Java使用Jsoup和Selenium抓取西瓜小视频
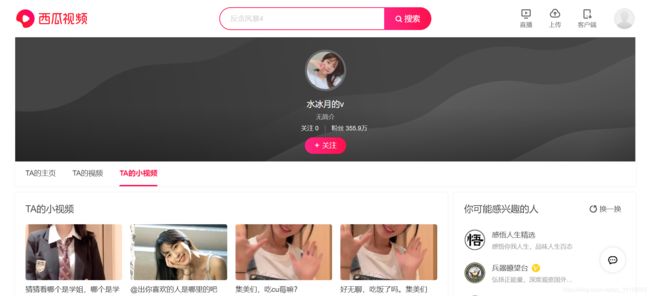
最近在家里无聊每天刷头条,看到一个很可爱的小姐姐,突然蹦出一个主意,就是想把它这些视频全部搞下来存到本地。网上搜了一下,发现这些视频其实是来自西瓜视频,根据用户名搜索就找到了。刚好会一点爬虫,这下就好办了。

跟Python的requests和bs4一样,Java也有HttpClient和Jsoup分别用于发送请求和解析网页。因为Jsoup同时也具备发送请求的功能,并且本例也不涉及复杂的请求,所以这里仅使用Jsoup即可。
研究了一下:首先点到"TA的小视频"选项卡(小视频首页),下面会有视频列表,每个标签里面包含了视频详情页的地址,然后进到视频详情页,这个页面内容加载一会之后会把视频的实际地址暴露出来,最后根据这个地址去把视频下载就OK了。
很快,写了一段代码:首先请求小视频首页的地址得到页面内容, 然后把所有视频标签解析得到各自的详情页地址,接着遍历这些地址进行请求得到各自的详情页内容,最后解析拿到视频实际地址就可以下载了。
跑了一下,很可惜,遇到了两个难题
- 不管是视频列表页还是视频详情页,直接请求拿到的页面内容都是一堆js代码:它们的页面内容都是js加载生成的。
- 视频列表页刚进去只加载一部分,滚动条下拉才会继续加载更多内容。
遇到这种情况,让你不得不使用Selenium了。其实,Jsoup+Selenium是一对黄金搭档,唯一不好的就是Selenium也具备一点解析网页的功能使得作用有点重叠(强迫症觉得)。
到此,完整思路如下
- 首先使用Selenium打开小视频首页,然后一直下拉滚动条直到视频列表全部加载出来,接着把网页内容交给Jsoup解析,得到所有小视频的详情页地址。
- 使用Selenium分别打开每个小视频详情页(多线程并行),等到加载完成视频实际地址暴露出来之后,就可以使用Jsoup去下载视频了。
成果展示
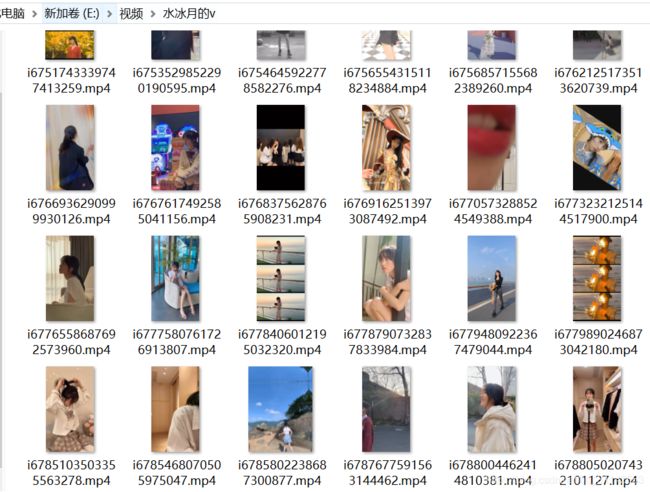
项目展示
1、pom文件,引入Jsoup和Selenium的依赖。
4.0.0
cn.zhh
crawl-xigua-video
1.0-SNAPSHOT
org.jsoup
jsoup
1.12.1
org.seleniumhq.selenium
selenium-chrome-driver
3.141.59
org.apache.maven.plugins
maven-compiler-plugin
UTF-8
1.8
1.8
2、Java代码,配置小视频首页地址和下载目录,把浏览器驱动放在指定位置。
package cn.zhh;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.openqa.selenium.Keys;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.interactions.Actions;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Collections;
import java.util.Objects;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* 主类
* 修改“小视频首页”和“存放目录”之后运行main函数即可
*
* @author Zhou Huanghua
*/
@SuppressWarnings("all")
public class Application {
/**
* 小视频首页,按需修改
*/
private static final String MAIN_PAGE_URL = "https://www.ixigua.com/home/3276166340814919/hotsoon/";
/**
* 存放目录,按需修改
*/
private static final String FILE_SAVE_DIR = "C:/Users/SI-GZ-1766/Desktop/MP4/";
/**
* 线程池,按需修改并行数量。实际开发请自定义避免OOM
*/
private static final ExecutorService EXECUTOR = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
/**
* 谷歌浏览器参数
*/
private static final ChromeOptions CHROME_OPTIONS = new ChromeOptions();
static {
// 驱动位置
System.setProperty("webdriver.chrome.driver", "src/main/resources/static/chromedriver.exe");
// 避免被浏览器检测识别
CHROME_OPTIONS.setExperimentalOption("excludeSwitches", Collections.singletonList("enable-automation"));
}
/**
* main函数
*
* @param args 运行参数
* @throws InterruptedException 睡眠中断异常
*/
public static void main(String[] args) throws InterruptedException {
// 获取小视频列表的div元素,批量处理
Document mainDoc = Jsoup.parse(getMainPageSource());
Elements divItems = mainDoc.select("div[class=\"BU-CardB UserDetail__main__list-item\"]");
