VS2015+Tesseract4配置与示例
接上一篇博客:Tesseract4编译,
原文链接:https://blog.csdn.net/andylanzhiyong/article/details/81746904
上次编译Tesseract4.0后,在“C:/Programe Files(x86)/tesseract/”目录下生成了目录"include","lib","bin",这些就是我们编程需要的头文件和库。没配置之前,感觉挺简单的,无非是一些头文件和库,和opencv配置差不多的。其实一大波坑在等着我.......
先在网上搜一下别人的配置,大多是直接用的Tesseract4.0安装文件,感觉不适用,看了很多篇文章,貌似找到了一篇靠谱的,原文链接:http://livezingy.com/compilation-tesseract4-in-vs2017-win10/
重点在此,如图:

前面2步整理lib时没问题。
dll感觉不需要那么多,后面再说
在整理头文件时麻烦来了,按照这个目录结构一层层去找,竟然没有“2a”文件夹...........
难道我的编译有问题?应该不会啊,cmake成功,VS里也编译成功,没道理啊......
机智如我,我在"C:\Users\username\.cppan\storage\obj"目录下用windows查找功能搜索"endianness.h",找到了。
然后在“C:\Users\username\.cppan\storage\src”目录下搜索“src”,悲剧了,找到的还是这个父目录
不知道leptonica的头文件是啥这可咋办?
难道真的是我没编译好?
迫于无奈,又重新编译了一遍,花了好几个小时,再找头文件,还是没找到.......
没辙了,看看别人编译好的头文件和库是哪些吧,又是一顿网络搜索,找到了一篇似乎靠谱的博客:
https://blog.csdn.net/yph001/article/details/78762518
按照这位老铁提供的网址下载了他的头文件和库,他的文件结构如下:


仿佛看到了希望,马上去“C:\Users\username\.cppan\storage\src”下搜索“allheaders.h”
惊喜的是:搜到了!这家伙躲在这个目录下:

然后把这个“src”整个目录拷过来,
还有个config_auto.h这个头文件,直接在“users/用户名/.cppan/”目录下搜“config_auto.h”,
也搜到了,这家伙躲在此处:

把config_auto.h也copy过来。
做到这里,想想也是够坑的,应该是cppan版本不同,然后下载这些文件后解压路径不一样,我们按前辈提供的
路径去找头文件肯定是找不到了。各位前辈说一下主要头文件是什么不就好了嘛。吐血。。。。
OCR识别文字还得有字库,下载链接:https://github.com/tesseract-ocr/tessdata,如图:

我下载了英文和中文简体,建个"tessdata"文件夹存放字库
给大家展示一下我整理的文件结构:(目前不知道动态库是哪些,在运行程序时再找)
头文件结构如下:

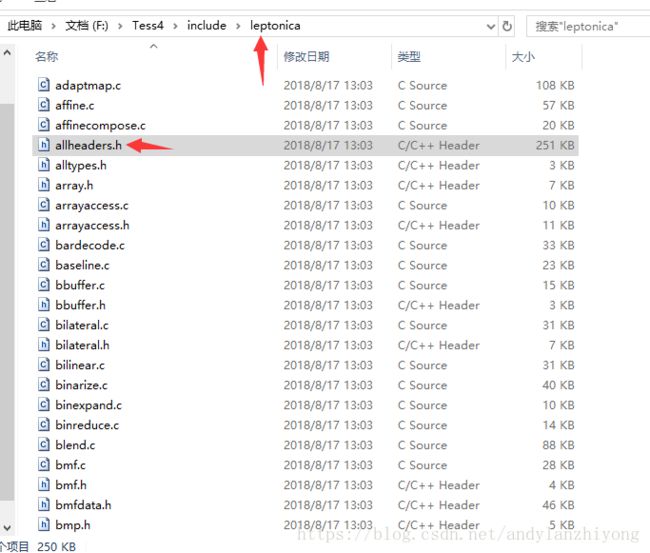
leptonica头文件很多,列一部分,注意两个重要头文件(画箭头的):

tesseract头文件也有很多,也列一部分,注意有个重要文件“capi.h”:

lib库全部copy过来:

