Python入门:读写json、txt和csv文件
打开文件的不同模式:
| 模式 | 描述 |
|---|---|
| r | r,以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | rb,以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | r+,打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | rb+,以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | w,打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb | wb ,以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| w+ | w+, 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb+ | wb+,以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | a,打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | a+,打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | ab+,以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
Python读写Json文件
Json在python中分别由list和dict组成。只能序列化最基本的数据类型,只能把常用的数据类型序列化(列表、字典、列表、字符串、数字、),比如日期格式、类对象!Json就不行了,对于这种不能处理的数据类型,可采用pickel模块来实现。
具体事例如下:
dumps:将python中的字典转换为字符串
import json
test_dict = {'bigberg': [7600, {1: [['iPhone', 6300], ['Bike', 800], ['shirt', 300]]}]}
print(test_dict)
print(type(test_dict))
#dumps 将数据转换成字符串
json_str = json.dumps(test_dict)
print(json_str)
print(type(json_str))

loads: 将字符串转换为字典
new_dict = json.loads(json_str)
print(new_dict)
print(type(new_dict))
dump: 将数据写入json文件中
with open("../config/record.json","w") as f:
json.dump(new_dict,f)
print("加载入文件完成...")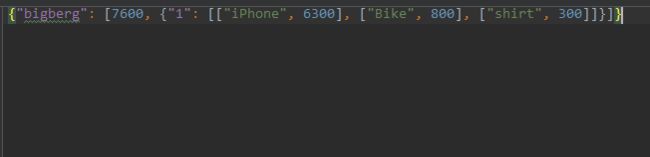
load:把文件打开,并把字符串变换为数据类型
with open("../config/record.json",'r') as load_f:
load_dict = json.load(load_f)
print(load_dict)
load_dict['smallberg'] = [8200,{1:[['Python',81],['shirt',300]]}]
print(load_dict)
with open("../config/record.json","w") as dump_f:
json.dump(load_dict,dump_f)
逐条写入:
file_res = open('./result/train_result.json', 'w')
for j in range(2):
if j == 0:
dict.setdefault('image_name', []).append(img_name[j])
dict.setdefault('label', []).append(s[j])
dict.setdefault('hash', []).append(h[j])
else:
dict['image_name'].append(img_name[j])
dict['label'].append(s[j])
dict['hash'].append(h[j])
# 两种形式均可写入,前者所有结果在一行,后者可添加回车
# 注意dict使用append方法后,json写入的方法就要放在循环外面,否则会重复
# json.dump(dict, file_res)
file_res.write(json.dumps(dict) + '\n')![]()
file_res = open('./result/train_result.json', 'w')
for j in range(2):
dict['image_name'] = img_name[j]
dict['label'] = s[j]
dict['hash'] = h[j]
# 注意json写入的方法放在循环里
# file_res.write(json.dumps(dict) + '\n')
json.dump(dict, file_res)![]()
Python读写txt文件:
import os
# 读取txt文件
with open("test2.txt", 'r') as file_obj:
all_lines = file_obj.readlines()
for line in all_lines:
print(line)
# 写之前,先检验文件是否存在,存在就删掉
if os.path.exists("dest.txt"):
os.remove("dest.txt")
mylist = ["luoluo", "taotao", "mumu"]
# 以写的方式打开文件,如果文件不存在,就会自动创建
with open("test2.txt", 'w') as file_write_obj:
for var in mylist:
file_write_obj.writelines(var)
file_write_obj.write('\n')Python读写csv文件:
import csv
# 读取csv文件方式
with open("csvData.csv", "r") as csvfile:
reader = csv.reader(csvfile) # 读取csv文件,返回的是迭代类型
for item in reader:
print(item)
# 从列表写入csv文件
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
csvFile2 = open('csvFile2.csv', 'w', newline='') # 设置newline,否则两行之间会空一行
writer = csv.writer(csvFile2)
m = len(data)
for i in range(m):
writer.writerow(data[i])
csvFile2.close()
# 从字典写入csv文件
dic = {'张三': 123, '李四': 456, '王二娃': 789}
csvFile3 = open('csvFile3.csv', 'w', newline='')
writer2 = csv.writer(csvFile3)
for key in dic:
writer2.writerow([key, dic[key]])
csvFile3.close()