drbd高可用服务(实现数据同步)
基本介绍
drbd(distrbuted replicated block device):分布式复制块设备
类似 rsync + inotify 的架构:inotify基于文件系统上层,当文件系统中有数据发生变化,就调用rsync服务,将文件系统中的文件同步到备库。
涉及对象
drbd 中的块设备可以是磁盘分区,lvm逻辑卷,或整块磁盘等。
原理
drbd软件工作位置是在文件系统层级以下,比文件系统更加靠近操作系统内核及IO栈。
基于网络的raid-1,当我们将数据写入本地磁盘系统时,数据还会被实时发送到网络中另一台主机中,以相同的形式记录在另一个磁盘系统中,使得本地(主节点)与远程主机(备节点)的数据保持实时数据同步。
如果本地系统出现故障,那么远程主机上还会保留有一份和主节点相同的数据备份可以继续使用。不会数据不会丢失。还会提升访问数据的用户访问体验(直接接管提供服务,降低宕机修复时间)。drbd服务的作用类似于磁盘阵形里的raid1功能,就相当于把网络中的两台服务器做成了类似磁盘阵列里的raid1一样。
Drbd工作原理图:
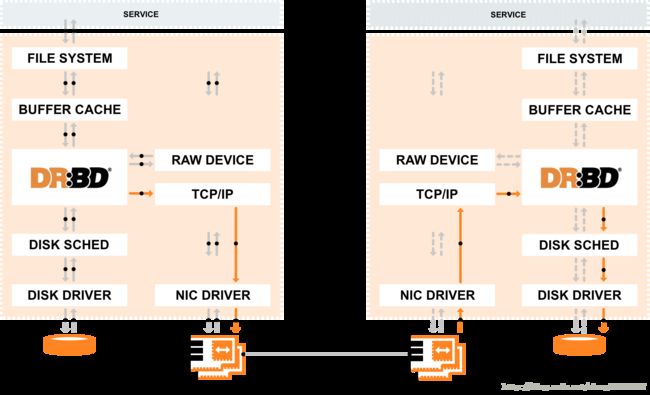
1.SERVICE 将数据写入==> FILE SYSTEM ==> BUFFER CACHE ==> DRBD
2.DRBD分两条路走,一条是通过磁盘驱动DISK DRIVER写入到磁盘
3.另一条通过tcp/ip协议,将数据通过网卡将数据发送到备节点...
两种工作模式
1)实时同步模式:
当数据写到本地磁盘和远端服务器磁盘都成功后才会返回成功写入。DRBD服务协议C级别就是这种模式,可以防止本地和远端数据丢失和不一致,此种模式是生产环境中最常用的模式。
2)异步同步模式:
当数据写入到本地服务器成功后就返回成功写入,不管远端服务器是否写入成功。
还可能是数据写入到本地服务器或远端服的buffer成功后,返回成功,就是DRBD服务协议的A,B级别
提示:在nfs网络文件系统的时候也有类似的参数和功能。例如:nfs服务参数sync和async,mount挂载参数也有sync和async。
DRBD的3种同步复制协议
协议A:异步复制协议。本地写成功后立即返回,数据放在发送BUFFER中,可能丢失。
协议B:内存同步(半同步)复制协议。本地写成功并将数据发送到对方后立即返回,如果双机掉电,数据可能丢失(mysql5.5以上支持)。
协议C:同步复制协议。本地和对方服务器磁盘都写成功确认后返回成功。如果单机掉电后单机磁盘损坏,数据都不会丢失。
工作中一般用协议C。选择协议将影响流量,从而影响网络延时。
DRBD的生产应用模式
单主模式及主备模式,为典型的高可用性集群方案。
复主模式:需要采用共享cluster文件系统,如gfs和ocfs2。用于需要从2个节点并发访问数据的场合,需要特别配置。
DRBD的企业应用场景
生产场景中会有很多基于高可用服务器对drbd的数据同步解决方案。
例如:heartbeat+drbd+nfs/mfs/gfs,heartbeat+drbd+mysql/oracle等。实际上drbd可以配合任意需要数据同步的所有服务的应用场景。
相关数据同步工具介绍
1) Rsync(sersync,inotify,lsyncd)
2) Scp
3) Nc
4) Nfs
5) Union双机同步
6) Csync2多机同步
7) 软件自身同步机制(mysql,oracle,mongdb,ttserver,redis...)
