基于深度学习的药盒药名识别技术研究
刘丹阳 张凤生 孟特 丁彦强





摘要:在智能化药房中,为完成对药品存/取操作,需要为机器人配备视觉系统来实现对目标药品的定位与名称识别。对基于深度学习的文本检测与文字识别方法进行理论分析与实验,采用CRAFT算法检测药品文本区域,根据药名文本的特征检出并截取药名区域;基于LSTM的Tesseract-OCR对药名进行文字识别。对202个实物药盒进行的识别实验表明,对药名区域检测截取的准确率为98.02%;对药品名称的识别中,常规字体的准确率可以达到91.09%,对进一步研究提高识别效果具有参考意义。
关键词:图像处理;文本检测;文字识别;深度学习;OpenCV
中图分类号:TP317
文献标志码:A
文章编号:1006-1037(2021)01-0029-05
通信作者:张凤生,男,博士,教授,主要研究方向为测控技术与智能仪器。E-mail:fszhang1994@163.com
随着自动化、信息化与智能控制技术的不断进步,自动化药房系统的研究与产品开发已引起广泛关注。自动化药房系统由药品存取机器人和药品信息化管理系统组成,以机器人替代传统的人工取药,不仅可减轻药剂师的工作强度、提高发药效率、降低药品发错几率,而且可充分利用药房空间[1-4]。机器人取药的关键是准确判断目标药品的存放位置与药品名称。当然,利用条码扫描很容易识别药品,但由于不同药品包装的条码位置不同,有时需要先翻转药盒和确定条码位置;而药品包装盒平放(自动化药房的摆放方式)时,其名称一定位于上表面,位置固定,因此只需采集药盒上表面图像即可对药品名称进行识别。为了能够处理任意方向文本、曲线文本、畸变文本,增强文字识别的泛化能力,有效防止误检,本文采用CRAFT算法与OCR技术相结合,对药品名称进行识别,以提高识别的效率和准确率。
1 目标药盒文字识别思路
对目标药盒药名的文字识别包括文本检测和文字识别两部分。近年来,随着神经网络受到越来越多的关注与研究,基于深度学习的文本检测算法不断出现。目前基于深度学习的文本检测主要有基于区域建议、基于图像分割和基于形态等方法[5]。
本文采用韩国Clova AI研究人员提出的基于单字和字间亲和度的CRAFT算法[6],基于形态的方法,比以往的文本检测算法更具有鲁棒性,能处理任意方向文本、曲线文本、畸变文本,具有很强的泛化能力。为精确定位自然图像的每个字符,该算法训练了一个深度神经网络来预测字符区域和字符间的亲和力,并采用弱监督方式训练模型。在检测到所有文本区域后,按药品名称的文本特征确定药名区域。
确定了文本区域后,对区域内的文字进行识别[7],这是视觉感知中的核心技术,目的是从图像中提取文字信息。文中采用CRAFT算法与OCR(Optical Character Recognition,OCR)技术相结合,对药品名称进行识别。整个识别过程分为图像预处理、文本区域检测、文字识别三部分,如图1所示。
2 图像预处理
图像预处理包括灰度化、滤波降噪、图像锐化、边缘检测、查找轮廓并裁剪。
(1)灰度化。将原彩色图像fx,y转化为灰度图像f1x,y的过程。在图像处理中,将各种格式的图像转化为灰度图像以使后续的图像处理计算量少,提高处理速度。本文采用平均值法,将彩色图像中三个分量亮度求平均得到灰度图。经过灰度化的图像仍可以反映整幅图像的整体和局部的色度和高亮等级的分布和特征。
(2)滤波降噪。鉴于药盒图像采集环境条件良好,噪声以高斯噪声和椒盐噪声为主。中值滤波运算简单且速度快,在滤除椒盐噪声的同时能保护图像的边缘、锐角等细节信息,但其对高斯噪声的抑制能力较弱。而高斯滤波对于抑制高斯噪声非常有效,通过合理设定高斯滤波模板方差,使得平滑效果更柔和,邊缘保留也更好,故文中采用高斯滤波,滤波模板大小为5×5。
(3)图像锐化。高斯滤波属于低通滤波,对图像中的高频分量(图像中的边缘、跳跃部分以及椒盐噪声等)衰减较强,使边缘、局部细节变的平缓,甚至模糊,其实质是图像受到平均运算或积分运算,因此需对图像进行逆运算,如微分运算,以便突出图像细节,使图像变得更为清晰。拉普拉斯算子是一种微分算子,其应用可增强图像中灰度突变的区域,减弱灰度的缓慢变化区域。
对于滤波降噪后的图像f2x,y,其拉普拉斯算子[8]定义为
最后的锐化公式为
