Python_Numpy
Numpy
numpy基础概念
-
什么numpy?
快速、方便的科学计算基础库(主要是对数值的计算,多维数组的运算);Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))
-
轴的理解(axis):0轴, 1轴, 2轴
一维数组:[1,2,3,4,5] ----> 0轴
二维数组:[[1,2,3,4,5], [1,2,3,4,5]] ----> 0轴,1轴
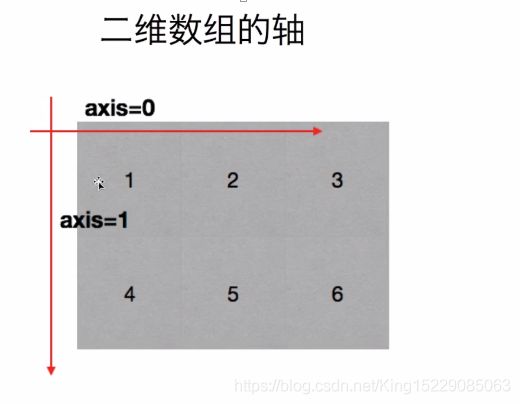
三维数组:[[[1,2],[3,4],[5,6]], [[1,2],[3,4],[5,6]]] ----> 0轴,1轴,2轴

numpy常用的方法
基本操作
创建数组(矩阵)
方法1:
a = np.array([1, 2, 3, 4])
b = np.array(range(2, 6))
print(b)
print(a + b)
方法2:
c = np.arange(1, 6)
print(c)
# 查看数组的类型
print(type(c))
运行结果:

查看或修改数组的数据类型
常见数据类型:

print(c.dtype)
print(c.astype('float'))
print(c.astype('bool'))
# 创建的时候指定数据类型
print(np.array([1,2,3,4], dtype=np.float))
运行结果:

修改浮点数的小数位数
d = np.array([1.24325654, 3.12345325, 5.321557])
print(np.round(d, 2))
运行结果:
[1.24 3.12 5.32]
读取数据
读取eg6-a-student-data.txt 文件中的性别信息和体重信息
eg6-a-student-data.txt 文件内容:

numpy 中的 loadtxt 方法用来读取文件信息
loadtxt 的几个重要属性:
- fname:文件名称,可以是文件名, 也可以是ugz或者bz2的压缩文件;
- dtype:数据类型,可选,默认是float;
- delimiter:分隔符字符串,默认情况是任何的空格;
- skiprows:跳过前xx行,一般情况跳过第一行;
- usecols:读取指定的列,可以是元组;
- unpack:如果为True,对返回的数组对象转置;
代码:
import numpy as np
fname = "doc/eg6-a-student-data.txt"
dtype = np.dtype([('gender', '|S1'), ('height', 'f2')])
data = np.loadtxt(fname=fname, dtype=dtype, skiprows=9, usecols=(1, 3), unpack=True)
print(data)
运行结果:
[array([b’M’, b’M’, b’F’, b’M’, b’F’, b’F’, b’M’, b’M’, b’F’, b’F’, b’M’, b’M’, b’M’, b’F’, b’F’, b’M’, b’F’, b’F’, b’M’], dtype=’|S1’),
array([1.82, 1.77, 1.68, 1.72, 1.78, 1.6 , 1.72, 1.83, 1.56, 1.64, 1.63, 1.67, 1.66, 1.59, 1.7 , 1.97, 1.66, 1.63, 1.69], dtype=float16)]
数组转置
import numpy as np
# 将一维数组转换为3行4列的二维数组
data = np.arange(12).reshape((3,4))
print(data)
# 方法一
print(data.transpose())
# 方法二
print(data.swapaxes(1,0))
# 方法三
print(data.T)

