分为很多Stage,每个Stage包含一组相同的Task,这一组Task也叫做TaskSet。
Task:一个分区对应一个Task,Task执行RDD中对应Stage中包含的算子。Task被封装好后放入Executor的线程池中执行。
3.应用的提交与执行方式
应用的提交方式分为以下两种:
Driver进程运行在客户端;主节点指定某个Worker节点启动Driver,负责整个应用的监控。
(1).Driver运行在客户端

流程描述如下:
1.用户启动客户端后,客户端运行程序,启动Driver。在Driver中启动或者实例化DAGScheduler等组件。客户端的Driver向Master注册。
2. Worker向Master注册,Master命令Worker启动Executor。Worker通过创建Executor-Runner线程,在ExecutorRunner线程内部启动ExecutorBackend进程。
3. ExecutorBackend启动后向客户端Driver进程内的SchedulerBackend注册,这样的话Driver进程就找到了计算资源。Driver中的DAGScheduler解析RDD DAG并生成相应的Stage,每个Stage包含的TaskSet通过TaskScheduler分配给Executor。
(2).Driver在Worker中运行

流程如下:
1.用户启动客户端,客户端提交应用程序给Master.
2.Master调度应用,针对每个应用分发给指定得一个Worker启动Driver,即SchedulerBackend。Worker接受到Master命令后,创建DriverRunner线程,在DriverRunner线程内创建SchedulerBackend进程。Driver是整个作业的主控进程
Master指定其他Worker启动Executor,即ExecutorBackend进程,提供计算资源。流程与上述相似,Worker创建ExecutorRunner线程,ExecutorRunner启动ExecutorBackend进程。
3.ExecutorBackend启动后向Driver的SchedulerBackend注册,这样的Driver就获得了计算资源。SchedulerBackend进程包含DAGScheduler,它会根据RDD的DAG拆分出Stage,生成TaskSet,并调度和分发Task到Executor。每个Stage的TaskSet都会放到TaskScheduler,其将任务分发到Executor。
二.Spark调度与任务分配模块
1.Spark应用程序之间的调度
Executor空间内每个应用是不共享的,一个Executor一个时间段只能分配给一个应用。因此应用程序之间就需要进行资源的调度。
(1).Standalone
默认情况下,采用FIFO (先进先出) 进行调度,每个应用会独占所有节点可用资源。用户可以配置spark.cores.max决定一个应用在整个集群中申请的CPU核数。
(2).Mesos
在Mesos运行模式下,若用户想要静态配置资源,可以设置spark.mesos.coarse为true,将Mesos设置为粗粒度调度模式。然后配置spark.cores.max决定集群的CPU核数以及spark.executor.memory配置每个Executor的内存使用量。Mesos还可以配置动态共享CPU core的执行模式,让mesos运行在细粒度模型下。这种模式下每个应用还是拥有独立和固定的内存分配,但当其空闲时,其他机器可以使用这些机器空闲的CPU core,该模式在集群存在大量不活跃应用情景下有用,如大量不同用户发起请求的场景下。
(3).YARN
当Spark运行在YARN平台时,用户可以配置num-executors选项控制为这个应用分配多少个executor,executor-memory以及executor-cores来控制应用被分到的每个executor占用的内存和CPU,这样可以限制提交的应用不会占用太多资源,提升YARN的吞吐量。
2.Spark应用中的Job调度
应用程序内部,不同线程提交得Job可以并行的。
(1).FIFO模式