字库文件夹"tessdata":
找的官网示例代码不能运行,编译一百多个错误,错误原因只有一个:没包含“windows.h”头文件。吐血。。。
福利来了,现贴出我将示例代码略作修改后的代码(代码中路径均为相对路径,没用环境变量):
#include
#include
#include
#include "leptonica/allheaders.h"
#include "tesseract/capi.h"
using namespace std;
void die(const char *errstr) {
fputs(errstr, stderr);
exit(1);
}
void ConvertUtf8ToGBK(char **amp, char *strUtf8) //转码
{
int len = MultiByteToWideChar(CP_UTF8, 0, (LPCSTR)strUtf8, -1, NULL, 0);
unsigned short * wszGBK = new unsigned short[len + 1];
memset(wszGBK, 0, len * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, (LPCSTR)strUtf8, -1, (LPWSTR)wszGBK, len);
len = WideCharToMultiByte(CP_ACP, 0, (LPCWSTR)wszGBK, -1, NULL, 0, NULL, NULL);
//char *szGBK=new char[len + 1];
*amp = new char[len + 1];
memset(*amp, 0, len + 1);
WideCharToMultiByte(CP_ACP, 0, (LPCWSTR)wszGBK, -1, *amp, len, NULL, NULL);
}
int main(int argc, char *argv[]) {
TessBaseAPI *handle;
PIX *img;
char *text = NULL;
//读取图片,原图像的路径
if ((img = pixRead("test.jpg")) == NULL)
die("Error reading image\n");
handle = TessBaseAPICreate();
//加载字库及设置语言
if (TessBaseAPIInit3(handle,"../tessdata", "eng+chi_sim") != 0)
die("Error initialising tesseract\n");
//设置图片及识别
TessBaseAPISetImage2(handle, img);
if (TessBaseAPIRecognize(handle, NULL) != 0)
die("Error in Tesseract recognition\n");
if ((text = TessBaseAPIGetUTF8Text(handle)) == NULL)
die("Error getting text\n");
char *pResult = NULL;
ConvertUtf8ToGBK(&pResult, text); //对结果转码
cout << pResult << endl; //输出OCR识别的文本信息
delete pResult;
system("pause");
TessDeleteText(text);
TessBaseAPIEnd(handle);
TessBaseAPIDelete(handle);
pixDestroy(&img);
return 0;
}
头文件和lib库配置不用说了,和opencv配置差不多
按需为字库设置环境变量TESSDATA_PREFIX(本示例用的相对路径未用环境变量),值为字库文件的目录。
本示例工程 Tess4Test 文件结构如下:(tessdata为字库文件)

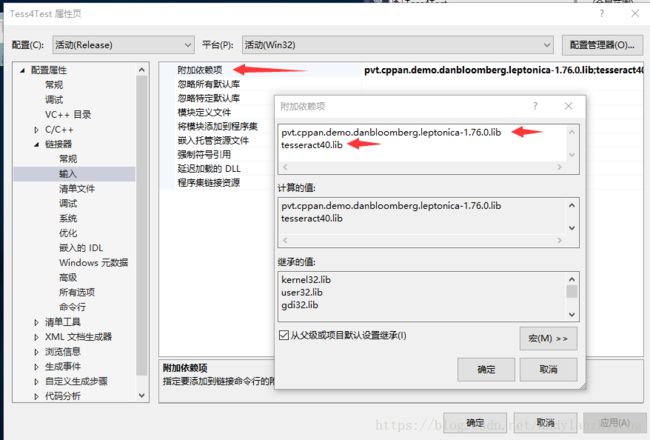
项目配置如下:

此时由于还不知道有哪些动态库,运行时会有错误,如图:
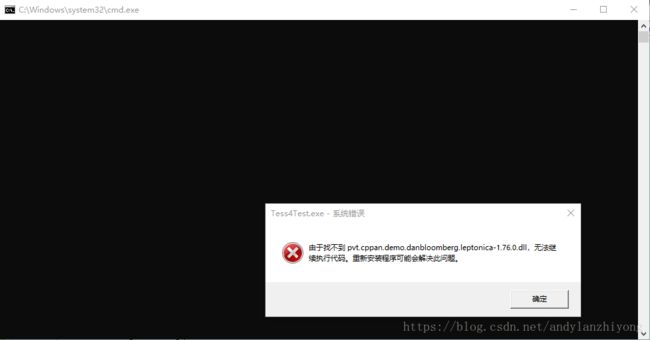
根据这些错误提示去搜相应的dll文件,
tesseract40(d).dll在“C:\Program Files (x86)\tesseract\bin”目录下搜索到
其它的dll在“C:\Users\用户名\.cppan\storage\bin”目录下搜索到
一共9个dll放到Debug/Release文件夹下(或者系统目录):

上一张测试图片:

运行后输出结果:

这张中、英文、数字混合的图片识别率在90%以上,还算可以了
到此,配置成功!
如需本示例的打包程序,请至https://download.csdn.net/download/andylanzhiyong/10616943下载。
下载后无需配置任何环境变量,头文件、库、字库都已打包好,只要你电脑装有VS2015就可以正常编译、调试、运行。
***************** 以上为个人吐血整理,堪称全网最详细!如有转载,请标明出处! *******************
另外,目前在网络上搜索Tesseract4的学习资料基本没有,看它的源码头文件中的函数声明,
这几百个函数连个注释都没有,这将又是一个大坑,探索之旅还很漫长。。。。

网友如有Tesseract4的学习资料,还望能发个链接一起互相学习。