Sharding-JDBC核心概念。
LogicTable
数据分片的逻辑表,对于水平拆分的数据库(表),同一类表的总称。
例:上一篇文章为基础,用户信息表拆分为2张表,分别是t_order_0、t_order_1,他们的逻辑表名为t_order。
ActualTable
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0、t_order_1。
DataNode
数据分片的最小单元。由数据源名称和数据表组成,例:test_msg0.t_order_0。配置时默认各个分片数据库的表结构均相同,直接配置逻辑表和真实表对应关系即可。
ShardingColumn
分片字段。用于将数据库(表)水平拆分的关键字段。SQL中如果无分片字段,将执行全路由,性能较差。Sharding-JDBC支持多分片字段。
ShardingAlgorithm
分片算法。Sharding-JDBC通过分片算法将数据分片,支持通过等号、BETWEEN和IN分片。分片算法目前需要业务方开发者自行实现,可实现的灵活度非常高。未来Sharding-JDBC也将会实现常用分片算法,如range,hash和tag等。
分库分表配置
分表分库配置会涉及如下类:
TableRule 表规则配置对象
ShardingRule 分库分表规则配置对象
ShardingStrategy 分片策略
ShardingAlgorithm 分片算法
举例:安装上一篇文章讲过的demo,分库分表策略配置方法进行debug:

进入方法
TableRule.builder("t_order")
方法内容如下;
public static TableRule.TableRuleBuilder builder(String logicTable) {
return new TableRule.TableRuleBuilder(logicTable);
}
方法实现一个tableRule调用内部类;
public static class TableRuleBuilder {
private final String logicTable;
private boolean dynamic;
private List actualTables;
private DataSourceRule dataSourceRule;
private Collection dataSourceNames;
private DatabaseShardingStrategy databaseShardingStrategy;
private TableShardingStrategy tableShardingStrategy;
private String generateKeyColumn;
private Class keyGeneratorClass;
public TableRule.TableRuleBuilder dynamic(boolean dynamic) {
this.dynamic = dynamic;
return this;
}
public TableRule.TableRuleBuilder actualTables(List actualTables) {
this.actualTables = actualTables;
return this;
}
public TableRule.TableRuleBuilder dataSourceRule(DataSourceRule dataSourceRule) {
this.dataSourceRule = dataSourceRule;
return this;
}
public TableRule.TableRuleBuilder dataSourceNames(Collection dataSourceNames) {
this.dataSourceNames = dataSourceNames;
return this;
}
public TableRule.TableRuleBuilder databaseShardingStrategy(DatabaseShardingStrategy databaseShardingStrategy) {
this.databaseShardingStrategy = databaseShardingStrategy;
return this;
}
public TableRule.TableRuleBuilder tableShardingStrategy(TableShardingStrategy tableShardingStrategy) {
this.tableShardingStrategy = tableShardingStrategy;
return this;
}
public TableRule.TableRuleBuilder generateKeyColumn(String generateKeyColumn) {
this.generateKeyColumn = generateKeyColumn;
return this;
}
public TableRule.TableRuleBuilder generateKeyColumn(String generateKeyColumn, Class keyGeneratorClass) {
this.generateKeyColumn = generateKeyColumn;
this.keyGeneratorClass = keyGeneratorClass;
return this;
}
public TableRule build() {
KeyGenerator keyGenerator = null;
if(null != this.generateKeyColumn && null != this.keyGeneratorClass) {
keyGenerator = KeyGeneratorFactory.createKeyGenerator(this.keyGeneratorClass);
}
return new TableRule(this.logicTable, this.dynamic, this.actualTables, this.dataSourceRule, this.dataSourceNames, this.databaseShardingStrategy, this.tableShardingStrategy, this.generateKeyColumn, keyGenerator);
