为什么使用Vue-Simple-Uploader
最近用到了Vue + Spring Boot来完成文件上传的操作,踩了一些坑,对比了一些Vue的组件,发现了一个很好用的组件——Vue-Simple-Uploader
再说说为什么选用这个组件,对比vue-ant-design和element-ui的上传组件,它能做到更多的事情,比如:
- 可暂停、继续上传
- 上传队列管理,支持最大并发上传
- 分块上传
- 支持进度、预估剩余时间、出错自动重试、重传等操作
- 支持“快传”,通过文件判断服务端是否已存在从而实现“快传”
由于需求中需要用到断点续传,所以选用了这个组件,下面我会从最基础的上传开始说起:
单文件上传、多文件上传、文件夹上传
Vue代码:
选择文件
选择文件夹
该组件默认支持多文件上传,这里我们从官方demo中粘贴过来这段代码,然后在uploadOption1中配置上传的路径即可,其中uploader-btn 中设置directory属性即可选择文件夹进行上传。
uploadOption1:
uploadOptions1: {
target: "//localhost:18080/api/upload/single",//上传的接口
testChunks: false, //是否开启服务器分片校验
fileParameterName: "file",//默认的文件参数名
headers: {},
query() {},
categaryMap: { //用于限制上传的类型
image: ["gif", "jpg", "jpeg", "png", "bmp"]
}
}
在后台的接口的编写,我们为了方便,定义了一个chunk类用于接收组件默认传输的一些后面方便分块断点续传的参数:
Chunk类
@Data
public class Chunk implements Serializable {
private static final long serialVersionUID = 7073871700302406420L;
private Long id;
/**
* 当前文件块,从1开始
*/
private Integer chunkNumber;
/**
* 分块大小
*/
private Long chunkSize;
/**
* 当前分块大小
*/
private Long currentChunkSize;
/**
* 总大小
*/
private Long totalSize;
/**
* 文件标识
*/
private String identifier;
/**
* 文件名
*/
private String filename;
/**
* 相对路径
*/
private String relativePath;
/**
* 总块数
*/
private Integer totalChunks;
/**
* 文件类型
*/
private String type;
/**
* 要上传的文件
*/
private MultipartFile file;
}
在编写接口的时候,我们直接使用这个类作为参数去接收vue-simple-uploader传来的参数即可,注意这里要使用POST来接收哟~
接口方法:
@PostMapping("single")
public void singleUpload(Chunk chunk) {
// 获取传来的文件
MultipartFile file = chunk.getFile();
// 获取文件名
String filename = chunk.getFilename();
try {
// 获取文件的内容
byte[] bytes = file.getBytes();
// SINGLE_UPLOADER是我定义的一个路径常量,这里的意思是,如果不存在该目录,则去创建
if (!Files.isWritable(Paths.get(SINGLE_FOLDER))) {
Files.createDirectories(Paths.get(SINGLE_FOLDER));
}
// 获取上传文件的路径
Path path = Paths.get(SINGLE_FOLDER,filename);
// 将字节写入该文件
Files.write(path, bytes);
} catch (IOException e) {
e.printStackTrace();
}
}
这里需要注意一点,如果文件过大的话,Spring Boot后台会报错
org.apache.tomcat.util.http.fileupload.FileUploadBase$FileSizeLimitExceededException: The field file exceeds its maximum permitted size of 1048576 bytes.