数组索引和切片
import numpy as np
data = np.arange(12).reshape((3,4))
print(data)
# 取第一行数据
print(data[0])
# 取第一列数据
print(data.T[0])
print(data[:,0])
# 获取多行
print(data[:2])
# 获取多列
print(data.T[:2])
print(data[:,:2])
# 获取指定行的前几列
print(data[[0,2],:2])
# 获取指定列的前几行
print(data.T[[0,2],:2].T)
print(data[:2,[0,2]])
数组中数值的修改
import numpy as np
data = np.arange(12).reshape((3, 4))
print(data)
# 修改第一行数据为零
data[0] = 0
print(data)
# 修改多行数据为零
data.T[:2] = 0
print(data)
# 布尔索引:返回一个存储布尔类型数据的数组
# 数组中所有大于8的数字全部替换为0
print(data > 8)
data[data > 8] = 0
print(data)
# 数组中所有大于8的数字全部替换为0,否则替换为1
# 方法一
data[data <= 8] = 1
data[data > 8] = 0
print(data)
# 方法二
print(np.where(data <= 8, 1, 0))
# 裁剪:如果data<=8,则替换为8;如果data>10,则替换为10
print(data.clip(8,10))
数组拼接
import numpy as np
t1 = np.arange(12).reshape((2, 6))
t2 = np.arange(12).reshape((2, 6))
t3 = np.arange(12).reshape((2, 6))
# 竖向拼接(vertically)
print(np.vstack((t1, t2, t3)))
# 水平拼接(horizontally)
print(np.hstack((t1, t2, t3)))
运行结果:

数组行列变换
import numpy as np
data = np.arange(12).reshape((2,6))
# 行交换(第1行和第2行交换)
print('原数据:\n',data)
data[[0,1],:] = data[[1,0],:]
print('替换后的数据:\n',data)
# 列交换(第3列和第5列交换)
print('原数据:\n',data)
data[:,[2,4]] = data[:,[4,2]]
print('替换后的数据:\n',data)
运行结果:

常用方法
1.获取最大值和最小值的位置
import numpy as np
data = np.arange(12).reshape((3, 4))
data[0, 0] = 80
print(data)
# 获取当前数组里面最大值的索引
print(np.argmax(data))
# 获取每一列的最大值对应的索引
print(np.argmax(data, axis=0))
# 获取每一行的最大值对应的索引
print(np.argmax(data, axis=1))
运行结果:

2.创建一个全为0的数组;
print(np.zeros((3, 3), dtype=np.int))
3.创建一个全为1的数组;
print(np.ones((3, 4)))
4.创建一个对角线全为1的正方形数组(方阵)
print(np.eye(3))
numpy的深拷贝和浅拷贝
-
列表的深拷贝和浅拷贝
- 浅拷贝:b = a[::] / b = copy.copy(a)
- 深拷贝:b = copy.deepcopy(a)
-
numpy中的拷贝
- data1 = data:完全不复制,两个变量相互影响,指向同一块内存空间;
- data2 = data[::]:会创建新的对象data2,但是data的数据完全由data2保管, 两个的数据变化是一致的;
- data3 = data.copy():深拷贝,两个变量不湖影响。
numpy中的nan和inf
nan(not a number):表示不是一个数字,代表的是数据缺失
nan的特殊属性:
-
nan是float类型
-
两个nan的值是不相等的:
>>> np.nan == np.nan
False
>>> np.nan != np.nan
True -
判断data里面的缺失值
data!=data array([[False, False, True, False], [False, False, True, False], [False, False, False, False]]) np.isnan(data) array([[False, False, True, False], [False, False, True, False], [False, False, False, False]]) -
判断有多少个缺失值:
data = np.arange(12, dtype=np.float).reshape(3, 4) data array([[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.]]) data[:2, 2] = np.nan data array([[ 0., 1., nan, 3.], [ 4., 5., nan, 7.], [ 8., 9., 10., 11.]]) np.count_nonzero(data!=data) 2 np.count_nonzero(np.isnan(data)) 2
inf(infinity):inf代表正无穷,-inf代表负无穷
import numpy as np
print(np.nan)
print(np.inf)
print(-np.inf)
运行结果:
nan
inf
-inf
numpy常用的统计方法
import numpy as np
data = np.arange(12, dtype=np.float).reshape(3, 4)
求和
print(data.sum())
# 每一列数据的和;
print(data.sum(axis=0))
# 每一行数据的和;
print(data.sum(axis=1))
均值
print(data.mean())
print(data.mean(axis=0))
print(data.mean(axis=1))
中值
print(data)
print(np.median(data))
print(np.median(data, axis=0))
print(np.median(data, axis=1))
最大值(最小值)
print(data.max())
print(data.max(axis=0))
print(data.max(axis=1))
极差:最大值 - 最小值
print(np.ptp(data))
print(np.ptp(data, axis=0))
print(np.ptp(data, axis=1))
标准差: 代表的是数据的波动稳定情况, 数字越大, 越不稳定
print(data.std())
print(data.std(axis=0))
print(data.std(axis=1))
案例_学生身高体重统计分析
获取eg6-a-student-data.txt 文件中的身高体重信息
需求1:
获取所有男生的身高,求平均值;
获取所有女生的身高,求平均值;
并绘制柱状图显示。
代码:
import numpy as np
from pyecharts import Bar
filename = 'doc/eg6-a-student-data.txt'
datatype = np.dtype([('gender', '|S1'), ('height', 'f4')])
data = np.loadtxt(fname=filename, dtype=datatype, skiprows=9, usecols=(1, 3))
# 判断性别是否为男性
isMale = data['gender'] == b'M'
male_avg_height = data['height'][isMale].mean()
female_avg_height = data['height'][~isMale].mean()
np.round(male_avg_height,2)
np.round(female_avg_height,2)
bar = Bar(title="不同性别身高的平均值")
bar.add("", ["男", '女'], [male_avg_height, female_avg_height])
bar.render()
绘制柱状图如下:

需求2:
获取所有男生的身高体重,求平均值;
获取所有女生的身高体重,求平均值;
并绘制柱状图显示。
代码:
import numpy as np
from pyecharts import Bar
def parser_weight(weight):
# 对于体重数据的处理, 如果不能转换为浮点数据类型, 则返回缺失值;
try:
return float(weight)
except ValueError as e:
return np.nan
filename = 'doc/eg6-a-student-data.txt'
datatype = np.dtype([('gender', '|S1'), ('height', 'f4'), ('weight', 'f4')])
data = np.loadtxt(fname=filename, dtype=datatype, skiprows=9, usecols=(1, 3, 4),converters={4:parser_weight})
# 判断性别是否为男性
isMale = data['gender'] == b'M'
male_avg_height = data['height'][isMale].mean()
female_avg_height = data['height'][~isMale].mean()
np.round(male_avg_height,2)
np.round(female_avg_height,2)
# 判断是否性别为男的平均体重
is_weight_vaild = data['weight'] == data['weight']
male_avg_weight = data['weight'][isMale & is_weight_vaild].mean()
female_avg_weight = data['weight'][~isMale & is_weight_vaild].mean()
np.round(male_avg_weight,2)
np.round(female_avg_weight,2)
bar = Bar(title="不同性别身高体重的平均值")
bar.add("身高", ["男", '女'], [male_avg_height, female_avg_height])
bar.add("体重", ["男", '女'], [male_avg_weight, female_avg_weight])
bar.render()
绘制柱状图如下:

案例_股价统计分析
data.csv文件中存储了股票的信息, 其中第4-8列,即EXCEL表格中的D-H列,分别为股票的开盘价,最高价,最低价,收盘价,成交量。
分析角度:
1.计算成交量加权平均价格
概念:成交量加权平均价格,英文名VWAP(Volume-Weighted Average Price,成交量加权平均价格)是一个非常重要的经济学量,代表着金融资产的“平均”价格。
某个价格的成交量越大,该价格所占的权重就越大。VWAP就是以成交量为权重计算出来的加权平均值。
2.计算最大值和最小值:计算股价近期最高价的最大值和最低价的最小值
3.计算股价近期最高价的最大值和最小值的差值(极差);计算股价近期最低价的最大值和最小值的差值
4.计算收盘价的中位数
5.计算收盘价的方差
6.计算对数收益率、股票收益率、年波动率及月波动率
在投资学中,波动率是对价格变动的一种度量,历史波动率可以根据历史价格数据计算得出。计算历史波动率时,需要用到对数收益率。
收盘价的分析常常是基于股票收益率的。
股票收益率又可以分为简单收益率和对数收益率。
简单收益率:是指相邻两个价格之间的变化率。
对数收益率:是指所有价格取对数后两两之间的差值。
使用的方法: NumPy中的diff函数可以返回一个由相邻数组元素的差值构成的数组。不过需要注意的是,diff返回的数组比收盘价数组少一个元素。
年波动率等于对数收益率的标准差除以其均值,再乘以交易日的平方根,通常交易日取252天。
月波动率等于对数收益率的标准差除以其均值,再乘以交易月的平方根,通常交易月取12月。
7.获取该时间范围内交易日周一、周二、周三、周四、周五分别对应的平均收盘价
8.平均收盘价最低,最高分别为星期几
代码:
import numpy as np
print('*******************************************')
params1 = dict(
fname='doc/data.csv',
delimiter=',',
usecols=(6, 7),
unpack=True
)
# 收盘价,成交量
endPrice, countNum = np.loadtxt(**params1)
# 计算成交量加权平均价格
VWAP = np.average(endPrice, weights=countNum)
print('1. 成交量加权平均价格:', VWAP)
print('*******************************************')
params2 = dict(
fname='doc/data.csv',
delimiter=',',
usecols=(4, 5),
unpack=True
)
# 最高价,最低价
highPrice, lowPrice = np.loadtxt(**params2)
# 计算最高价的最大值和最低价的最小值
print('2. 最高价的最大值:', highPrice.max())
print('2. 最低价的最小值:', lowPrice.min())
print('*******************************************')
# 计算股价近期最高价的最大值和最小值的差值 ----> 极差
# 计算股价近期最低价的最大值和最小值的差值
print('3. 近期最高价的极差:', np.ptp(highPrice))
print('3. 近期最低价的极差:', np.ptp(lowPrice))
print('*******************************************')
# 计算收盘价的中位数
print('4. 收盘价的中位数:', np.median(endPrice))
print('*******************************************')
# 计算收盘价的方差
print('5. 收盘价的方差:', np.var(endPrice))
print('*******************************************')
# 计算股票收益率,年波动率及月波动率
# 简单收益率
simpleReturn = np.diff(endPrice)
print("6. 简单收益率:", simpleReturn)
# 对数收益率:所有价格取对数后两两之间的差值
logReturn = np.diff(np.log(endPrice))
print("6. 对数收益率:", logReturn)
# 年波动率等于对数收益率的标准差除以其均值,再乘以交易日的平方根,通常交易日取252天
annual_vol = logReturn.std() / logReturn.mean() * np.sqrt(252)
print("6. 年波动率:", annual_vol)
# 月波动率等于对数收益率的标准差除以其均值,再乘以交易月的平方根,通常交易月取12月
month_vol = logReturn.std() / logReturn.mean() * np.sqrt(12)
print("6. 月波动率:", month_vol)
print('*******************************************')
from datetime import datetime
def get_week(date):
"""根据传入的日期获取星期数,0-星期1"""
# 默认传入的不是字符串,而是bytes类型
date = date.decode('utf-8')
return datetime.strptime(date, '%d-%m-%Y').weekday()
params3 = dict(
fname='doc/data.csv',
delimiter=',',
usecols=(1),
converters={1: get_week},
unpack=True
)
# 星期数
week = np.loadtxt(**params3)
allAvg = []
for weekday in range(5):
average = endPrice[week == weekday].mean()
allAvg.append(average)
print('7. 星期%s的平均收盘价:%s' % (weekday + 1, average))
print('*******************************************')
print('8. 平均收盘价最高是星期', np.argmax(allAvg) + 1)
print('8. 平均收盘价最低是星期', np.argmin(allAvg) + 1)
运行结果:
1.成交量加权平均价格: 350.5895493532009
2.最高价的最大值: 364.9
2.最低价的最小值: 333.53
3.近期最高价的极差: 24.859999999999957
3.近期最低价的极差: 26.970000000000027
4.收盘价的中位数: 352.055
5.收盘价的方差: 50.126517888888884
6.简单收益率: [ 3.22 5.71 -0.71 -0.88 3.06 5.38 3.32 2.96 -3.62 2.31 2.33 0.72 3.23 -4.83 -7.74 -11.95 4.01 0.26 5.28 5.05 -3.9 2.81 7.44 0.44 -4.64 0.4 -3.29 -5.8 5.32]
6.对数收益率: [ 0.00953488 0.01668775 -0.00205991 -0.00255903 0.00887039 0.01540739 0.0093908 0.0082988 -0.01015864 0.00649435 0.00650813 0.00200256 0.00893468 -0.01339027 -0.02183875 -0.03468287 0.01177296 0.00075857 0.01528161 0.01440064 -0.011103 0.00801225 0.02090904 0.00122297 -0.01297267 0.00112499 -0.00929083 -0.01659219 0.01522945]
6.年波动率: 129.27478991115134
6.月波动率: 28.210071915112593
7.星期1的平均收盘价:351.7900000000001
7.星期2的平均收盘价:350.63500000000005
7.星期3的平均收盘价:352.1366666666666
7.星期4的平均收盘价:350.8983333333333
7.星期5的平均收盘价:350.0228571428571
8.平均收盘价最高是星期 3
8.平均收盘价最低是星期 5