}
@ConstructorProperties({"logicTable"})
public TableRuleBuilder(String logicTable) {
this.logicTable = logicTable;
}
}
从内部类来看,类初始化时,将图中代码传入配置参数,进行初始化赋值,此时this的各个参数如下图
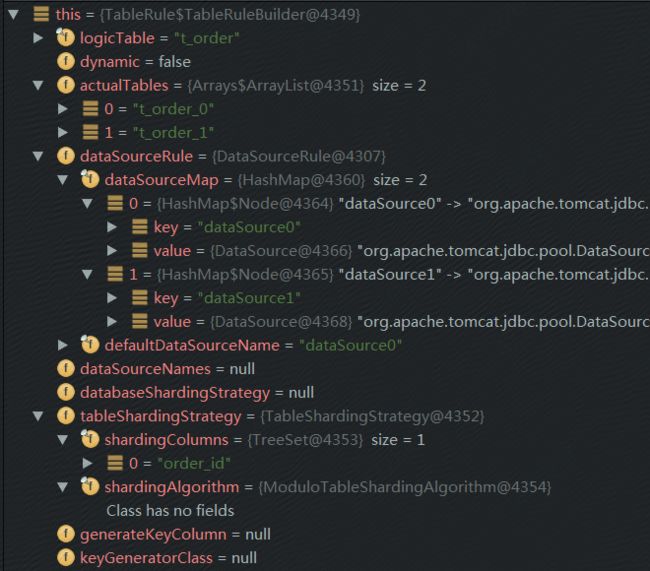
最终会调用build方法:
public TableRule build() {
KeyGenerator keyGenerator = null;
if(null != this.generateKeyColumn && null != this.keyGeneratorClass) {
keyGenerator = KeyGeneratorFactory.createKeyGenerator(this.keyGeneratorClass);
}
return new TableRule(this.logicTable, this.dynamic, this.actualTables, this.dataSourceRule, this.dataSourceNames, this.databaseShardingStrategy, this.tableShardingStrategy, this.generateKeyColumn, keyGenerator);
}
最终初始化TableRule:
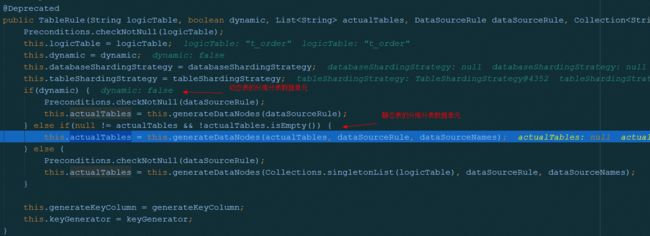
大多数业务场景下,我们使用静态分库分表数据单元,即 DataNode。如上文注释处 静态表的分库分表数据单元 处所见,分成两种判断,实质上第一种是将logicTable作为 actualTable,即在库里不进行分表,是第二种的一种特例。
我们来看看 generateDataNodes()方法:
参数说明:
/**
* 生成静态数据分片节点
*
* @param actualTables 真实表
* @param dataSourceRule 数据源配置对象
* @param actualDataSourceNames 数据源名集合
* @return 静态数据分片节点
*/
先看getDataSourceNames方法; 根据 数据源配置对象 和 数据源名集合 获得 最终的数据源名集合
private Collection getDataSourceNames(DataSourceRule dataSourceRule, Collection actualDataSourceNames) {
return (Collection)(null == dataSourceRule?Collections.emptyList():(null != actualDataSourceNames && !actualDataSourceNames.isEmpty()?actualDataSourceNames:dataSourceRule.getDataSourceNames()));
}
private List generateDataNodes(List actualTables, DataSourceRule dataSourceRule, Collection actualDataSourceNames) {
Collection dataSourceNames = this.getDataSourceNames(dataSourceRule, actualDataSourceNames);
ArrayList result = new ArrayList(actualTables.size() * (dataSourceNames.isEmpty()?1:dataSourceNames.size()));
Iterator i$ = actualTables.iterator();
while(true) {
while(i$.hasNext()) {
String actualTable = (String)i$.next();
if(DataNode.isValidDataNode(actualTable)) {
result.add(new DataNode(actualTable));
} else {
Iterator i$1 = dataSourceNames.iterator();
while(i$1.hasNext()) {
String dataSourceName = (String)i$1.next();
result.add(new DataNode(dataSourceName, actualTable));
}
}
}
return result;
}
}
最终返回dataNode列表如下图所示:
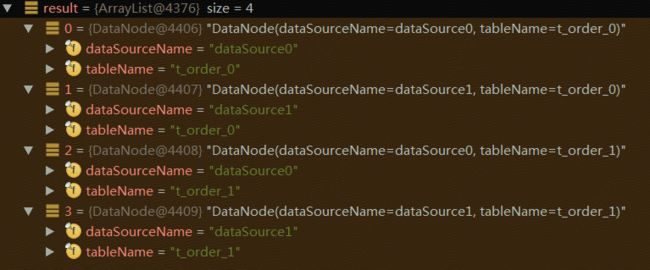
分库ShardingRule与分表结构相同;
ShardingAlgorithm
我们定义的策略类,继承了一下接口:
public class ModuloDatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm
SingleKeyDatabaseShardingAlgorithm接口的定义如下:
public interface SingleKeyDatabaseShardingAlgorithm> extends SingleKeyShardingAlgorithm, DatabaseShardingAlgorithm {
}
可知继承了DatabaseShardingAlgorithm,此时
public interface DatabaseShardingAlgorithm extends ShardingAlgorithm {
}
SingleKeyShardingAlgorithm``接口同样继承了ShardingAlgorithm ```
public interface SingleKeyShardingAlgorithm> extends ShardingAlgorithm {
/**
* Sharding with equal operator.
