简单易学python小爬虫:用requests+BeautifulSoup爬取豆瓣TOP250
爬取目标网址:https://movie.douban.com/top250
分析网站源代码,找到我们要爬取的部分。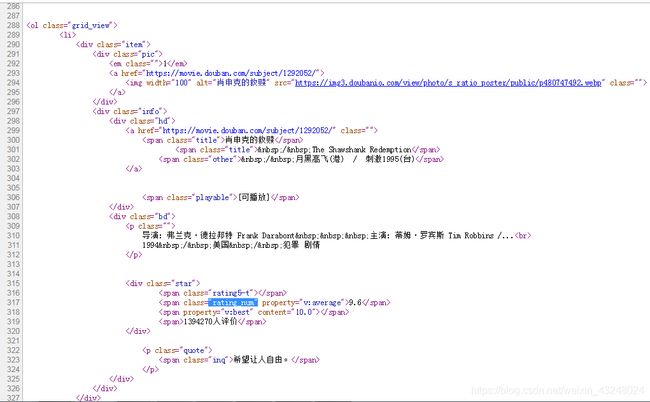
可以发现目标数据存放在ol这个节点里面,而每一部电影又是存放在li节点里面,我们可以用requests来获得这个网站的文本信息,然后用BeautifulSoup来解析,获得我们想要的数据及信息。
我是在中国慕课嵩天老师爬虫课学习的获取网页通用代码
import requests
from bs4 import BeauifulSoup
def getHTML(url):
#用try,except来捕捉异常,使程序正常运行
try:
#不论网站有无反爬机制,都要设置headers
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
r = requests.get(url,headers = headers)
r.raise_for_status
r.encoding = r.apparent_encoding
return r.text
except:
return "error"
接下来我们要来解析这个代码,获得电影的排名,名称,评分。
def parserHTML(html):
soup = BeautifulSoup(html,'lxml')
#找到所有的
ols = soup.find_all('ol')
for ol in ols:
#在ol中找到li标签,因为每一个li标签里面存储着一部电影的信息。
lis = ol.find_all('li')
for li in lis:
#找到电影的排名
index = li.find_all('em')[0]
#找到电影的名称
title = li.find_all('span',class_='title')[0]
#找到电影的评分
rate_num = li.find_all('span',class_='rating_num')[0]
#打印出一部电影的信息
print("{0:^10}\t{1:{3}^10}\t{2:^10}".format(index.string,title.string,rate_num.string,chr(12288)))
如果想要把爬取的数据存放在本地, 使用with open as f这样的代码模块,把每一次爬取的电影信息保存下来,这个代码是附加在parserHTML(html)里面。
#open(name,mode,encoding)
#name是包含文件名称的字符串
#mode决定打开文件的模式('r':只读,'w':只写,如果不存在在文件的后面追加,'a':附加在问文件的末尾)
#encoding表示我们要输入的编码方式
with open('douban250.text','a',encoding='utf-8') as f:
#把爬取到的排名,名称,评分写入文件。
f.write("{0:^10}\t{1:{3}^10}\t{2:^10}\n".format(index.string,title.string,rate_num.string,chr(12288)))
#保证数据及时从缓存存入本地。
f.flush()
这样的代码只能解析一张网页的信息,只有25部电影,要想实现爬取250部电影还要让程序自动翻页。
首先看一下网页地址翻页后变化的规律:
第一页:https://movie.douban.com/top250?start=&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
所以只要定义一个主函数,用for循环来改变start值就可以实现程序自动翻页的效果,从而爬取到后面页电影的内容。
def main(start):
url = 'https://movie.douban.com/top250?start='+str(start)
html = getHTML(url)
parserPage(html)
if __name__=='__main__':
#打印头部信息
print("{0:^10}\t{1:{3}^10}\t{2:^10}".format('排名','电影名','评分',chr(12288)))
for i in range(10):
main(i*25)
全部代码
import requests
from bs4 import BeautifulSoup
def getHTML(url):
try:
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
r = requests.get(url,headers = headers)
r.raise_for_status
r.encoding = r.apparent_encoding
return r.text
except:
return "error"
def parserPage(html):
soup = BeautifulSoup(html,'lxml')
ols = soup.find_all('ol')
for ol in ols:
lis = ol.find_all('li')
for li in lis:
index = li.find_all('em')[0]
title = li.find_all('span',class_='title')[0]
rate_num = li.find_all('span',class_='rating_num')[0]
print("{0:^10}\t{1:{3}^10}\t{2:^10}".format(index.string,title.string,rate_num.string,chr(12288)))
with open('douban250.text','a',encoding='utf-8') as f:
f.write("{0:^10}\t{1:{3}^10}\t{2:^10}\n".format(index.string,title.string,rate_num.string,chr(12288)))
f.flush()
def main(start):
url = 'https://movie.douban.com/top250?start='+str(start)
html = getHTML(url)
parserPage(html)
if __name__=='__main__':
print("{0:^10}\t{1:{3}^10}\t{2:^10}".format('排名','电影名','评分',chr(12288)))
for i in range(10):
main(i*25)
输出结果:

是不是很简单。只要了解过requests和BeautifulSoup的基本用法就可以写出这样的小爬虫。当然这个代码还有很多不完善的地方,比如代码不简洁,爬取的内容不完整等等。这是我第一篇博客,我也只是记录自己学习的内容,后面会加强学习。每天进步一点点,加油!