python--爬虫基本操作一
目录
一、认识爬虫
二、获取数据:模块requests
三、数据解析与提取:模块 BeautifulSoup
一、认识爬虫
浏览器的工作原理:
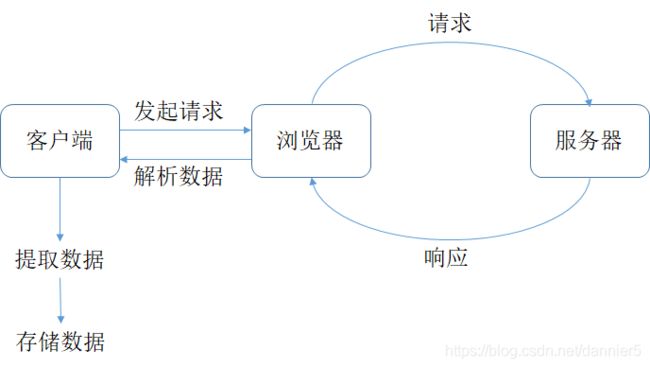
爬虫的工作原理:

爬虫工作4个步骤:
第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据。
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
第2步:提取数据。爬虫程序再从中提取出我们需要的数据。
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
二、获取数据:模块requests
1、requests功能:
requests库可以帮我们下载网页源代码、文本、图片,甚至是音频。即是向服务器发送请求并得到响应。
requests为第三方模块,安装方法:
Mac电脑:pip3 instal requests
Windows电脑:pip install requests
2、requests常用方法与属性
requests.get(url),它向服务器发送了一个请求,括号里的参数是你需要的数据所在的网址,然后服务器对请求作出了响应,并返回一个Response对象。
| Response对象的常用属性 |
||
| 序号 |
属性 |
作用 |
| 1 |
response.status_code |
检查请求是否成功,并返回响应状态码,一般如果响应状态码为200,即代表请求成功。 |
| 2 |
response.content |
吧response对象转换为二进制数据,图像、音频和视频等数据需要转换成二进制数据再存储。 |
| 3 |
response.text |
吧response对象转换成字符串形式返回,适用于文字、网页源代码的下载。 |
| 4 |
response.encoding |
定义response对象的编码格式,获取目标数据后要知道相应的编码类型才能正确解码。 |
| 常见响应状态码解释(status_code) |
|||
| 响应状态码 |
说明 |
举例 |
说明 |
| 1xx |
请求收到 |
100 |
继续提出请求 |
| 2xx |
请求成功 |
200 |
成功 |
| 3xx |
重定向 |
305 |
应使用代理访问 |
| 4xx |
客户端错误 |
403 |
禁止访问 |
| 5xx |
服务器端错误 |
503 |
服务不可用 |
示例:
# 引入requests库
import requests
# 发出请求,并把返回的结果放在变量res中
res = requests.get('https://res.pandateacher.com/2018-12-18-10-43-07.png')
# 把Reponse对象的内容以二进制数据的形式返回
#print(type(res))
#》》
print(res.status_code) #检测请求是否正确响应
#》》200
pic = res.content
# 新建了一个文件ppt.jpg,这里的文件没加路径,它会被保存在程序运行的当前目录下。
# 图片内容需要以二进制wb读写。你在学习open()函数时接触过它。
photo = open('ppt.jpg','wb')
# 获取pic的二进制内容
photo.write(pic)
# 关闭文件
photo.close()
# 下载《三国演义》第一回,我们得到一个对象,它被命名为res
res1 = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md')
# 把Response对象的内容以字符串的形式返回
novel=res1.text
# 现在,可以打印小说了,但考虑到整章太长,只输出800字看看就好。在关于列表的知识那里,你学过[:800]的用法。
print(novel[:800])
k = open('三国演义.txt','a+')
k.write(novel)
k.close() robots协议是互联网爬虫的一项公认的道德规范,它的全称是“网络爬虫排除标准”(robots exclusion protocol),这个协议用来告诉爬虫,哪些页面是可以抓取的,哪些不可以。
三、数据解析与提取:模块 BeautifulSoup
1、BeautifulSoup功能说明
解析数据,提取数据
BeautifulSoup为第三方模块,安装方法:
安装:pip install BeautifulSoup4
2、BeautifulSoup常用方法与属性
bs对象 = BeautifulSoup(要解析的文本,‘解析器’)
| bs对象常用方法: find()与find_all() 方法 |
||||
| 方法 |
作用 |
用法 |
返回值 |
示例 |
| find() |
提取满足要求的首个数据 |
bs对象.find(标签,属性) |
返回Tag对象 |
soup.find('div',class_'books') |
| find_all() |
提取满足要求的所有数据 |
bs对象.find_all(标签,属性) |
