在Spark上基于Minhash计算jaccard相似度
问题引入
在风控领域常会面临一种场景:随着安全策略的打击,部分已经显露的账号/用户会被稽核、处置,要么被动地被封停,要么被坏人干脆舍弃掉。坏人会重新注册新的账号进行活跃。而这些新老账号之间很可能没有直接的交易关系,甚至连登陆设备也不同,就较难发现其关联性。但有一点是较难隐藏的:上下游的关系链。因此,可以尝试通过关系网络结构上的相似性来量化两个账号之间的关联度,从而对于风险用户关联分析起到一个补充作用。
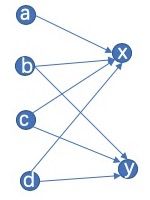
可用下图来辅助说明,x的交易流入方集合为{a,b,c,d}, y的交易流入方集合为{b,c,d},一个很自然的想法就是用Jaccard相似度来计算两个集合之间的相似度,也即:
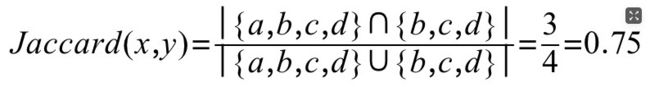
常用解法
- 暴力计算
比较容易想到的就是该表与自己做JOIN,求出交集。然后再分别计算一个节点入度数,用 x的节点入度数 + y的节点入度 - 交集节点数 得到并集的大小,那么交集大小/并集大小就得到了结果。但是以蚂蚁的数据体量而言,动辄N亿的关系对,这个计算几乎是不可行的。
- 借鉴倒排索引
在使用表的JOIN操作时,默认是不知道哪两个节点有交集的,所以会进行暴力的两两配对计算。这里可以借鉴自然语言处理中的倒排索引方法,将每个流入节点node看作一个词,得到一个索引表, 该表中的账号就有共同的流入节点,它们两两之间的交集统计值就可以+1,遍历所有的流入节点,就汇总出了两两节点之间的交集数量。
- Minhash
前面的方法都是实打实地计算,但有时候一种“足够好”的近似求解结果也是可以接受的,尤其是工程上有较大的效率提升时。Minhash就常用于近似求解Jaccard相似度。现在Spark中也有现成的包可以用,使用成本就比较可控了。
实践代码
Spark官方文档中有一段样例代码可以参考:https://spark.apache.org/docs/3.0.0/ml-features.html#minhash-for-jaccard-distance,但DEMO距离落地的成品还是有开发成本的,需要我们把数据预处理成人家指定的格式,即是说,把节点集合的向量,变成0,1 值的向量。这里有点类似于文本处理中的bag of word方法,沿着这个思路去找到spark中的CountVectorizer类,但默认是统计的频数,通过指定.setBinary(true) 实现0-1值的转换。
基于阿里的ODPS平台,完整版本的代码如下:
import com.aliyun.odps.TableSchema
import com.aliyun.odps.data.Record
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel, MinHashLSH, MinHashLSHModel}
import org.apache.spark.ml.linalg.{ SparseVector}
import org.apache.spark.odps.OdpsOps
import org.apache.spark.rdd.RDD
object minhashJaccardCal {
def main(args:Array[String]) = {
val spark = SparkSession.builder().enableOdpsSupport().enableHiveSupport().appName("minhashJaccardCal").getOrCreate()
//输入参数
val inputProject = args(0)
val inputTable = args(1)
val outputProject = args(2)
val outputTable = args(3)
val usage = s"""
Usage:
"""
if(args.length < 4){
println("参数错误")
sys.error(usage)
sys.exit(-1)
}
try{
val odpsOps = new OdpsOps(spark.sparkContext)
val pair: RDD[(String, String)] = odpsOps.readTable(inputProject,inputTable, (r: Record, _: TableSchema) => (r.getString(0),r.getString(1)) ,100)
//-----------------------------------------------------------------------------
//计算流入节点的重合度,用MINHASH的方法来近似计算,总共分成两步
//1. 数据预处理成bag of word形式的0-1向量,且用sparse向量来表示
//2. 调用org.apache.spark.ml.feature.MinHashLSH 来近似计算jaccard距离
//下面执行第1步
val inputNodeVector: RDD[(String, List[String])] = pair.map(_.swap).combineByKey(
(v : String) => List(v),
(c : List[String], v : String) => v :: c,
(c1 : List[String], c2 : List[String]) => c1 ::: c2
).repartition(100)
val inputNodeVectorDF = spark.createDataFrame(inputNodeVector).toDF("node","neighbors")
val cvModel: CountVectorizerModel = new CountVectorizer().setInputCol("neighbors").setOutputCol("features").setBinary(true).fit(inputNodeVectorDF)
val inputNodeVectorDFSparse: DataFrame = cvModel.transform(inputNodeVectorDF).select("node","features")
val inputNodeVectorDFSparseFilter = spark.createDataFrame(inputNodeVectorDFSparse.rdd.map(row => (row.getAs[String]("node") ,row.getAs[SparseVector]("features"))).map(x => (x._1,x._2,x._2.numNonzeros)).filter(x => x._3 >= 1).map(x => (x._1,x._2))).toDF("node","features")