8) Drbd
补充:
Oracle dg分为基于物理block和逻辑block
逻辑:基于sql,类似mysql
物理:基于block块
从8i到10G都是这样的方式,特点是备节点不能提供服务,只能让备节点断开同步,以readony的方式打开,提价查询服务。
从11G开始,oracle就像mysql一样,主库可以写,从库可以读,11G为什么可以实现,是因为主要还是基于服务层来同步的。
而drbd因为是基于block块的,太底层了,主节点可以提供读写服务,而备节点的磁盘分区是处于非可见状态的。
Drbd服务部署
1. 环境准备
操作系统:centos5.4/centos6.4 64bit
| 操作系统 |
其他 |
| Centos5.4 |
适合drbd8.3 yum安装 |
| Centos6.4 |
适合drbd8.4 |
Drbd服务网上及IP资源配置
原则上:drbd服务网卡的配置和heartbeat服务一样,但是无需外部IP
| 名称 |
接口 |
IP |
用途 |
| master |
Eth0 |
192.168.56.10 |
外网管理IP,用于waqn数据转发 |
|
|
Eth2 |
|
|
|
|
Eth1 |
10.0.0.10 |
用于服务器间心跳以及数据同步(直连) |
| vip |
|
|
用于提供应用程序A挂载服务 |
| backup |
Eth0 |
192.168.56.20 |
外网管理IP,用于waqn数据转发 |
|
|
Eth2 |
|
|
|
|
Eth1 |
10.0.0.20 |
用于服务器间心跳以及数据同步(直连) |
| vip |
|
|
用于提供应用程序B挂载服务 |
配置主机名与hosts
sed -i ‘/HOSTNAME/d’ /etc/sysconfig/network
echo “HOSTNAME=data-1-1” >> /etc/sysconfig/network
基础准备:
/etc/init.d/iptables stop
setenforce 0
时间同步
2. 下载安装drbd并加载到内核
下载并安装epel包yum方式
方式一:
Wget http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm
Rpm -ivh epel-release-6-8.noarch.rpm
Rpm -qa|grep epel
# yum installl kernel-devel kernel-headers flex drbd84-utils komd-drbd84
方式二:
Wget http://oss.linbit.com/drbd/8.4/drbd-8.4.4.tar.gz
Tar -xf drbd-8.4.4.tar.gz
Cd drbd-8.4.4
./configure --prefix=/application/drbd8.4.4 --with-km --with-heartbeat --sysconfdir=/etc
# --with-km enable kernel module
# --with-heartbeat enable heartbeat intergration
# --sysconfdir config file directory
# ls -ld /usr/src/kernels/$(uname -r)'-'$(uname -m)/
make KDIR=/usr/src/kernels/$(uname -r)'-'$(uname -m)/ #指定内核源码路径
make install
lsmod |grep drbd
modprobe drbd
3. 配置心跳主机路由
Data-1-1主机:
route add -host 10.0.0.20 dev eth1
echo ‘/sbin/route add -host 10.0.0.20 dev eth1’ >> /etc/rc.local
route -n
Data-1-2主机:
Route add -host 10.0.0.10 dev eth1
echo ‘/sbin/route add -host 10.0.0.10 dev eth1’ >> /etc/rc.local
route -n
4. 做好磁盘分区,做数据同步
| 主节点(master) |
作用 |
备节点(slave) |
作用 |
| /dev/drbd0 |
drbd同步块设备 |
/dev/drbd0 |
drbd同步块设备 |
| /dev/sdc1 |
数据同步区 |
/dev/sdc1 |
数据同步区 |
| /dev/sdc2 |
meta data |
/dev/sdc2 |
meta data |
| 10.0.0.10 |
私网IP |
10.0.0.20 |
私网IP |
安装原则:
功能性的软件:用yum安装
高并发的软件:用编译安装
5.drbd加载到内核
lsmod |grep drbd
如果没有信息显示,则执行如下命令,加载到内核:
modprobe drbd
echo “modprobe drbd” >>/etc/rc.local
6.Drbd配置文件参数讲解及实际配置
ll /etc/drbd.conf
ll /etc/drbd.d/global_common.conf
[root@data-1-1 drbd-8.4.4]# cat /etc/drbd.conf
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "drbd.d/global_common.conf";
include "drbd.d/*.res";
由上可以看出,/etc/drbd.conf文件可能引用其他多个配置文件
配置文件模板:
global {
usage-count no;
}
common {
syncer {
rate 1000M;
verify-alg crc32c;
}
}