返回Tag对象组成的列表 |
soup.find_all('div',class_='books') |
注:网页中的class为了和python中的class做区分,通常写为class_
官方文档:
find(tag, attributes, recursive, text, keywords)
find_all(tag, attributes, recursive, text, keywords)
| Tag对象常用属性与方法 |
||
| 属性/方法 |
说明 |
备注 |
| Tag.find() |
提取满足要求的首个数据 |
|
| Tag.find_all() |
提取满足要求的所有数据 |
|
| Tag.text |
获取标签内的纯文本信息,即便是在它的子标签内,也能拿得到。 |
|
| Tag['属性名'] |
提取属性的值 |
|
3、完整操作过程

爬取菜谱实例:
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup
# 获取数据 返回一个response对象,赋值给res_foods
res_foods = requests.get('http://www.xiachufang.com/explore/')
# 解析数据 把res_foods的内容以字符串的形式输入BeautifulSoup方法,
# 并返回bs对象,html.parser为解析器
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 通过定位标签和属性查找最小父级标签,并提取数据
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 创建一个空列表,用于存储信息
list_all = []
for food in list_foods:
# 提取第0个父级标签中的标签
tag_a = food.find('a')
# 菜名,使用[17:-13]切掉了多余的信息
name = tag_a.text[17:-13]
# 获取URL
URL = 'http://www.xiachufang.com'+tag_a['href']
# 提取第0个父级标签中的标签
tag_p = food.find('p',class_='ing ellipsis')
# 食材,使用[1:-1]切掉了多余的信息
ingredients = tag_p.text[1:-1]
# 将菜名、URL、食材,封装为列表,添加进list_all
list_all.append([name,URL,ingredients])
# 打印
print(list_all)
三、Network,XHR,json工具
打开网页后,右键检查,查看Network,查看ALL,然后刷新网页,查看第0个请求(html请求)的preview中,有没有我们要的数据信息,如果有——那就在html中,通过标签查找去爬取数据。
如果没有,那就说明数据是在XHR中的,就要通过Network,XHR,json工具去爬取数据。

Network的功能是:记录在当前页面上发生的所有请求,刷新页面即可显示。
快捷键:ctrl+shift+i
Network能够记录浏览器的所有请求。我们最常用的是:
- ALL(查看全部);
- XHR(仅查看XHR);
- Doc(Document,第0个请求一般在这里),有时候也会看看:
- Img(仅查看图片);
- Media(仅查看媒体文件);
- Other(其他;
- JS和CSS,则是前端代码,负责发起请求和页面实现;
- Font是文字的字体;
- WS和Manifest,需要网络编程的知识,倘若不是专门做这个,你不需要了解。
XHR请求:是一种Ajax技术,不用重新加载整个网页更新网页内容传输数据。
参考:https://www.w3cschool.cn/ajax/ajax-xmlhttprequest-send.html
json是一种规范数据传输的格式,形式有点像字典和列表的结合体。
python有json模块来处理json格式数据。
链接:https://docs.python.org/3/library/json.html
requests里也有一个内置的json解码器,来处理json对象。
链接:https://requests.readthedocs.io/zh_CN/latest/
每个url都由两部分组成:
前半部分大多形如:https://xx.xx.xxx/xxx/xxx
后半部分,多形如:xx=xx&xx=xxx&xxxxx=xx&……
两部分使用?来连接。
这前半部分是我们所请求的地址,它告诉服务器,我想访问这里。而后半部分,就是我们的请求所附带的参数,它会告诉服务器,我们想要什么样的数据。这参数的结构,会和字典很像,有键有值,键值用=连接;每组键值之间,使用&来连接。
后半部分作为params可以在Query String Parameters中提取。
requests模块里的requests.get()提供了一个参数叫params,可以让我们用字典的形式,把参数传进去。它的官方文档,是这样描述:

import requests