其中,f3x,y为锐化输出图像;系数c代表要加上(或减去)多少细节。图像增强处理过程是先提取细节,然后再加(或减去负细节)到原图中。进行增强时,算子模板中心为正,则“原图+边缘图”;算子模板中心为负,则“原图—边缘图”。
(4)边缘检测。边缘检测采用Canny算法,其检测过程分4步:①计算图像中每个像素的梯度幅值和方向;②应用非极大值抑制算法消除边缘检测带来的杂散响应;③应用双阈值法划分强边缘和弱边缘;④消除孤立的弱边缘,输出边缘检测结果。
(5)轮廓查找并提取。找到包含药盒的最小凸包的四个顶点,同时求出包含四个顶点的最小矩形框,计算外接矩形的横纵比例、轮廓面积、周长等数据,然后利用这些数据实现特定几何形状轮廓的查找与过滤,为后续的处理与分析,剔除不正确的区域而保留候选对象。图2为预处理过程示意图。
3 文本区域检测
查找到药盒轮廓并裁剪后,为识别药品名称,首先确定文本区域,找出并截取药名区域。
3.1 文本检测
基于神经网络的场景文本检测是目前广泛应用的文本检测方法[9-11]。本文采用字符级的文本检测算法CRAFT,这是一种新的场景文本检测方法,通过挖掘每个字符和字符之间的亲和度有效地检测文本区域。
CRAFT算法是先检测单个字符及字符间的连接关系,然后据此确定最终的文本行。该算法以基于VGG-16的全卷积神经网络作为主干网络,解码器部分采用了U-net的方法,采用自顶向下的特征聚合方式,最终输出两个通道:region score map和affinity score map,分别为单字符中心区域的概率和相邻字符区域中心的概率,得到原图大小1/2的预测图。网络结构如图3所示。
在生成文本边框的过程中,有常规矩形和非常规矩形两种情况。
(1)常规矩形。①首先对0~1之间的概率图,affinity score map(一种高斯热图,代表该像素是相连字符之间空间的中心点的概率)和region score map(一种高斯热图,代表该像素是字符中心点的概率)分别进行取二值化阈值计算,然后将两个二值化map求并集得到一张mask图;②使用连接组件标签(CCL)进行区域连接;③最后使用OpenCV的MinAreaRect(最小外接矩形)去框出最小的四边形区域。
(2)非常规四边形,示意图见图4。①先找到扫描方向的局部最大值;②连接所有局部最大值上的中心点叫做中心线;③然后将局部极大值线旋转至于中心线垂直;④局部极大值线上的端点是文本控制点的候选点,为了更好地覆盖文本,将文本最外端的两个控制点分别向外移动局部极大值线的半径长度作为最终的控制点。
3.2 药品名称区域定位
在利用CRAFT算法检测到所有文本区域后,还需对药名区域进行定位。经过对大量药盒的统计发现,药盒文本区域中,药名区域字体较大,包含药名的矩形区域的宽度明显大于其他文本区域。据此,采取的定位思路:将检测到的所有文本区域按宽度排序,找到前三名。为防止有误检,或存在极少数非药名区域宽度大于药名区域的特例,加入第二个条件,矩形区域的长宽比例要大。满足以上两个条件的第一位的结果就作为药名的区域。通过对收集的202个药盒进行检测实验,对药名区域定位的准确性为98.02%,有四个药盒出现错误,经过观察发现,是由于这四个药盒的药名是分两行书写的,本算法为行检测,检测时将药名当成两行文本检测,导致识别出现错误。图5为实际药盒药品名称区域定位检测结果。
4 文字识别方法与结果分析
文字识别的目标是已定位的药名区域内的文字,主要问题是如何将一串文字图片转录为对应字符。本文采用Tesseract-OCR进行文字识别,并与百度OCR作对比。
4.1 Tesseract-OCR与百度OCR
Tesseract[12-15]是一款文字识别引擎,最早由惠普实验室开发,现在由谷歌负责维护。与传统Tesseract3不同,本文使用的Tesseract5.0增加了一个基于OCR引擎的新神经网络(Long Short Term Memory Network,长短时记忆网络,缩写LSTM)。
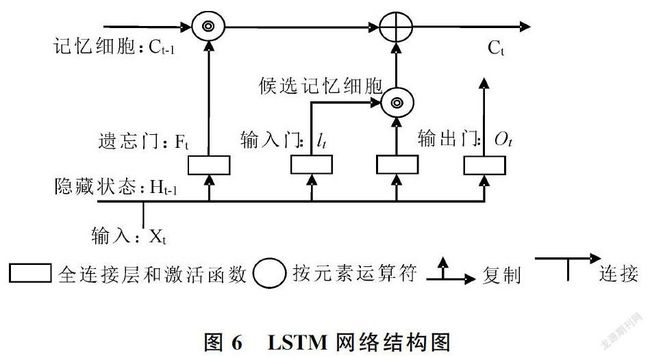
LSTM是一种改进的循环神经网络(Recurrent Neural Network, RNN),解决了普通RNN在实际应用中很难处理长距离文本的缺陷。LSTM主要由3个门组成,分别为输入门、遗忘门和输出门,同时包含隐藏状态的细胞,用于记录额外的一些信息,LSTM的网络结构如图6所示。