# primary for drbd1
resource data{
protocol C;
disk {
on-io-error detach;
}
# server 1
on data-1-1 {
device /dev/drbd0;
disk /dev/sdc1;
address 10.0.0.10:7788;
meta-disk /dev/sdc2[0];
}
#server 2
on data-1-2 {
device /dev/drbd0;
disk /dev/sdc1;
address 10.0.0.20:7788;
meta-disk /dev/sdc2[0];
}
}
drbd metadata分区初始化
drbdadm create-md data
# data为drbd.conf文件中的resource名,可以根据实际项目更改
启动drbd服务:
[root@data-1-2 ~]# drbdadm up data
/application/drbd8.4.4/var/run/drbd: No such file or directory
/application/drbd8.4.4/var/run/drbd: No such file or directory
如果报没有/application/drbd8.4.4/var/run/drbd目录,手动创建即可
mkdir -p /application/drbd8.4.4/var/run/drbd
drbdadm up all
相当于以下三个命令的组合:
drbdadm attach all
drbdadm syncer all
drbdadm connect all
查看drdb是否正常:
cat /proc/drbd
service drbd status
[root@data-1-2 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.4 (api:1/proto:86-101)
GIT-hash: 74402fecf24da8e5438171ee8c19e28627e1c98a build by root@data-1-2, 2017-01-11 00:51:42
m:res cs ro ds p mounted fstype
0:data Connected Secondary/Secondary Inconsistent/Inconsistent C
这种状态,表时本地为从对端也为从,即不同步数据。
数据同步
1、如果为空硬盘,可以随意执行操作,不考虑数据。
2、如果两边数据不一样(要特别注意同步数据的方向,否则可能会造成数据损坏或丢失)
一个资源只能在一端执行同步数据到对端的命令
drbdadm -- --overwrite-data-of-peer primary data
当前节点作为主primary
解决脑裂问题
1、在从节点slave data-1-2上做如下操作:
drbdadm secondary data
drbdadm -- --discard-my-data connect data
2、在主节点master data-1-1上,通过cat /proc/drbd查看状态,如果不是WFConnection状态,需要手动连接:
drbdadm connect data
cat /proc/drbd查看两端状态
挂载数据目录,测试数据同步
启动drbd后,会按/etc/drbd.conf文件中的配置生成/dev/drbd0块设备
这里/dev/drbd0对应的物理磁盘是/dev/sdc1
主库:
[root@data-1-1 /]# mkdir /datadrbd
[root@data-1-1 /]# mount /dev/drbd0 /datadrbd/
[root@data-1-1 /]# cd /datadrbd/
[root@data-1-1 datadrbd]# touch `seq 20`
在主节点挂载/dev/drbd0到/datadrbd目录,然后创建了20个文件
然后再到备节点去查看(备节点的/dev/drbd0需要一直等待主节点的数据同步过来,所以是不可以挂载的,需要先停drbd服务,然后挂载物理分区到目录下,方可看到结果)
[root@data-1-2 ~]# cat /proc/drbd
[root@data-1-2 ~]# drbdadm down data
[root@data-1-2 ~]# mount /dev/sdc1 /datadrbd/
[root@data-1-2 ~]# ls /datadrbd/
1 10 11 12 13 14 15 16 17 18 19 2 20 3 4 5 6 7 8 9 lost+found
结果显示,数据都已经同步过来了,实验成功。
附:解决备节点磁盘空间变小的问题
问题呈现:
[root@data-1-1 datadrbd]# df -lh
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
29G 9.9G 18G 36% /
/dev/sda1 99M 13M 82M 14% /boot
tmpfs 502M 0 502M 0% /dev/shm
/dev/drbd0 365M 11M 336M 3% /datadrbd
[root@data-1-2 ~]# df -lh
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
29G 8.1G 20G 30% /
/dev/sda1 99M 13M 82M 14% /boot
tmpfs 502M 0 502M 0% /dev/shm
/dev/sdc1 365M 11M 336M 3% /datadrbd
然而data-1-2节点的/dev/sdc1磁盘当初分配的实际容量有768M(这个不能记错)的,现在只有365M,与主库的分区一样大了,要如何找回剩下的空间,且保证数据不丢失?
