但如果你想了解Java大数据平台开发、项目系统的优化实战。请继续向下阅读。
项目背景
该项目是银行自用项目,是多租户的数据查询平台。可能很多人对这个概念不是很清楚,别急,容我做个简单的介绍,就明白这个系统是干嘛的了。
项目简介
首先,整个系统是基于Dubbo的分布式系统架构,数据存储统一存储在数据仓库。数据仓库提供多种存储方式,包括MySQL、HDFS、HBSE、Hive、Impala、Spark、ElasticSearch等等。而如果让业务方去做数据存取操作,显然是非常麻烦的。所以在业务系统与数据仓库之间再搭建了一个数据查询系统——这就是本篇文章的主角。
系统架构
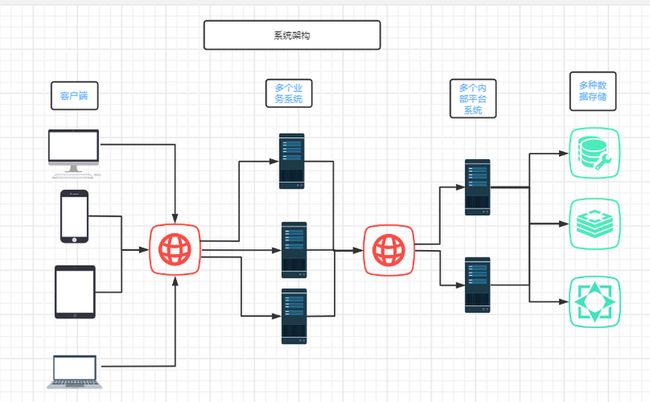
项目源码
这里会给大家展示项目的部分源码,当然,所展示的源码都是功能性的而非项目业务相关(即任何项目都可以有这些代码),大家可以先找找茬。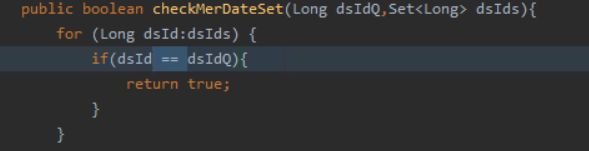

通过4张图,大家应该对该系统之前的编码水平有了大致的了解。下面我将一一解锁每张源码图的故事。
源码1:
源码1是我在做功能调试的时候发现的一个BUG,逻辑非常简单,就是比对两个id是否相等。但为什么这就产生BUG了呢?
很简单,就是包装类的缓存!
Integer和Long类型会有1个byte的缓存,即 -128 ~ 127,当比较数的返回在此之间时,因为都是使用的缓存。验证代码如下:
package demo;
public class IntegerCacheDemo {
public static void main(String[] args) {
compare(1,1);
compare(127,127);
compare(128,128);
compareWithEquals(1,1);
compareWithEquals(127,127);
compareWithEquals(128,128);
}
/**
* 错误的包装类比较
* @param a
* @param b
*/
public static void compare(Integer a, Integer b){
System.out.println(a == b ? a + " == " + b:a + " != " + b);
}
/**
* 正确的的包装类比较
* @param a
* @param b
*/
public static void compareWithEquals(Integer a, Integer b){
System.out.println(a.equals(b) ? a + " == " + b:a + " != " + b);
}
}
测试结果:
测试的结果印证了前面的说法。
众所周知, == 比较是直接比较的地址,而由于缓存的原因,包装类缓存所指向的都是同一个对象,所有 == 判断返回true,而当超出了缓存的返回,包装类的对象都是新创建的地址,使用 == 判断会返回false,而equals判断使用的是重写的equals方法,Integer的equals方法如下:
public boolean equals(Object obj) {
//判断类型是否相同
if (obj instanceof Integer) {
//如果相同则判断值是否相同,this.value存储的是int类型值, == 与
//Integer比较,会触发自动拆箱, 即等价于 int == int 判断
return this.value == (Integer)obj;
} else {
return false;
}
}再来看IntegerCache的源码吧。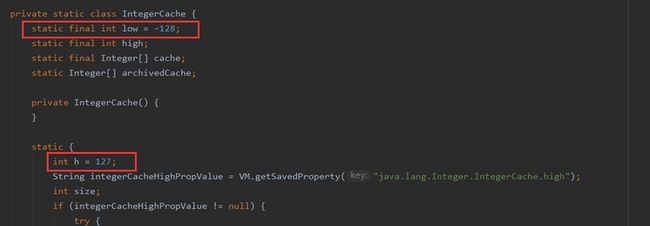