*
* @param availableTargetNames available data sources or tables's names
* @param shardingValue sharding value
* @return sharding results for data sources or tables's names
*/
String doEqualSharding(Collection availableTargetNames, ShardingValue shardingValue);
/**
* Sharding with in operator.
*
* @param availableTargetNames available data sources or tables's names
* @param shardingValue sharding value
* @return sharding results for data sources or tables's names
*/
Collection doInSharding(Collection availableTargetNames, ShardingValue shardingValue);
/**
* Sharding with between operator.
*
* @param availableTargetNames available data sources or tables's names
* @param shardingValue sharding value
* @return sharding results for data sources or tables's names
*/
Collection doBetweenSharding(Collection availableTargetNames, ShardingValue shardingValue);
}
此时关系类图如图所示:
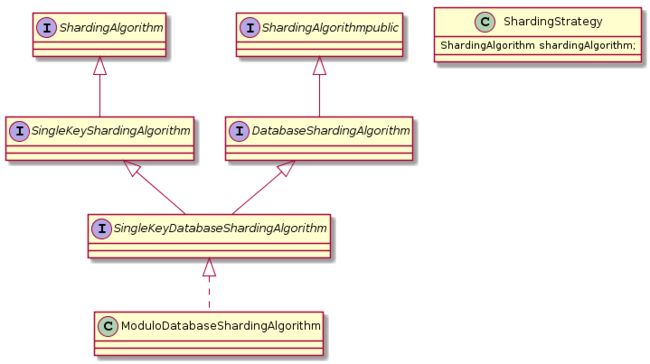
debug后,进入ShardingStrategy.java中的doSharding方法:
private Collection doSharding(final Collection> shardingValues, final Collection availableTargetNames) {
if (shardingAlgorithm instanceof NoneKeyShardingAlgorithm) {
return Collections.singletonList(((NoneKeyShardingAlgorithm) shardingAlgorithm).doSharding(availableTargetNames, shardingValues.iterator().next()));
}
if (shardingAlgorithm instanceof SingleKeyShardingAlgorithm) {
SingleKeyShardingAlgorithm singleKeyShardingAlgorithm = (SingleKeyShardingAlgorithm) shardingAlgorithm;
ShardingValue shardingValue = shardingValues.iterator().next();
switch (shardingValue.getType()) {
case SINGLE:
return Collections.singletonList(singleKeyShardingAlgorithm.doEqualSharding(availableTargetNames, shardingValue));
case LIST:
return singleKeyShardingAlgorithm.doInSharding(availableTargetNames, shardingValue);
case RANGE:
return singleKeyShardingAlgorithm.doBetweenSharding(availableTargetNames, shardingValue);
default:
throw new UnsupportedOperationException(shardingValue.getType().getClass().getName());
}
}
if (shardingAlgorithm instanceof MultipleKeysShardingAlgorithm) {
return ((MultipleKeysShardingAlgorithm) shardingAlgorithm).doSharding(availableTargetNames, shardingValues);
}
throw new UnsupportedOperationException(shardingAlgorithm.getClass().getName());
}
按照上一篇文章demo进行debug,当请求接口进行数据插入时,首先调用ModuloDatabaseShardingAlgorithm类中的doEqualSharding进行分库策略的使用。
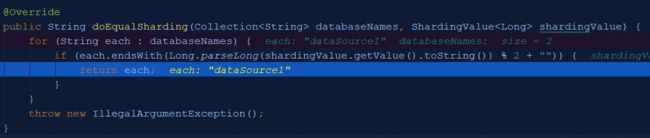
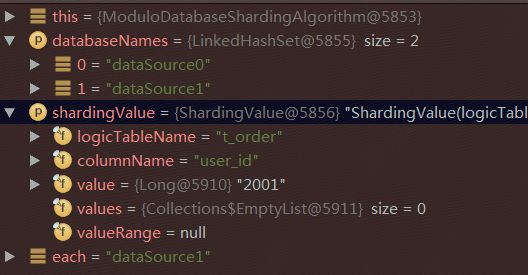
通过此方法确定数据源dataSource1;