软考部分知识点
[1] 各种排序算法比较
堆排序(使用大堆,升序)从基本实现原理来说也是一种选择排序,它同样是确定了位置选择符合位置的元素,但是堆排序是更加优化的选择排序的版本,它利用了堆的特性。父结点的值大于子结点,且满足完全二叉树,大大提高了选择排序的效率。
快速排序是一种在实际应用中经常用到的排序算法,它的应用场景是大规模的数据排序,并且实际性能要好于归并排序。它的基本原理是从数组中选取一个元素,把所有大于这个元素的数都放到它的后面,所有小于这个元素的数都放到它的前面,然后这个元素就把原数组切分成了两个部分,再分别对这个两个部分进行同样的操作,直到数组不能再切分的时候,此时数组为有序。
“归并”的含义是将两个或两个以上的有序表组合成一个新的有序表,归并排序和快排一样也采用的是分治的思想,它的基本原理是通过对若干个有序结点序列的合并为一个有序序列来实现排序的。
选择排序的排序思想就和它的名字一样,每次通过从无序的数组中选择出一个最小的(要求升序排列)数把他放到数组的最前面。再依次找次小的数字放到数组无序区的最前。直到数组为有序。
插入排序是一种较为简单的排序算法,它的基本思想是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
形象的可以理解为打扑克抓拍的过程,通常我们右手抓牌,没抓一张牌,就放到左手,抓下一张牌后,会把这张牌依次与左手上的牌比较,并把它插入到一个合适的位置(按牌面大小)。
希尔排序是对直接插入排序的一种优化,实质就是把直接插入排序改为了分组插入排序。其基本思想就是将整个待排序元素序列按gap(步长)分割为N个组,对每个组进行直接插入排序,然后在减小gap(步长)再进行直接插入排序,直到gap达到最小时,即数组基本达到有序时,再对数组进行直接插入排序,此时直接插入排序就可以达到最高效率。
冒泡排序(这里指升序)是一种非常简单直观的排序方式,它是一种交换式的排序方法,基本思想就是相近的两个数字作比较,小的放到前面,大的放后面,按照这个规则从头向后比较,最大的数就被换到了数组尾。
基数排序(升序)是一种非比较式的排序方式,和之前博文中提到的快排,冒泡排序,插入排序这些排序算法不一样,它没有使用任何交换的方式,它的基本思想是通过分配的方法把元素从小到大分配,以到达排序的作用。
排序算法 |
时间复杂度 |
空间复杂度 |
稳定性
|
||
最好情况 |
平均情况 |
最坏情况 |
辅助空间 |
||
直接插入 |
O(n) |
O(n2) |
O(n2) |
O(1) |
稳定 |
简单选择 |
O(n2) |
O(n2) |
O(n2) |
O(1) |
不稳定 |
冒泡排序 |
O(n) |
O(n2) |
O(n2) |
O(1) |
稳定 |
希尔排序 |
- |
O(n1.3) |
- |
O(1) |
不稳定 |
快速排序 |
O(nlogn) |
O(nlogn) |
O(n2) |
O(logn) |
不稳定 |
堆排序 |
O(nlogn) |
O(nlogn) |
O(nlogn) |
O(1) |
不稳定 |
归并排序 |
O(nlogn) |
O(nlogn) |
O(nlogn) |
O(n) |
稳定 |
基数排序 |
O(d(n+rd)) |
O(d(n+rd)) |
O(d(n+rd)) |
O(td) |
稳定 |
注:基数排序复杂度中,r为关键字的基数,d为长度,n为关键字的个数 |
|||||
[2] kmp模式匹配算法---next函数求解
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是实现一个next()函数,函数本身包含了模式串的局部匹配信息。时间复杂度O(m+n)。
求解next [ j ] 值的思路