默认情况下Spark的调度器是以FIFO(先进先出)方式调度Job。每个Job被切分成很多Stage,第一个Job优先获取所有可用资源,接下来第二个Job再获取剩余资源。若第一个Job没有占用所有资源,则第二个Job可以获取剩余资源,多个Job可以同时进行,若第一个Job占用所有资源,则第二个只能等待。
(2).FAIR模式
该模式下Spark在多个Job之间采用轮询的方式为任务分配资源,所有任务拥有大致相同的优先级来共享资源。
FAIR调度器也支持将Job分组加入调度池中调度,可以为调度池分配不同优先级。默认每个调度池拥有相同优先级。调度池中Job按照FIFO方式调度执行。
调度池配置:
调度模式:用户可以选择FIFO或者FAIR方式调度。
权重:每个调度池的权重。
minShare:该调度池需要多少CPU核就可以满足需求,剩下的分配给其他调度池。
3.Stage和TaskSetManager调度方式
(1).Stage调度
Stage的调度由DAGScheduler完成。由RDD的DAG切分出Stage的DAG,Stage的DAG通过最后执行的Stage为根进行广度优先遍历,遍历到最开始执行的Stage开始执行(最后执行的StageID最小为0,最先应该执行的StageID大,但调度机制时优先调度小的)。如果提交的Stage有还未完成的父Stage,则需要等待其父Stage执行完才能执行。DAGScheduler中有几个Key-Value集合用于确定Stage的状态。这样能避免Stage过早执行和重复提交。
waittingStages:记录仍然有未执行的父母Stage的Stage。
runningStages:记录正在执行的Stage。
failedStage:保存执行失败的Stage,需要重新执行。
(2).TaskSetManager
在TaskScheduler中对每个Stage对应的Task进行提交和调度。一个Application只有一个TaskScheduler,所有Action触发的Job的TaskSetManager都由这个TaskManager调度。
TaskSetManager调度分为两个步骤:
首先在调度池里不同Job的TaskSetManager先排序,先提交的Job的JobID小先执行。
然后每个Job内部又优先调度TaskSetManagerID小的,但是最先应该执行的是TaskSetManagerID大的,当有未执行完的Stage的TaskSetManager时,TaskSetManager则不会提交到调度池中。
4.Task调度
Task的调度由TaskSetManager完成,本质时Task在哪个节点执行。
三.Spark的I/O机制
1.序列化
序列化是将对象转换为字节流,本质上可以理解为将链表存储的非连续空间的数据存储转换为连续空间存储的数组里。
两个目的:
1)进程间通信:不同节点之间进行数据传输。
2)数据持久化存储到磁盘:本地节点将对象写入磁盘。
Spark可以使用Java的序列化库也可以用Kyro序列化库。Kyro具有紧凑,快速,轻量的优点,允许自定义序列化方法,且扩展性较好。
2.压缩
大片连续区域进行数据存储且数据重复性较高时可以考虑压缩。数组或者序列化后的数据可以压缩。
目前常用的两种压缩为Snappy和LZF,Snappy提供更高的压缩速度,LZF提供更高的压缩比。
3.Spark的块管理
RDD在逻辑上时按照Partition分块的,物理上则是以Block为单位一个Partition对应一个Block。用Partition的ID通过元数据映射到物理上的Block。物理上这个Block可以存在内存中也可以存在某个节点的磁盘的临时目录下。
整体的I/O管理分两个层次:
1)通信层:I/O模块也是采用Master-Slave结构来实现的,Master和Slave间传递控制和状态信息。
2)存储层:数据存储到内存或磁盘以及传输到远端的机器由存储层实现。
(1).实体的类
管理和接口:
1)BlockManager:当其他模块想和storage模块交互时,都要调用BlockManager接口实现。
通信层:
2)BlockManagerMasterActor:主节点创建,从节点通过这个Actor的引用向主节点传递信息和状态。