这时需要在application.yml中配置servlet的最大接收文件大小(默认大小是1MB和10MB)
spring:
servlet:
multipart:
max-file-size: 10MB
max-request-size: 100MB
下面我们启动项目,选择需要上传的文件就可以看到效果了~ 是不是很方便~ 但是同样的事情其余的组件基本上也可以做到,之所以选择这个,更多的是因为它可以支持断点分块上传,实现上传过程中断网,再次联网的话可以从断点位置开始继续秒传~下面我们来看看断点续传是怎么玩的。
断点分块续传
先说一下分块断点续传的大概原理,我们在组件可以配置分块的大小,大于该值的文件会被分割成若干块儿去上传,同时将该分块的chunkNumber保存到数据库(Mysql or Redis,这里我选择的是Redis)
组件上传的时候会携带一个identifier的参数(这里我采用的是默认的值,你也可以通过生成md5的方式来重新赋值参数),将identifier作为Redis的key,设置hashKey为”chunkNumber“,value是由每次上传的chunkNumber组成的一个Set集合。
在将uploadOption中的testChunk的值设置为true之后,该组件会先发一个get请求,获取到已经上传的chunkNumber集合,然后在checkChunkUploadedByResponse方法中判断是否存在该片段来进行跳过,发送post请求上传分块的文件。
每次上传片段的时候,service层返回当前的集合大小,并与参数中的totalChunks进行对比,如果发现相等,就返回一个状态值,来控制前端发出merge请求,将刚刚上传的分块合为一个文件,至此文件的断点分块上传就完成了。
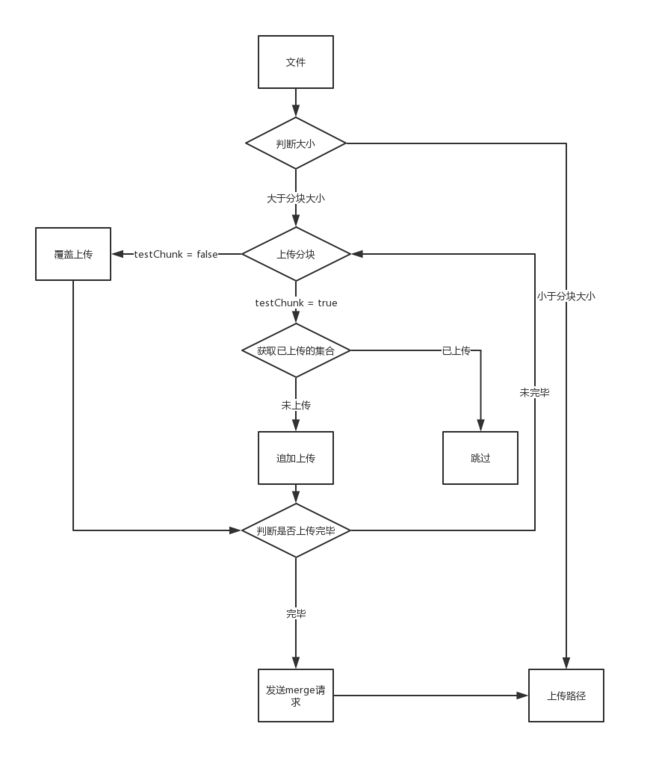
下面是对应的代码~
Vue代码:
分块上传
校验是否上传过的代码
uploadOptions2: {
target: "//localhost:18080/api/upload/chunk",
chunkSize: 1 * 1024 * 1024,
testChunks: true,
checkChunkUploadedByResponse: function(chunk, message) {
let objMessage = JSON.parse(message);
// 获取当前的上传块的集合
let chunkNumbers = objMessage.chunkNumbers;
// 判断当前的块是否被该集合包含,从而判定是否需要跳过
return (chunkNumbers || []).indexOf(chunk.offset + 1) >= 0;
},
headers: {},
query() {},
categaryMap: {
image: ["gif", "jpg", "jpeg", "png", "bmp"],
zip: ["zip"],
document: ["csv"]
}
}
上传后成功的处理,判断状态来进行merge操作
onFileSuccess2(rootFile, file, response, chunk) {
let res = JSON.parse(response);
// 后台报错
if (res.code == 1) {
return;
}
// 需要合并
if (res.code == 205) {
// 发送merge请求,参数为identifier和filename,这个要注意需要和后台的Chunk类中的参数名对应,否则会接收不到~
const formData = new FormData();
formData.append("identifier", file.uniqueIdentifier);
formData.append("filename", file.name);
merge(formData).then(response => {});
}
},
判定是否存在的代码,注意这里的是GET请求!!!
@GetMapping("chunk")
public Map checkChunks(Chunk chunk) {
return uploadService.checkChunkExits(chunk);
}
@Override
public Map checkChunkExits(Chunk chunk) {
Map res = new HashMap<>();
String identifier = chunk.getIdentifier();
if (redisDao.existsKey(identifier)) {
Set chunkNumbers = (Set) redisDao.hmGet(identifier, "chunkNumberList");
res.put("chunkNumbers",chunkNumbers);
}
return res;
}
保存分块,并保存数据到Redis的代码。这里的是POST请求!!!