j-1对应的串与next[ j-1]对应的串进行比较,若相等,则next[ j ]=next[j-1]+1;若不相等,则将j-1对应的串与next[ next [ j-1 ] ]对应的串进行比较,循环直到相等或与next[ 1 ]比较,若都不等,则为next函数中的其他情况。
例子
在字符串的KMP模式匹配算法中,需先求解模式串的next函数值,其定义如下式所示,若模式串p为“aaabaaa”,则其next函数值为( )。
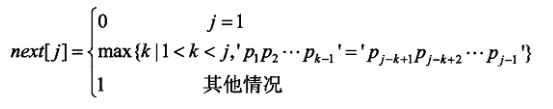
求解:
① next[1]=0,next[2]=1
② 第三位的next值:第2位的模式串为a ,对应的next值为1;将第二位的模式串a与第一位的模式串a进行比较,相等;则next[3]=1+1=2
③ 第四位的next值:第3位的模式串为a ,对应的next值为2;将第三位的模式串a与第二位的模式串a进行比较,相同,则next[4]=2+1=3
④ 第五位的next值:第四位的模式串为b,对应的next值为3;将第四位的模式串b与第三位的模式串a进行比较,不相等;第三位的a对应的next值为2,则将第四位的模式串b与第二位的模式串a进行比较,不相等;第二位的a对应的next值为1,则将第四位的模式串b与第一位的a进行比较,不相等,则next[5]=1(其他情况为1)(若第四位的模式串与第一位的进行比较相等,则next[5]=next[2]+1=1+1=2)
⑤ 第六位的next值:第五位的模式串为a,对应的next值为1;将第五位的模式串a与第一位的模式中a进行比较,相同,则next[6]=1+1=2
⑥ 第七位的next值:第六位的模式串为a,对应的next值为2;将第六位的模式串a与第二位的模式串a进行比较,相等;则next[7]=2+1=3
所以p对应的next值为0123123
[3] 数据库范式
假设磁盘每磁道有18个扇区,系统刚完成了10号柱面的操作,当前移动臂在13号柱面上,进程的请求序列如表3.3所示。若系统采用SCAN(扫描)调度算法,则系统响应序列为(1);若系统采用CSCAN(单向扫描)调度算法,则系统响应序列为(2)。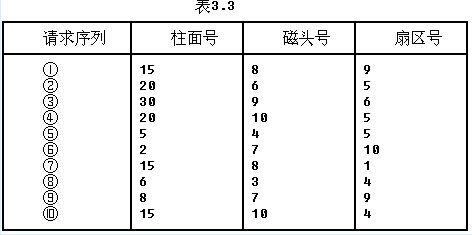
解析:SCAN算法不仅要考虑欲访问的磁道与当前磁道的距离,更优先考虑磁头的当前移动方向。由题意知,当前磁头正在由里向外移动(因为从10号柱面移动到13号柱面),所以下一个柱面应该是15号,题目中有3个柱面号为15的请求序列,选择扇区号最小的请求序列。如果扇区号也相同,则选择磁头号小的,因此由里到外的系统响应序列为⑦→⑩→①→②→④→③。当移动臂位于30号柱面时,由于30号柱面是最外层的柱面,因此移动臂开始由外往里移动,后续的系统响应序列应为⑨→⑧→⑤→⑥。CSCAN在SCAN的基础上规定,磁头只能做单向移动,本题中只能由里向外移动,因此系统响应序列为⑦→⑩→①→②→④→③→⑥→⑤→⑧→⑨。
在如下所示的进程资源图中,该进程资源图是 (28)

B.P1、P2、P3都是阻塞节点,该图不可以化简,是死锁的
C.P2是阻塞节点,P1、P3是非阻塞节点,该图可以化简,是非死锁的
D.P1、P2是非阻塞节点,P3是阻塞节点,该图不可以化简,是死锁的
解析:对于进程来说,箭头入的方向为已占用的资源,出的方向为还需要的资源。
图中p1已有一个资源R1,还需要一个R2;
P2已有一个资源R2,还需要一个R1;
P3已有一个资源R1和一个资源R2,还需要一个R2
R1共有2个资源,都被占用了,所以P2是阻塞的;
R2共有3个资源,被占用2个,还剩一个,所以P1,P3是非阻塞的;
因为R2还剩一个,P1可以满足条件,当P1运行完后释放掉资源R1一个和R2一个,使得P1和P3都变为非阻塞节点,可以得到资源并运行完毕,所以图是可以化简的。
所以选择B