一、图片读取和显示
import cv2 as cv # 图片读取cv.imread(img_path) car_img = cv.imread("car1.png") # 图片显示cv.imshow(window_name,img_mat) cv.imshow('car1', car_img) cv.waitKey(0) # 图片写入cv.imwrite(save_path,img_mat) cv.imwrite('car1_bk.jpg',car_img)
二、色彩空间转换
__author__ = 'Leo.Z' import cv2 as cv # 使用cvtColor()做色彩空间转换 def color_space_trans(img): gray = cv.cvtColor(img, cv.COLOR_RGB2GRAY) hsv = cv.cvtColor(img, cv.COLOR_RGB2HSV) yuv = cv.cvtColor(img, cv.COLOR_RGB2YUV) ycrcb = cv.cvtColor(img, cv.COLOR_RGB2YCrCb) cv.imshow('gray', gray) cv.imshow('hsv', hsv) cv.imshow('yuv', yuv) cv.imshow('ycrcb', ycrcb)
同样的,我们也可以使用cv.cvtColor(img,cv.COLOR_YUV2RGB),将其转回RGB色彩空间。
三、利用HSV色彩空间提取某个颜色

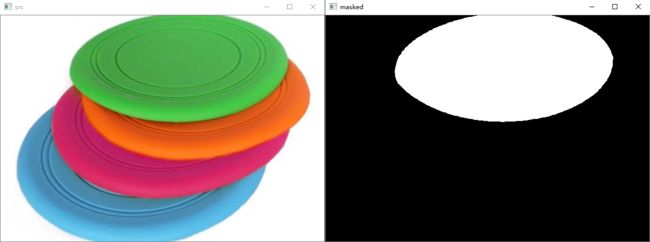
如上图,我们使用3个范围的值,可以过滤出图像中的绿色部分。如下例子:
# 使用inRange()来获取HSV中某个范围的颜色 def filter_green(): img = cv.imread('plate2.png') hsv = cv.cvtColor(img, cv.COLOR_RGB2HSV) lower = np.array([35, 43, 46]) upper = np.array([77, 255, 255]) # 这里得到的masked是一个二值mask,即符合上述范围的位置为1,不符合为0 masked = cv.inRange(hsv, lowerb=lower, upperb=upper) cv.imshow('src', img) cv.imshow('masked', masked) cv.waitKey(0)
四、分离和合并通道
def split_merge_channel(): img = cv.imread('girl1.png') b, g, r = cv.split(img) cv.imshow('blue', b) cv.imshow('green', g) cv.imshow('red', r) # 修改绿色通道的值 r[:] = 100 # 再将三个通道合并起来 merged = cv.merge([b, g, r]) cv.imshow('merged', merged) cv.waitKey(0)
注意:默认用cv.imread(img_path)读进来的彩色图像是RGB的,但是从矩阵中来看,B是处于img[:,:,0]位置的,G在img[:,:,1],R在img[:,:,2]。如果使用cv.cvtColor(img,cv.COLOR_RGB2BGR)转换,则是将R和B的位置换了一下,但RGB的顺序还是2->1->0。
所以,一般使用默认读入的图像数据就好了。
五、图片的加减乘除
def add_img(img1, img2): img_add = cv.add(img1, img2) cv.imshow('add', img_add) def sub_img(img1, img2): img_sub = cv.subtract(img1, img2) cv.imshow('sub', img_sub) def mul_img(img1, img2): img_sub = cv.multiply(img1, img2) cv.imshow('multi', img_sub) def div_img(img1, img2): img_sub = cv.divide(img1, img2) cv.imshow('div', img_sub) image1 = cv.imread('WindowsLogo.jpg') image2 = cv.imread('LinuxLogo.jpg') cv.imshow('windows', image1) cv.imshow('linux', image2) add_img(image1, image2) sub_img(image1, image2) mul_img(image1, image2) div_img(image1, image2) cv.waitKey(0)