3)BlockManagerSlaveActor:从节点创建,主节点通过这个Actor的引用向从节点传递命令控制从节点的读写。
4)BlockManagerMaster:对Actor通信进行管理。
5)数据读写层:
DiskStore:提供Block在磁盘上以文件形式读写的功能。
MemoryStore:提供Block在内存上的读写功能。
ConnectionManager:提供本地机器和远端节点进行网络传输Block的功能。
BlockManagerWorker:对远端数据的异步传输进行管理。
(2).BlockManager中的通信
主节点和从节点通过Actor传递命令和状态。
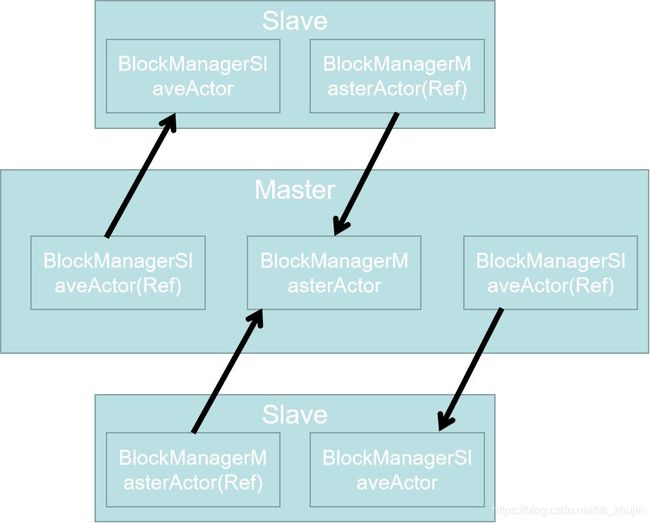
其中在Master和Slave中创建BlockManager有所不同。
1)Master端
BlockManagerMaster对象拥有BlockManagerMasterActor的Actor引用以及所有Slave端的BlockManagerSlaveActor的Ref引用。即每个Slave端都有一个BlockManagerSlaveActor的Ref引用在Master端。
2)Slave端
每个Slave端的BlockManagerMaster拥有自己的BlockManagerSlaveActor的actor引用以及Master端的BlockManagerMasterActor的Ref引用。BlockManagerSlaveActor和BlockManagerMasterActor分别在各自的actor和ref之间通信。
BlockManager在内部封装BlockManagerMaster,并通过BlockManagerMaster进行通信。每个Spark在各节点创建各自的BlockManager,通过BlockManager对storage模块进行操作,BlockManager在SparkEnv中创建。
(3).读写流程
数据写

数据写入流程主要分为一下几步(读取差不过):
1)RDD调用compute方法进行指定分区的写入。
2)CacheManager中调用BlockManager判断数据是否已经写入,若果未写入则写入。
3)BlockManager中数据和其他节点同步。
4)BlockManager根据数据存储级别写入指定的存储层。
5)BlockManager向主节点报告存储状态。
数据读
1)本地读取
本地读取首先看能否从内存中读取,如果不能读取则看能够从Tachyon中读取,如果仍然不行则看能否从磁盘读取。
2)远程读取
远程获取调用路径,然后getRemote调用doGetRemote,通过BlockManagerWorker.syncGetBlock从远程获取数据。
4.数据块读写管理
数据有三个类别的读写来源。内存=>本地磁盘=>其他节点
(1).MemoryStore内存块读写
内存Block块管理是通过链表实现的。
(2).DiskStore磁盘读写
在DiskStore中一个Block块对应一个文件,BlockID和一个文件路径进行映射,数据块读写相当于读写文件流。
四.Spark通信模块
Spark的Cluster Manager可以有Local,Standalone,Mesos,YARN等部署模式。下面主要介绍Standalone模式。
1.通信框架AKKA
Spark在模块间通信使用的是AKKA框架。其中使用的Actor之间通过消息来通信,一个Actor收到其他Actor的消息后,可以根据需要做出各种响应。Actor建立一个消息队列,每次收到消息后放入其中,每次也从其中取出消息处理。这个过程是循环的让Actor可以时刻接收和处理消息。
每一个应用创建一个ActorSystem即可。
AKKA Actor以树形结构组织,一个Actor可以把自己的任务分成更小的子任务,为了达到这个目的会开启自己的子Actor并负责监督这些子Actor。每一个Actor都会有一个自己的监督者就是创建这个Actor的Actor。
AKKA的优势:
1)并行和分布式:AKKA设计时采用了异步通信与分布式架构。
2)可靠性:本地和远程均有监督和回复机制。
3)高性能:1GB内存可以创建和保持250万个Actor.