# 引用requests模块
url = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg'
# 请求歌曲评论的url参数的前面部分
for i in range(5):
params = {
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'format':'json',
'inCharset':'utf8',
'outCharset':'GB2312',
'notice':'0',
'platform':'yqq.json',
'needNewCode':'0',
'cid':'205360772',
'reqtype':'2',
'biztype':'1',
'topid':'102065756',
'cmd':'6',
'needmusiccrit':'0',
'pagenum':str(i),
'pagesize':'15',
'lasthotcommentid':'song_102065756_3202544866_44059185',
'domain':'qq.com',
'ct':'24',
'cv':'10101010'
}
# 将参数封装为字典
res_comments = requests.get(url,params=params)
# 调用get方法,下载这个字典
json_comments = res_comments.json()
list_comments = json_comments['comment']['commentlist']
for comment in list_comments:
print(comment['rootcommentcontent'])服务器就可能会对我们这些“投机取巧”的爬虫做限制处理。一来可以降低服务器的访问压力;二来可以拦截那些想要通过爬虫窃取数据的竞争者。
那么服务器怎么判断访问者是一个普通的用户(通过浏览器),还是一个爬虫者(通过代码)呢?
这需要我们回到浏览器中,重新认识一个新的信息栏:请求头Request Headers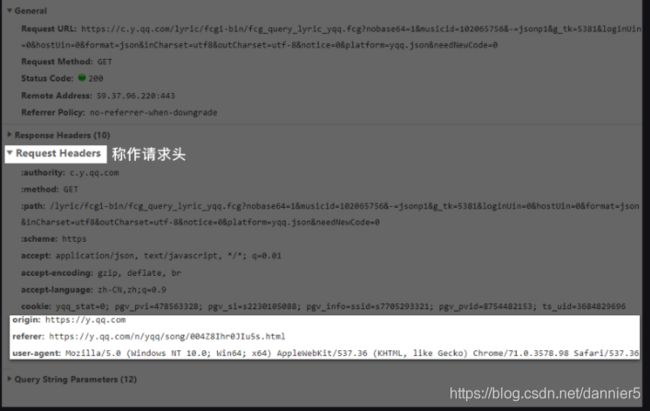
每一个请求,都会有一个Requests Headers,我们把它称作请求头。它里面会有一些关于该请求的基本信息,比如:这个请求是从什么设备什么浏览器上发出?这个请求是从哪个页面跳转而来?
它最大的应用是帮助我们应对“反爬虫”技术,将Python爬虫伪装成真正的浏览器,不为服务器所辨识;同时也可以标记这个请求的来源是什么,最终帮助我们拿到想要的信息。(反爬)
示例:爬取豆瓣电影Top250,保存序号,影片名,评分,推荐语与链接
import requests
from bs4 import BeautifulSoup
# url = 'https://movie.douban.com/top250?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
movie_infos = []
for i in range(10):
url = 'https://movie.douban.com/top250?start='+str(i*25)+'&filter='
res = requests.get(url,headers=headers)
res_html = res.text
res_soup = BeautifulSoup(res_html,'html.parser')
movies = res_soup.find_all('div',class_='item')
for movie in movies:
movie_item = movie.find('em').text
movie_search = movie.find('div',class_='info')
movie_url = movie_search.find('a')['href']
movie_name = movie_search.find('span').text
movie_star = movie_search.find('span',class_='rating_num').text
try:
movie_quote = movie_search.find('p',class_='quote').text
except:
movie_quote = '该电影没有推荐语'
movie_info = [movie_item,movie_name,movie_star,movie_quote,movie_url]
movie_infos.append(movie_info)
print(movie_info)
拓展:
使用第三方模块lxml解析网页数据
安装:pip install lxml
示例:
import requests
from lxml import html
url = 'http://itdiffer.com/'
page = requests.get(url).content.decode('utf-8')
sel = html.fromstring(page)
title = sel.xpath('//article/h2/a/text()') # //表示相对路径
print(title)