最左边两张图是原图,add是两图相加,当windows加上linux图片时,部分像素值超过255,被截取为255,所以显示为白色的linux字样。减法刚好相反,减去linux后,得到linux字样的负数,截取为0,所以显示为黑色。乘法中,linux字样的值为255,乘以对应windows中的像素,远超255,截取为255,显示白色。周边有一些彩色的点,是因为Linux的原图在那个位置可能有一定的噪声,稍微大于0,所以乘以windows中对应像素,显示彩色斑点。除法同样是这样。
六、计算图像均值和方差
# 计算均值和方差 def img_mean(img1, img2): m1 = cv.mean(img1) m2 = cv.mean(img2) print(m1) # 输出(128.05269531250002, 109.60858072916668, 62.55748697916667, 0.0) print(m2) # 输出(15.0128125, 15.0128125, 15.0128125, 0.0) # 同时计算均值和方差 def img_dev(img1, img2): m1, d1 = cv.meanStdDev(img1) m2, d2 = cv.meanStdDev(img2) print(m1, d1) #m1:[[128.05269531],[109.60858073],[ 62.55748698]] #d1:[[54.60093646],[45.52335089],[50.01800277]] print(m2, d2) #m2:[[15.0128125],[15.0128125],[15.0128125]] #d2:[[58.14062149],[58.14062149],[58.14062149]]
七、图片的逻辑计算
def logic_demo(img1, img2): # 逻辑与 img_and = cv.bitwise_and(img1, img2) # 逻辑或 img_or = cv.bitwise_or(img1, img2) # 逻辑非(像素取补) img_not = cv.bitwise_not(img1) cv.imshow('and', img_and) cv.imshow('or', img_or) cv.imshow('not', img_not)

使用bitwise_add,用mask来过滤图像:
# 使用inRange()来获取HSV中某个范围的颜色 def filter_green(): img = cv.imread('plate2.png') hsv = cv.cvtColor(img, cv.COLOR_RGB2HSV) lower = np.array([35, 43, 46]) upper = np.array([77, 255, 255]) # 这里得到的masked是一个二值mask,即符合上述范围的位置为1,不符合为0 masked = cv.inRange(hsv, lowerb=lower, upperb=upper) cv.imshow('src', img) cv.imshow('masked', masked) dst = cv.bitwise_and(img, img, mask=masked) cv.imshow('dst', dst) cv.waitKey(0)

八、addWeighted函数(图片加权求和)
def contract_brightness_demo(image, weight, bright): h, w, c = image.shape black = np.zeros([h, w, c], dtype=image.dtype) dst = cv.addWeighted(image, weight, black, 1 - weight, bright) cv.imshow('dst', dst)
contract_brightness_demo(img1,1.5,50)
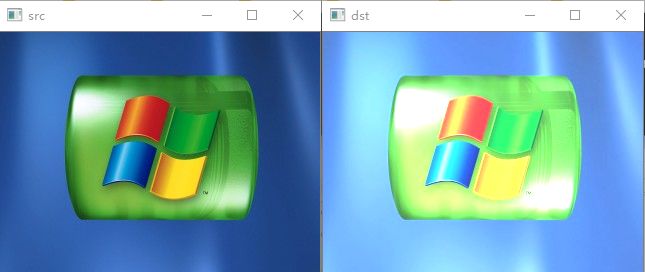
上述代码中调用addWeight函数,weight=1.5,即原图权重为1.5,由于第二张图片为全0(黑色),所以不管权重是多少都不产生效果。
addWeight(img1,weight1,img2,weight2,gamma,dst)函数的参数说明:
img1:第一张图片
weight1:第一张图片占的权重
img2:第二章图片
weight2:第二章图片占的权重
gamma:在最终结果上加减多少值
dst:图片输出,也可以用返回接受,即dst = addWeight(...)
九、ROI与泛洪填充
ROI:region of interest,感兴趣区域。
按像素差值范围泛洪填充:
# 从图片某个点开始泛洪填充,注意mask的h和w都需要比原图大2个像素 def fill_color_demo(image): cv.imshow('src', image) copy_img = image.copy() h, w = image.shape[:2] mask = np.zeros([h + 2, w + 2], np.uint8) cv.floodFill(copy_img, # 被填充图片 mask, # mask的值都为0,表示都需要填充 (30, 30), # 以(30,30)点作为起始点 (0, 255, 255), # 填充为黄色 (100, 100, 100), # 最低起始值为(30,30)的BGR值减去(100,100,100) (50, 50, 50), # 最高值为(30,30)的BGR加上(50,50,50) cv.FLOODFILL_FIXED_RANGE) # 按像素Diff范围填充 cv.imshow("fill color demo", copy_img)