4)去中心:区别于Master-Slave模式采用无中心节点结构。
5)可扩展性:可以在分布式环境下进行Scale out,线性扩充计算能力。
Spark中的Client,Master,Worker均是一个Actor。
2.Client,Master,Worker之间通信
Standalone模式下各模块的角色:
1)Client:提交作业。
2)Master:接受作业,并启动Driver和Executor管理Worker。
3)Worker:管理节点资源,启动Driver和Executor。
(1).模块间的主要消息
1)Client to Master
RegisterApplication:注册应用
2)Master to Client
RegisteredApplication:注册应用后回复给Client。
ExecutorAdded:通知Client Worker已经启动了Executor,当向Worker发送Launch-Executor时通知Client Actor。
ExecutorUpdated:通知Client Execurtor已经更新状态了。
3)Master to Worker
LaunchExecutor:启动Executor。
RegisteredWorker:Worker注册的回复。
RegisterWorkerFailed:注册Worker失败的回复。
KillExecutor:停止Executor进程。
4)Worker to Master
RegisterWorker:注册Worker。
Heartbeat:周期性向Master发送消息,心跳。
ExecutorStateChanged:通知Master,Executor状态已经更新。
(2).主要的通信逻辑
Actor之间,消息发送端通过“!”符号发送消息,接收端通过receive方法中的case模式匹配接受和处理消息。
五.容错机制
分布式数据有两种容错机制:数据检查点和记录数据的更新。Spark选择了记录更新的方式,但是如果更新粒度太细,那么成本也会很高。因此RDD只支持粗粒度的转换,即在大量记录上执行单个操作,将创建RDD的一系列Lineage(血统)记录下来。
1.Lineage机制
(1).Lineage简介
RDD的Lineage是记录粗粒度Transformation操作行为。当RDD的某个分区丢失时,可以通过Lineage获取足够的信息来进行回复。
(2).两种依赖
RDD在Lineage依赖方面分为两种
Narrow Dependencies:父RDD的每一个分区最多被一个子RDD分区所用,一个父RDD分区对应于一个子RDD分区或多个父RDD分区对应一个子RDD分区。
Shuffle Dependencies:子RDD分区依赖于父RDD的多个分区或所有分区,即一个父RDD的一个分区对应一个子RDD多个分区。
这两个概念主要运用在容错中和调度中构建DAG作为不同Stage的划分点。
(3).容错原理
1)Narrow Dependency
容错机制中如果一个节点死机了,而且运算的是Narrow Dependency则只需要把丢失的父RDD分区重算即可,不依赖其他节点,因为一个父RDD分区只对应一个子RDD分区。不存在冗余计算。
2)Shuffle Dependency
若一个节点死机,并且运算的是Shuffle Dependency,因为一个父RDD分区对应子RDD多个分区,这样重算父RDD分区的时候,该分区数据不是只给丢失的子RDD分区使用的,这样就存在一个冗余计算。比如一个子RDD分区需要父RDD所有分区中的数据,这样如果该子分区丢失就需要重算父RDD所有分区的数据,然后再在父RDD所有分区中找到丢失分区需要的数据聚集合并为丢失的分区。这样重算的父RDD数据中就有很多不属于丢失分区的数据也被重算了这就造成了很大的冗余计算。
2.Checkpoint机制
RDD中需要加检查点的情况:
1)DAG中的Lineage过长,如果重算开销太大。
2)在Shuffle Dependency上做检查点收益更大。
传统做检查点有两种方式:冗余数据和日志记录更新操作。
RDD中的doCheckPoint方法相当于通过冗余数据来缓存数据。在检查点(本质是将RDD写入Disk做检查点)将数据备份,然后Spark会删除以做检查点的RDD的祖先RDD依赖。为Lineage做容错的辅助,Lineage过程会照成开销过大。
六.Shuffle机制
Spark中的Shuffle像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。分为两个阶段:Shuffle Write和Shuffle Fetch阶段(该阶段包含聚集Aggregate)。在整个DAG中在每个Stage的承接阶段做Shuffle过程。