// 这里使用CountDownLatch关闭线程池,只是避免执行完一直没退出
CountDownLatch countDownLatch = new CountDownLatch(divItems.size());
divItems.forEach(item ->
EXECUTOR.execute(() -> {
try {
Application.handleItem(item);
} catch (Exception e) {
e.printStackTrace();
}
countDownLatch.countDown();
})
);
countDownLatch.await();
EXECUTOR.shutdown();
System.exit(0);
}
/**
* 获取首页内容
*
* @return 首页内容
* @throws InterruptedException 睡眠中断异常
*/
private static String getMainPageSource() throws InterruptedException {
ChromeDriver driver = new ChromeDriver(CHROME_OPTIONS);
try {
driver.get(MAIN_PAGE_URL);
long waitTime = Double.valueOf(Math.max(3, Math.random() * 5) * 1000).longValue();
TimeUnit.MILLISECONDS.sleep(waitTime);
long timeout = 30_000;
// 循环下拉,直到全部加载完成或者超时
do {
new Actions(driver).sendKeys(Keys.END).perform();
TimeUnit.MILLISECONDS.sleep(waitTime);
timeout -= waitTime;
} while (!driver.getPageSource().contains("已经到底部,没有新的内容啦")
&& timeout > 0);
return driver.getPageSource();
} finally {
driver.close();
}
}
/**
* 处理每个小视频
*
* @param div 小视频div标签元素
* @throws Exception 各种异常
*/
private static void handleItem(Element div) throws Exception {
String href = div.getElementsByTag("a").first().attr("href");
String src = getVideoUrl("https://www.ixigua.com" + href);
// 有些blob开头的(可能还有其它)暂不处理
if (src.startsWith("//")) {
Connection.Response response = Jsoup.connect("https:" + src)
// 解决org.jsoup.UnsupportedMimeTypeException: Unhandled content type. Must be text/*, application/xml, or application/xhtml+xml. Mimetype=video/mp4, URL=
.ignoreContentType(true)
// The default maximum is 1MB.
.maxBodySize(100 * 1024 * 1024)
.execute();
Files.write(Paths.get(FILE_SAVE_DIR, href.substring(1) + ".mp4"), response.bodyAsBytes());
} else {
System.out.println("无法解析的src:[" + src + "]");
}
}
/**
* 获取小视频实际链接
*
* @param itemUrl 小视频详情页
* @return 小视频实际链接
* @throws InterruptedException 睡眠中断异常
*/
private static String getVideoUrl(String itemUrl) throws InterruptedException {
ChromeDriver driver = new ChromeDriver(CHROME_OPTIONS);
try {
driver.get(itemUrl);
long waitTime = Double.valueOf(Math.max(5, Math.random() * 10) * 1000).longValue();
long timeout = 50_000;
Element v;
/**
* 循环等待,直到链接出来
* ※这里可以考虑浏览器驱动自带的显式等待()和隐士等待
*/
do {
TimeUnit.MILLISECONDS.sleep(waitTime);
timeout -= waitTime;
} while ((Objects.isNull(v = Jsoup.parse(driver.getPageSource()).getElementById("vs"))
|| Objects.isNull(v = v.getElementsByTag("video").first()))
&& timeout > 0);
return v.attr("src");
} finally {
driver.close();
}
}
}完整项目地址:https://github.com/zhouhuanghua/crawl-xigua-video