分析:
1)使用fdisk来分区,只是改变了磁盘头的mbr信息,而数据是不会动的
2)通过fsck来修复磁盘头来恢复data-1-2节点的剩余可用空间
修复操作过程:
[root@data-1-2 ~]# umount /datadrbd
#开始修复磁盘分区,执行fsck命令
[root@data-1-2 ~]# fsck /dev/sdc1
fsck 1.39 (29-May-2006)
e2fsck 1.39 (29-May-2006)
/dev/sdc1: clean, 31/96384 files, 22457/385528 blocks
#取消分区jouranal功能,使之变成ext2文件分区(原来的磁盘文件系统为ext4时需要执行,这里为ext3时好像不需要)
[root@node2 ~]# tune2fs -o ^has_journal /dev/sdc1
tune2fs 1.41.12 (17-May-2010)
Invalid mount option set: ^has_journal
#使用fdisk重建分区表,不会删除数据
[root@data-1-2 ~]# fdisk /dev/sdc
Command (m for help): p
Disk /dev/sdc: 1073 MB, 1073741824 bytes
255 heads, 63 sectors/track, 130 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdc1 1 93 746991 83 Linux
/dev/sdc2 94 130 297202+ 83 Linux
Command (m for help): d
Partition number (1-4): 1
Command (m for help): p
Disk /dev/sdc: 1073 MB, 1073741824 bytes
255 heads, 63 sectors/track, 130 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdc2 94 130 297202+ 83 Linux
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-130, default 1):
Using default value 1
Last cylinder or +size or +sizeM or +sizeK (1-93, default 93):
Using default value 93
Command (m for help): p
Disk /dev/sdc: 1073 MB, 1073741824 bytes
255 heads, 63 sectors/track, 130 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdc1 1 93 746991 83 Linux
/dev/sdc2 94 130 297202+ 83 Linux
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
#强制检查/dev/sdc1
[root@data-1-2 ~]# e2fsck -f /dev/sdc1
e2fsck 1.39 (29-May-2006)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/sdc1: 31/96384 files (3.2% non-contiguous), 22457/385528 blocks
#调整/dev/sdc1分区到原始物理分区的大小
[root@data-1-2 ~]# resize2fs /dev/sdc1
resize2fs 1.39 (29-May-2006)
Resizing the filesystem on /dev/sdc1 to 746988 (1k) blocks.
The filesystem on /dev/sdc1 is now 746988 blocks long.#这里看到块设备被加长了
先把/dev/sdc1变成ext3分区(原来的磁盘文件系统为ext4时需要执行,这里为ext3时好像不需要)
[root@node2 ~]# tune2fs -j /dev/sdc1
tune2fs 1.41.12 (17-May-2010)
The filesystem already has a journal.
#在把/dev/sdc1变成ext4分区(原来的磁盘文件系统为ext4时需要执行,这里为ext3时好像不需要)
[root@node2 ~]# tune2fs -O extents,uninit_bg,dir_index /dev/sdc1
tune2fs 1.41.12 (17-May-2010)
#挂载/dev/sdc1到/datadrbd下面
[root@data-1-2 ~]# mount /dev/sdc1 /datadrbd/
[root@data-1-2 ~]# df -lh
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
29G 8.1G 20G 30% /
/dev/sda1 99M 13M 82M 14% /boot
tmpfs 502M 0 502M 0% /dev/shm
/dev/sdc1 707M 11M 667M 2% /datadrbd
[root@data-1-2 ~]# ll /datadrbd/
total 12
-rw-r--r-- 1 root root 0 Jan 12 01:13 1
-rw-r--r-- 1 root root 0 Jan 12 01:13 10
-rw-r--r-- 1 root root 0 Jan 12 01:13 11
-rw-r--r-- 1 root root 0 Jan 12 01:13 12
-rw-r--r-- 1 root root 0 Jan 12 01:13 13
-rw-r--r-- 1 root root 0 Jan 12 01:13 14
-rw-r--r-- 1 root root 0 Jan 12 01:13 15
-rw-r--r-- 1 root root 0 Jan 12 01:13 16
-rw-r--r-- 1 root root 0 Jan 12 01:13 17
-rw-r--r-- 1 root root 0 Jan 12 01:13 18
-rw-r--r-- 1 root root 0 Jan 12 01:13 19
-rw-r--r-- 1 root root 0 Jan 12 01:13 2
-rw-r--r-- 1 root root 0 Jan 12 01:13 20
-rw-r--r-- 1 root root 0 Jan 12 01:13 3
-rw-r--r-- 1 root root 0 Jan 12 01:13 4
-rw-r--r-- 1 root root 0 Jan 12 01:13 5
-rw-r--r-- 1 root root 0 Jan 12 01:13 6
-rw-r--r-- 1 root root 0 Jan 12 01:13 7
-rw-r--r-- 1 root root 0 Jan 12 01:13 8
-rw-r--r-- 1 root root 0 Jan 12 01:13 9
drwx------ 2 root root 12288 Jan 11 22:45 lost+found
#结果显示数据一切正常,没有丢失