【Python】爬虫抓取必应壁纸
一直想把必应上的壁纸批量下载下来,可惜一直没找到源网站,今天发现在天堂图片网上有必应的壁纸,所以写了一个小爬虫来爬取一下图片看看
网址在此:
http://www.ivsky.com/bizhi/bing_v1704/
首先我们需要一个函数来打开网页,获得网页源码内容,这个函数可以这样写
def getHtml(url):
#url open打开网页
page = request.urlopen(url)
html = page.read() #read()方法用于读取URL上的数据
html = str(html)
return html打开网页来分析一下,右击网页,检查
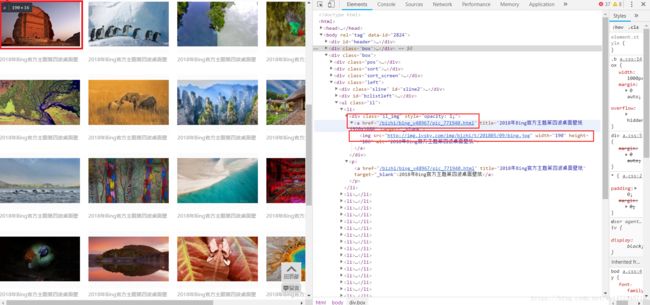
可以看到,我们需要的第一张图片包含在”/bizhi/bing_v48967/pic_771940.html” 这个页面中,要抓取需要的图片,必须先提取出图片对应的页面地址(注意,后面有一个”img src=”http://img.ivsky.com/img/bizhi/t/201805/09/bing.jpg” ,点开看一下就知道这个只是图片的缩略图,并不是我们想要的图片。第一张图片对应的网页找到了,其他的图片也一样找到对应的页面。因此我们需要一个函数,从原始的页面源代码中提取出所需要的图片对应的页面。这个函数可以这样写
#获取页面列表
def getHtmlList(html):
#根据页面的命名构造正则表达式
reg = r'
imgre = re.compile(reg)
#找出所有符合正则表达式的字符串,
htmllist = re.findall(imgre,html)
l = set()
for i in range(len(htmllist)):
#网页地址是相对路径,需要添加域名
htmllist[i] = 'http://www.ivsky.com' + htmllist[i]
#利用set来避免重复添加
if htmllist[i] not in l:
l.add(htmllist[i])
#最后得到的集合l就是图片对应的页面列表
return l
再来打开任意一张图片对应的页面
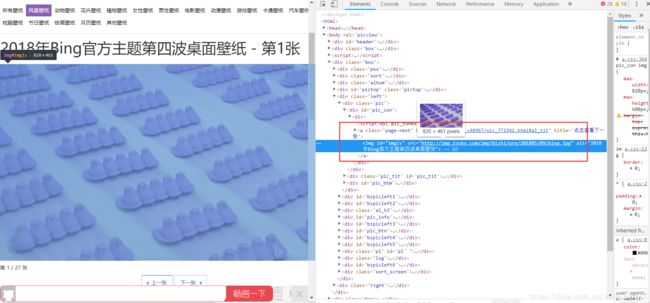
找到图片对应的路径(途中红框所示),下载图片即可。同样的我们需要一个函数来找到这个路径,并下载图片,这个函数可以这样写
def getImg(html,id):
#分析网页,提取图片地址对应的正则表达式
reg = r''</span) imgre = re.compile(reg) #re.compile() 可以把正则表达式编译成一个正则表达式对象.
imglist = re.findall(imgre,html)
#对于这个程序,每个页面只包含一张高清大图,图片地址保存在imglist[0]里面
#图片可能因为某些原因,下载不成功,执行urlretrieve函数会报错,我们使用try except来增强程序健壮性
try:
request.urlretrieve(imglist[0],'.\spider\data\\bing\%d.jpg'%id, showProcessBar)
#print("%s download success"%x)
return 0
except :
return -1
#下载成功,返回0,失败返回-1
imgre = re.compile(reg) #re.compile() 可以把正则表达式编译成一个正则表达式对象.
imglist = re.findall(imgre,html)
#对于这个程序,每个页面只包含一张高清大图,图片地址保存在imglist[0]里面
#图片可能因为某些原因,下载不成功,执行urlretrieve函数会报错,我们使用try except来增强程序健壮性
try:
request.urlretrieve(imglist[0],'.\spider\data\\bing\%d.jpg'%id, showProcessBar)
#print("%s download success"%x)
return 0
except :
return -1
#下载成功,返回0,失败返回-1同时,我们定义一个回调函数,显示每张图片的下载进度
def showProcessBar(a,b,c):
'''''回调函数
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
percent=100.0*a*b/c
if percent > 100:
percent = 100
#显示下载进度
print ('[downloading:] %.2f%%' % percent) 再定义一个函数,调用getImg,下载得到的列表当中的每一张图片
def getImage(htmllist):
i = 0
for key in htmllist:
html = getHtml(key)
html = str(html)
if (getImg(html, i) == 0):
print("%s download success"%i)
else:
print("%s download failed" %i)
i+=1所需要的函数全部完成,调用即可下载图片
url = "http://www.ivsky.com/bizhi/bing_t2824/"
h = getHtml(url)
l= getImgList(h)
getImage(l)程序执行结果
控制台输出如下
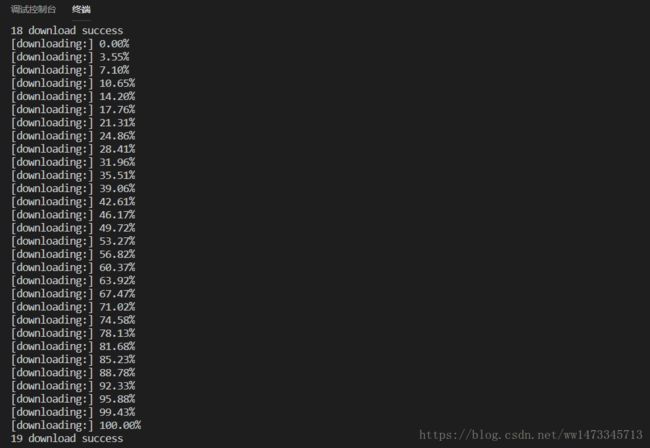
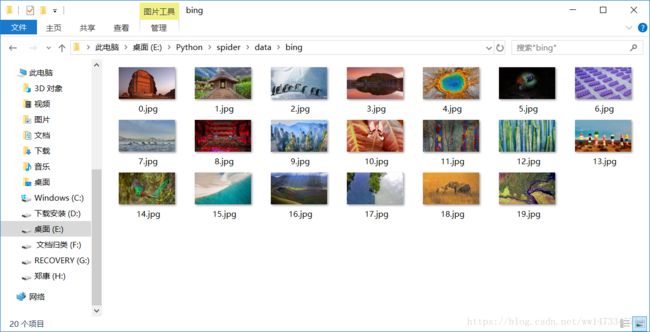
对应的文件夹下面也有了我们要的图片
程序源码可以在这里下载
https://github.com/zkangHUST/Spider/blob/master/1.py
这个程序还有很多不完美的地方,比如提取网址的正则表达式写的不好,还可以改进,或者使用beautiful soup 来提取,效果更高,另外程序是单进程的,可以多开几个进程加快下载速度。等等诸如此类的缺点还有很多,下一版本再改进吧。