从最上端Stage2和3进行操作,每个Stage对每个分区进行流水线式的函数操作的,执行到每个Stage最后阶段进行Shuffle Write,将数据重新根据下一个分区数分成相应的Bucket,并将Bucket最后写入磁盘。
执行完Stage2和3后Stage1去存储有Shuffle数据节点的磁盘Fetch需要的数据,将数据Fetch到本地后进行用户定义的聚集函数操作,这个阶段就是Shuffle Fetch。
1.Shuffle Write
Spark中每个Stage通过任务来进行运算,Spark中只分两种任务ShuffleMapTask和ResultTask。其中ResultTask就是最底层的Stage也是整个任务执行最后阶段将数据输出到Spark执行空间的Stage,处理这个阶段执行ResultTask其他阶段都是执行ShuffleMapTask。
(1).Shuffle Write流程
Shuffle Write入口是ShuffleMapTask中的runTask方法,也是整个Shuffle Write的控制骨架。ShuffleWriter是一个抽象的特征(Trait),如HashShuffleWriter主要功能就是判断是否需要做MapSideCombine或者做普通的Shuffle,并未ShuffleWriter流程提供各种函数。
Spark支持两种类型的Shuffle:Shuffle和优化的Consolidate Shuffle(写入)
两种Shuffle主要区别在于Bucket的处理是否写入FileGroup中,FileGroup是一个文件数组,存储文件的引用,在内存中维持这些引用。
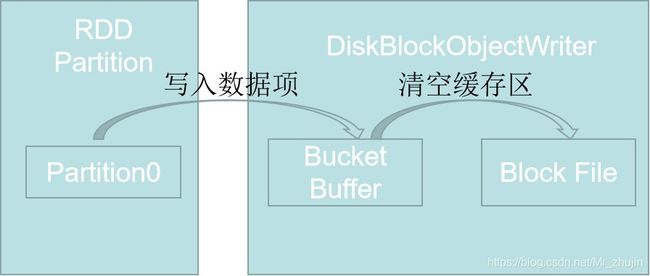
最终在HashShuffleWriter,将内存中的Bucket写入到磁盘,存储为文件,并将Shuffle的各个Bucket及映射信息返回给主节点。
(2).Shuffle和Consolidate Shuffle比较

图中为Shuffle流程,该Shuffle有三个Mapper和两个Reducer,会产生23=6个Bucket即6个Shuffle文件,产生Shuffle文件个数为MR其中M为Map任务个数,R为Reduce任务个数。

图中为Consolidate Shuffle流程,每一个Bucket并非对应一个Shuffle文件,而是对应文件中一个Segment,产生的Shuffle文件数与Spark Core个数相关。理论上将产生的Shuffle文件数为C*R其中C代表Spark集群的Core Number,R是Reducer数。Consolidate Shuffle能够显著减少Shuffle文件数,解决文件过多问题。
2.Shuffle Fetch
Reducer端的节点通过拉取写入的数据,获得需要的数据,该过程叫Fetch。Spark通过两个框架实现Fetch:NIO通过Socket连接区Fetch数据,OIO通过Netty去Fetch数据。

图中为ReduceByKey的Shuffle Fetch流程,在Stage0中将Fetch到的数据形成分区,所有分区形成Shuffled RDD,通过聚集函数将Shuffled RDD每个分区的每条数据存储到AppandOnlyMap(本质可以理解为一个哈希表),这个过程中执行的是用户自定义的聚集函数,做聚集操作,最后将形成的结果形成分区,所有分区形成MapPartitionsRDD。
Shuffle Fetch和聚集Aggregate的操作是边Fetch数据边聚集的。通过Aggregate的数据结构AppandOnlyMap(一个Spark封装的哈希表),Fetch得到每条数据,直接将其放入AppandOnlyMap中,如果该AppandOnlyMap已经有相应Key的数据,那么直接按照用户定义的聚集函数合并聚集数据。
3.Shuffle Aggregator
Spark的聚集分为两种:需要外排和不需要外排
1)不需要外排的在内存中的AppandOnlyMap中对数据进行聚集。
2)需要外排的先在内存中做聚集,当内存数据达到阈值,将数据排序后写入磁盘,由于磁盘的数据只是部分数据,最后再将磁盘数据进行合并聚集。
之所以需要外排的原因是,虽然reduce型的数据不断计算合并数据量不会暴增,但是如果是像groupByKey这样的操作,Reducer需要得到Key对应的所有Value,Spark需要把Key-Value全部存在HashMap中,并将Value合并为一个数组。必须确保每个分区足够小,内存能够存放这个分区。一般设计这种操作时,尽量增加分区数,也就是增加Reducer和Mapper的数量,可以减小分区大小,使得内存能够容纳这个分区。