按mask来泛洪填充:
def fill_binary(): # 创建一个图片,中心的一个200x200的正方形为白色255,其余部分为黑色0 image = np.zeros([400, 400, 3], np.uint8) image[100:300, 100:300, :] = 255 cv.imshow("fill binary", image) # 创建一个mask,比被填充图片hw都大2像素,单通道 mask = np.ones([402, 402, 1], np.uint8) # 中间200x200部分为0,表示需要填充,其余部分为1,表示不需要填充 mask[101:301, 101:301] = 0 # (200,200)为种子点即起始点,(100,2,255)为填充颜色 cv.floodFill(image, mask, (200, 200), (100, 2, 255), cv.FLOODFILL_MASK_ONLY) cv.imshow('filled binary', image)

十、平滑(模糊)操作
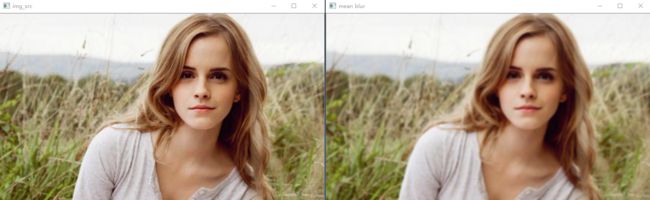
均值平滑:
# 均值模糊 def mean_blur(image): img_blur = cv.blur(image, (5, 5)) cv.imshow('mean blur', img_blur)
方框平滑:
def box_blur(image): img_blur = cv.boxFilter(image, -1, (5, 5), normalize=True) cv.imshow('box blur', img_blur) img_blur2 = cv.boxFilter(image, -1, (5, 5), normalize=False) cv.imshow('box blur 2', img_blur2)
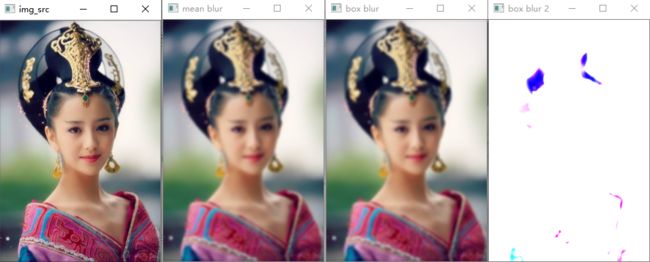
在方框平滑中,当normalize = True时,和均值平滑是一样的,即kernel覆盖区域的像素值加起来做平均。而当normalize=False时,只将像素值加起来,而不做平均,所以超过255部分全部截断为255,呈现白色。
中值平滑:
# 中值模糊,用于去除校验噪声很有用 def median_blur(image): # 中值模糊要求的ksize为一个整数 img_blur = cv.medianBlur(image, 5) cv.imshow('median blur', img_blur)
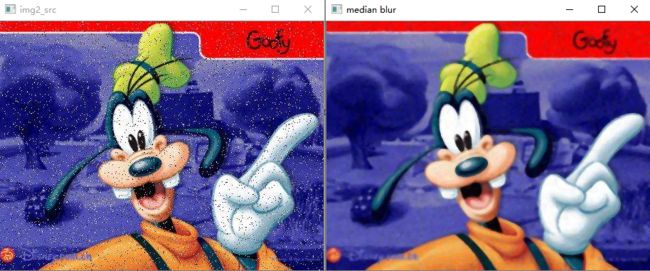
自定义模糊:
# 自定义滤波 def custom_blur(image): # 定义一个filter,均值滤波器 filter1 = np.ones((5, 5), np.float32) / 25 img = cv.filter2D(image, -1, kernel=filter1) cv.imshow('img', img)
效果与均值模糊一样。
自定义filter:
def custom_filter(image): # 定义一个拉普拉斯算子 filter2 = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]]) img2 = cv.filter2D(image, -1, kernel=filter2) cv.imshow('img2', img2)
我们可以利用拉普卡斯算子做图像锐化:
def sharpen_image(image): # 另一种拉普拉斯算子 filter = np.array([[0, -1, 0], [-1, 4, -1], [0, -1, 0]]) img = cv.filter2D(image, -1, kernel=filter) cv.imshow('img', img) # filter的中心为5,相当于上面的拉普拉斯算子加上了原图像 filter2 = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]]) shapen_img = cv.filter2D(image, -1, kernel=filter2) cv.imshow('shapen_img', shapen_img)