深入了解ConcurrentHashMap
深入了解ConcurrentHashMap
属性及默认值
//默认初始容量 16
static final int DEFAULT_INITIAL_CAPACITY = 16;
//默认加载因子 0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//默认的并发度 16 ->segments数组的大小
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
//容量的上限->segments数组的大小
static final int MAXIMUM_CAPACITY = 1 << 30;
//Segment中HashEntry数组的最小值
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
//Segment的最大值,最大的并发度
static final int MAX_SEGMENTS = 1 << 16; // slightly conservative
//锁重入的次数
static final int RETRIES_BEFORE_LOCK = 2;
//主要作用于keyhash过程
final int segmentMask;
final int segmentShift;
//存储数据节点的位置。Segment的数组
final Segment<K,V>[] segments;
//获取key对应集合
transient Set<K> keySet;
//获取key-value键值对集合
transient Set<Map.Entry<K,V>> entrySet;
//获取value的集合
transient Collection<V> values;
//segment的锁是ReentantLock锁的子类
static final class Segment<K,V> extends ReentrantLock implements Serializable {
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
//存放数据
transient volatile HashEntry<K,V>[] table;
//存放数据的个数
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}
//HashEntry的结构
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
默认情况下ConcurrentHashMap用了16个Segment的结构(HashEntry的数组),每一个Segment又拥有一个独占锁,对同一个segment下的操作存在互斥,不同的segment之间是相互独立的,不存在并发的问题,也就是:ConcurrentHashMap下同一时刻至少可以是16个线程(默认并发度)进行并发操作

构造函数
//通过初试容量、加载因子、并发度来创建ConcurrentHashMap实例
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
//对加载因子,初始容量,并发的最小值做限制
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
//并发最大值做限制
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
//记录ssize的左移的次数
int sshift = 0;
//ssize的值是有concurrencyLevel类决定的,大小为大于concurrencyLevel的最小的2的N次方
int ssize = 1;
//concurrencyLevel=17,
// 1< 17 sshfit =1, ssize=2;
//2<17 sshfit=2,ssize=4
//4<17 sshfit=3,ssize = 8
//8<17 sshfit=4,ssize= 16
//16<17 shhfit=5,ssize=32;
//32<17 break ssize = 32 ,sshfit=5
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
//段偏移量
this.segmentShift = 32 - sshift;
//散列算法的掩码,默认情况segmentMask=15
this.segmentMask = ssize - 1; //1111111->key的hash需要segmentMask
//容量上限
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//c记录每个segment上要记录的元素
int c = initialCapacity / ssize;
//加入有余数,则Segment进行+1
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c) //保证HashEntry数组是2的倍数
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
//创建ssize长度的Segment的数组,默认初始情况下是16
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
//将所有的Segment进行初始化
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
//通过集合来创建ConcurrentHashMap的实例
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY),
DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
putAll(m);
}
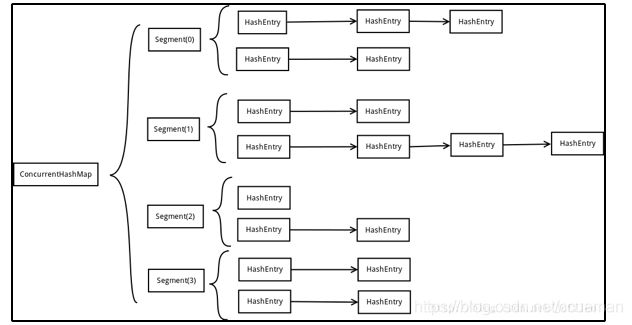
ConcurrentHashMap的结构
put方法
public V put(K key, V value) {
Segment<K,V> s;
//ConcurrenthashMap中key和value都不能为null,否则会抛出NullPointerException
if (value == null)
throw new NullPointerException();
int hash = hash(key);
//key存储的segment数组的索引位置
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
//通过位置j获取当前的segment的实例
s = ensureSegment(j);
//在对应的segment中进行插入数据
return s.put(key, hash, value, false);
}
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
//如果通过索引位置获取的segment,存在直接返回,返回为null,需要创建segment的实例
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
内部的put操作
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//尝试性加锁,加锁失败scanAndLockForPut进行重试加锁机制,在指定的重试次数后还无法获取锁就直接进行Lock强制获取锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
//找到对应segment下的table数组上的索引位置
int index = (tab.length - 1) & hash;
//通过index位置周到对应位置
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {
oldValue = e.value;
//putIfAbsent false:返回旧值,将value值直接进行替换(put实现逻辑),true:直接返回旧值(putIfAbsent)
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}else {
//当前的索引位置没有节点,后者是没有找到key相同的节点
if (node != null)
//找到key相同的节点
node.setNext(first);
else
//当前的索引位置没有节点
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
//扩容:只对segment内的HashEntry的数组进行扩容,Segment数组在构造函数指定后就不在改变了
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
return oldValue;
}
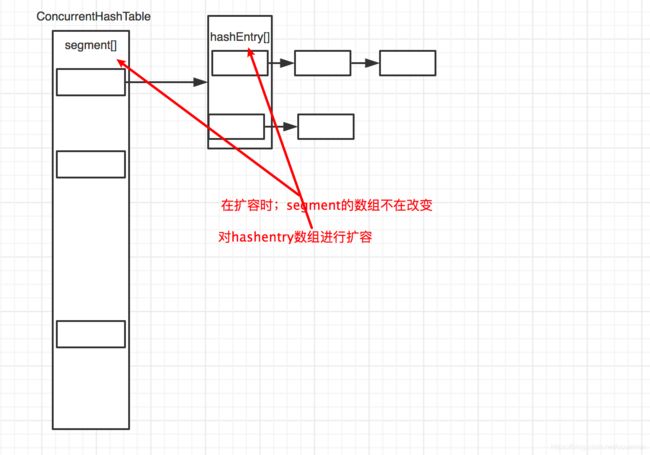
put操作通过对每一个segment加锁类保证每一个segment能做到线程安全,而segment间是相互独立的,互不影响,通过segment来做法并发的处理
get方法
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
借助于分段锁的概念(Segment)对Concurrent中的每一个单独的segment进行加锁处理,既能保证并发量,也能保证数据操作的安全性问题
HashMap与ConcurrentHashMap的区别
- HashMap不是线程安全的,而ConcurrentHashMap是线程安全的。
- ConcurrentHashMap采用锁分段技术,将整个Hash桶进行了分段segment,也就是将这个大的数组分成了几个小的片段segment,而且每个小的片段segment上面都有锁存在,那么在插入元素的时候就需要先找到应该插入到哪一个片段segment,然后再在这个片段上面进行插入,而且这里还需要获取segment锁。
- ConcurrentHashMap让锁的粒度更精细一些,并发性能更好。