@PostMapping("chunk")
public Map saveChunk(Chunk chunk) {
// 这里的操作和保存单段落的基本是一致的~
MultipartFile file = chunk.getFile();
Integer chunkNumber = chunk.getChunkNumber();
String identifier = chunk.getIdentifier();
byte[] bytes;
try {
bytes = file.getBytes();
// 这里的不同之处在于这里进行了一个保存分块时将文件名的按照-chunkNumber的进行保存
Path path = Paths.get(generatePath(CHUNK_FOLDER, chunk));
Files.write(path, bytes);
} catch (IOException e) {
e.printStackTrace();
}
// 这里进行的是保存到redis,并返回集合的大小的操作
Integer chunks = uploadService.saveChunk(chunkNumber, identifier);
Map result = new HashMap<>();
// 如果集合的大小和totalChunks相等,判定分块已经上传完毕,进行merge操作
if (chunks.equals(chunk.getTotalChunks())) {
result.put("message","上传成功!");
result.put("code", 205);
}
return result;
}
/**
* 生成分块的文件路径
*/
private static String generatePath(String uploadFolder, Chunk chunk) {
StringBuilder sb = new StringBuilder();
// 拼接上传的路径
sb.append(uploadFolder).append(File.separator).append(chunk.getIdentifier());
//判断uploadFolder/identifier 路径是否存在,不存在则创建
if (!Files.isWritable(Paths.get(sb.toString()))) {
try {
Files.createDirectories(Paths.get(sb.toString()));
} catch (IOException e) {
log.error(e.getMessage(), e);
}
}
// 返回以 - 隔离的分块文件,后面跟的chunkNumber方便后面进行排序进行merge
return sb.append(File.separator)
.append(chunk.getFilename())
.append("-")
.append(chunk.getChunkNumber()).toString();
}
/**
* 保存信息到Redis
*/
public Integer saveChunk(Integer chunkNumber, String identifier) {
// 获取目前的chunkList
Set oldChunkNumber = (Set) redisDao.hmGet(identifier, "chunkNumberList");
// 如果获取为空,则新建Set集合,并将当前分块的chunkNumber加入后存到Redis
if (Objects.isNull(oldChunkNumber)) {
Set newChunkNumber = new HashSet<>();
newChunkNumber.add(chunkNumber);
redisDao.hmSet(identifier, "chunkNumberList", newChunkNumber);
// 返回集合的大小
return newChunkNumber.size();
} else {
// 如果不为空,将当前分块的chunkNumber加到当前的chunkList中,并存入Redis
oldChunkNumber.add(chunkNumber);
redisDao.hmSet(identifier, "chunkNumberList", oldChunkNumber);
// 返回集合的大小
return oldChunkNumber.size();
}
}
合并的后台代码:
@PostMapping("merge")
public void mergeChunks(Chunk chunk) {
String fileName = chunk.getFilename();
uploadService.mergeFile(fileName,CHUNK_FOLDER + File.separator + chunk.getIdentifier());
}
@Override
public void mergeFile(String fileName, String chunkFolder) {
try {
// 如果合并后的路径不存在,则新建
if (!Files.isWritable(Paths.get(mergeFolder))) {
Files.createDirectories(Paths.get(mergeFolder));
}
// 合并的文件名
String target = mergeFolder + File.separator + fileName;
// 创建文件
Files.createFile(Paths.get(target));
// 遍历分块的文件夹,并进行过滤和排序后以追加的方式写入到合并后的文件
Files.list(Paths.get(chunkFolder))
//过滤带有"-"的文件
.filter(path -> path.getFileName().toString().contains("-"))
//按照从小到大进行排序
.sorted((o1, o2) -> {
String p1 = o1.getFileName().toString();
String p2 = o2.getFileName().toString();
int i1 = p1.lastIndexOf("-");
int i2 = p2.lastIndexOf("-");
return Integer.valueOf(p2.substring(i2)).compareTo(Integer.valueOf(p1.substring(i1)));
})
.forEach(path -> {
try {
//以追加的形式写入文件
Files.write(Paths.get(target), Files.readAllBytes(path), StandardOpenOption.APPEND);
//合并后删除该块
Files.delete(path);
} catch (IOException e) {
e.printStackTrace();
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
至此,我们的断点续传就完美结束了,完整的代码我已经上传到gayhub~,欢迎star fork pr~(后面还会把博文也上传到gayhub哟~)
前端:https://github.com/viyog/viboot-front
后台:https://github.com/viyog/viboot
公众号