注意看全红部分,相信大家都明白了吧。 其他的包装类如Long、Short、Byte等都有对应的缓存,而且都是一个byte的取值范围。
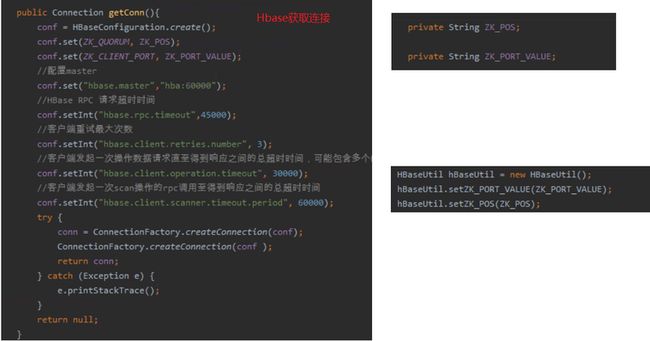
源码2:
请注意,源码2是在上线第二天就引起了线上事故。
- 业务描述
业务方通过查询接口调用查询平台,查询平台通过Zookepper访问到Hbase获取数据并返回。
- 问题排查
通过错误日志,可以查到当时有很多请求查询失败,并且偶尔会有一个查询成功,且失败数量是成线性增长的趋势。当时我就根据经验判断是连接出了问题。
果然,通过查看zookeeper日志,发现确实报连接数超过最大限制,但业务方反馈业务才上线,使用人数也就10来人。那么可以判断,代码存在BUG。
- 问题解决
首先,修改代码上线是需要经过一个流程的,不适合短时间解决。 而我们zookepper的最大连接数配置的是100,我们先将最大连接数调整到600,然后查找代码BUG修复。
通过走查代码,发现代码中有一个非常低级且致命的低级错误(大家有没有发现呢?),就是图2的try-cache中的代码,调用了createConnection(conf)方法两次,其中一个连接返回给调用者,而另外一个连接创建后则没有返回。返回的连接会在使用后正确关闭,而没有返回的连接由于永远不可能会有调用者,也就不可能手动释放,而只能等待超时自动释放,超时时间在代码中也看到了-30000ms。这就解释了为什么并发不高的情况下,连接首先挂掉了。去掉此段代码即可。
4.优化升级
请注意看上一段加粗的文字,我为什么加粗呢? 肯定是另有乾坤啊,哈哈哈哈~~~!
图2中有3个代码片段, 可以看到,整个操作流程是 : 获取配置 -> 创建Util对象 -> 创建连接 -> 查询 -> 关闭连接。
OMG!OMG!OMG! 不得不惊叹在21世纪的20年代, 居然还能看到这样的代码。OK,两个问题,其一,整个流程少了个连接池吧? 其二,util对象居然是要new出来使用。 不使用连接池的弊端无需多说,太浪费资源了。我们可以看看在单机并发下TCP连接数。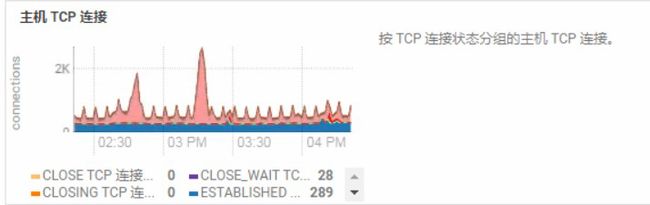
看到那个顶上去的尖了吗。 并发也不是特别高, 20线程 * 200 次循环。 可以想象,如果在生产环境,并发量如果稍微上去一点,这机器是最先扛不住的。
ok,继续整。优化思路:1、配置和工具类分离,创建配置对象,而不创建工具对象 2、 使用连接池管理连接,这一点比较好办,Hbase的Java客户端提供了连接池。经过优化,TCP连接基本比较稳定,优化代码我这里就不贴了,代码还是不少,重要的是思路而不是代码。
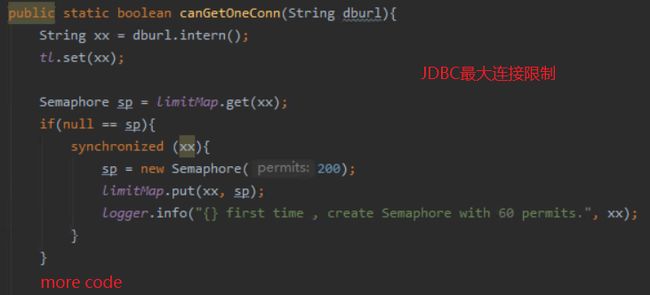
源码3 + 源码4:
源码3比较简单,就是最基本的JDBC获取连接操作,同样的问题,整个操作都是创建连接、查询、关闭连接,而没有使用到连接池。但这一点和Hbase操作又有所不同,Hbase的数据源在系统中只有一个,而JDBC的数据源就非常多了,包括MySQL、Hive、Impala都是使用JDBC来连接的,而每一个数据库就是一个数据源。这样我们系统中就会有非常多的数据源,而不是单一的数据资源管理。
而源码4我认为是比较好的代码,通过令牌池的机制限制了单台服务器的最大数据库连接数量,这种思想在高并发中也可以使用。 相对于限流的一种机制,他最大限度的保证了服务器的稳定性,不像源码2那样直接导致服务不可用。
这里的优化思路就是在一个数据源对应一个连接池,而多个数据源则对应多个连接池,然后对多个连接池进行缓存,当请求访问的时候,首先根据请求查找到对应的连接池,然后再从连接池获取一个连接返回。这样就解决了频繁创建连接的问题。这种方式暂时提升了系统的并发度,但这种方式对服务器的本地资源占用比较多,还有其他的解决方案,比如开源的中间件MyCat等。
如果你看到了这里,证明你太有耐心了 哈哈~!!