百度OCR是目前基于深度学习的较为成熟的文字识别技术,能够适应不同业务场景对识别速度以及精度的要求。识别部分首先是环境准备,需要安装Python的百度接口的库:pip install baidu-aip。将需要识别的图片放入picture文件中,并将识别内容保存在txt文件中。
4.2 实验结果及分析
共采集了202个药盒进行实验。通过两种不同OCR技术进行识别,结果如表1。
实际检测实验表明,本文的CRAFT文本检测与Tesseract-OCR相结合的药名识别方法,药名定位准确率达98.02%,药名文字识别准确率,本文的Tesseract-OCR方法与百度OCR相比,识别准确率较低,主要原因有以下两点:(1)百度OCR是百度公司较为成熟的人工智能技术,经过了大量训练以及语义模型纠错,能够适应不同的场景,并且针对图像倾斜、翻转等情况进行优化,鲁棒性强,可支持2万多大字库,其文字识别准确率高。(2)不同药盒上文字的字体不尽相同,差异比较大;识别错误的情况多出现于非常规字体中,而对于常规字体,如宋体、黑体等字体则识别准确率高,例如,对于112个常规字体药盒,Tesseract-OCR的识别准确率为91.09%。
5 结论
本文将CRAFT算法与Tesseract技术相结合,给出了一种药品名称识别方法。该方法首先对药盒图像进行灰度化、滤波降噪、锐化、边缘检测等常规化的预处理,然后分别利用CRAFT算法和Tesseract技术进行药盒文本区域的检测和文字识别。对202个实物药盒的检测实验表明,该方法对单行书写药名的文本区域检测准确率为100%,对分两行书写的药名无法识别;对药品名称的文字识别准确率与字体形式有關,对于常规字体,识别准确率为91.09%。进一步的研究一是扩展CRAFT算法的文本区域检测可覆盖到两行文本;二是加大检测样本数量,扩展训练药品名称字体库,以提高文字识别准确率。
参考文献
[1]程堂灿.基于双目视觉的药房取药机器人系统设计与研究[D].青岛:青岛大学,2019.
[2]王敬,张凤生,刘丹阳等.基于双目视觉的目标药盒边缘识别与定位方法[J]. 青岛大学学报(自然科学版). 2020,33(2): 38-44.
[3]谢家隆,陈敏仪,谢彦媛.医院物流机器人在智能化药房中的应用[J].中国卫生标准管理.2020, 11(11):20-22.
[4]郝奕清.药盒图像识别系统的设计与实现[D].南京:南京理工大学,2017.
[5]刘树春,贺盼,马建奇,王佳军等.深度实践OCR基于深度学习的文字识别[M].北京:机械工业出版社,2020.4.
[6]BAEK Y, LEE B, HAN D, et al. Character region awareness for text detection[J]. 2019 IEEE/CVF Conference on Computer Vishon and Pattern Recognition(CVPR),Long Beach,2019:9365-9374.
[7]王炳琪,吴则举.基于改进的CNN的啤酒瓶盖字符识别[J]青岛大学学报(自然科学版).2020,33(3):34-42.
[8]裴仁静.基于拉普拉斯金字塔的图像细节增强[J]. 计算机光盘软件与应用,2012(3):166+168.
[9]付飞飞.场景文字识别算法的研究[J].福建电脑,2020, 36(4):1-4.
[10] 张博宇.自然场景下的文本检测与识别方法研究[D].吉林:东北电力大学,2020.
[11] 徐本朋.基于深度学习的场景文本检测方法研究[D].合肥:安徽大学,2020.
[12] 李飞,盛刚,毕佳佳.基于Ctpn及Tesseract的分纤箱喷码识别技术[J].电脑知识与技术,2020, 16(13):18-19+27.
[13] 郭室驿.基于OpenCV和Tesseract_OCR的英文字符算法研究[J].电脑编程技巧与维护,2019(6):45-49.
[14] 张伟超,肖中俊,严志国.基于Opencv和Tesseract的行驶证识别系统设计[J].齐鲁工业大学学报. 2020, 34(1): 47-52.
[15] 刘丽媛,刘宏展.复杂背景下仪表信息的图像识别研究[J].激光杂志.2020, 41(4):66-69.