//下面执行第2步
val mh = new MinHashLSH().setNumHashTables(100).setInputCol("features").setOutputCol("hashes")
val model: MinHashLSHModel = mh.fit(inputNodeVectorDFSparseFilter)
val inputNodeDistance: DataFrame = model.approxSimilarityJoin(inputNodeVectorDFSparseFilter, inputNodeVectorDFSparseFilter, 0.7, "JaccardDistance").select(col("datasetA.node").alias("node1"),col("datasetB.node").alias("node2"),col("JaccardDistance"))
val inputNodeOverlapRatio = inputNodeDistance.rdd.map(x => {
val node1 = x.getString(0)
val node2 = x.getString(1)
val overlapRatio = 1 - x.getDouble(2)
if(node1 < node2) ((node1, node2),overlapRatio) else ((node2, node1),overlapRatio)
}).filter(x => x._1._1 != x._1._2)
//-----------------------------------------------------------------------------
//计算流出节点的重合度, 思路与上相同
val outputNodeVector: RDD[(String, List[String])] = pair.combineByKey(
(v : String) => List(v),
(c : List[String], v : String) => v :: c,
(c1 : List[String], c2 : List[String]) => c1 ::: c2
)
val outputNodeVectorDF = spark.createDataFrame(outputNodeVector).toDF("node","neighbors")
val cvModelOutput: CountVectorizerModel = new CountVectorizer().setInputCol("neighbors").setOutputCol("features").setBinary(true).fit(outputNodeVectorDF)
val outputNodeVectorDFSparse: DataFrame = cvModelOutput.transform(outputNodeVectorDF).select("node","features")
val outputNodeVectorDFSparseFilter: DataFrame = spark.createDataFrame(outputNodeVectorDFSparse.rdd.map(row => (row.getAs[String]("node") ,row.getAs[SparseVector]("features"))).map(x => (x._1,x._2,x._2.numNonzeros)).filter(x => x._3 >= 1).map(x => (x._1,x._2))).toDF("node","features")
//下面执行第2步
val mh2 = new MinHashLSH().setNumHashTables(100).setInputCol("features").setOutputCol("hashes")
val outputModel: MinHashLSHModel = mh2.fit(outputNodeVectorDFSparseFilter)
val outputNodeOverlapRatio = outputModel.approxSimilarityJoin(outputNodeVectorDFSparseFilter, outputNodeVectorDFSparseFilter, 0.7, "JaccardDistance").select(col("datasetA.node").alias("node1"),col("datasetB.node").alias("node2"),col("JaccardDistance")).rdd.map(x => {
val node1 = x.getString(0)
val node2 = x.getString(1)
val overlapRatio = 1 - x.getDouble(2)
if(node1 < node2) ((node1, node2),overlapRatio) else ((node2, node1),overlapRatio)
}).filter(x => x._1._1 != x._1._2)
//-----------------------------------------------------------------------------
//合并到一起
val jaccardValuePair: RDD[(String, String, Double, Double)] = inputNodeOverlapRatio.fullOuterJoin(outputNodeOverlapRatio,100).map{case ((x,y),(inValue, outValue)) =>
(x,y,inValue.getOrElse(0.0),outValue.getOrElse(0.0))
}.filter(x => x._1 != x._2).distinct(100)
// 写入结果表
val saveTransfer = (v:Tuple4[String, String, Double, Double] , record:Record, schema: TableSchema) => {
record.set("srcid", v._1)
record.set("tarid", v._2)
record.set("invalue", v._3)
record.set("outvalue", v._4)
}
odpsOps.saveToTable(outputProject,outputTable,jaccardValuePair,saveTransfer,isOverWrite = true)
}catch {
case ex: Exception => {
throw ex
}
} finally {
spark.stop()
}
}
}