我们都知道,当对两个表进行关联的时候可以用sql的join语句简单的去实现,并且如果两张表的数据查询非常大,那么一般会讲小表放在左边,可以达到优化的作用,为何呢?其实我们在使用mapreduce的时候小表可以先加载到内存中,然后再与输入数据进行对比,如果匹配成功则关联输出。今天我们将介绍使用mapreduce中mapjoin与reducejoin两种方式对数据的关联并输出。
一、先看数据:
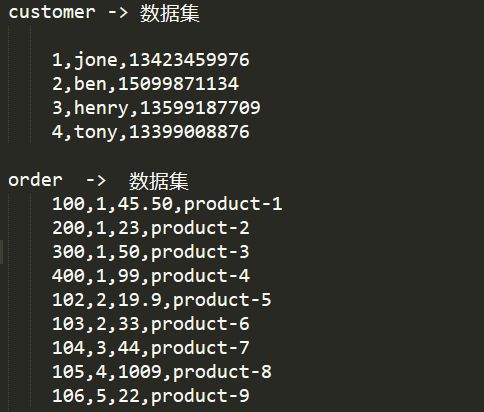
image.png
我们分别将两个数据文件放到hdfs上:

image.png
二、以 order 作为小表在 map 中进行 join,首先我们创建驱动类框架:
public class MapJoinRM extends Configured implements Tool {
//加载到内存中的对象
static Map customerMap = new HashMap();
public int run(String[] args) throws Exception {
//driver
//1) 获取配置对象
Configuration configuration = this.getConf();
//2) 创建任务对象
Job job = Job.getInstance(configuration, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
//3.1) 设置输入
Path path = new Path(args[0]);
FileInputFormat.addInputPath(job, path);
//3.2) map 的设置
job.setMapperClass(JoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//3.3 reduce 设置
//3.4 添加缓存
URI uri = new URI(args[2]);
job.addCacheFile(uri);
//3.5 设置输出
Path output = new Path(args[1]);
FileOutputFormat.setOutputPath(job, output);
//4. 提交
boolean sucess = job.waitForCompletion(true);
return sucess ? 0 : 1;
}
public static void main(String[] args) {
args = new String[]{
"hdfs://bigdata-pro01.lcy.com:9000/user/hdfs/order.txt",
"hdfs://bigdata-pro01.lcy.com:9000/user/hdfs/output66",
"hdfs://bigdata-pro01.lcy.com:9000/user/hdfs/customer.txt"
};
Configuration configuration = new Configuration();
try {
//判断是否已经存在路径
Path fileOutputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(fileOutputPath)){
fileSystem.delete(fileOutputPath, true);
}
int status = ToolRunner.run(configuration, new MapJoinRM(), args);
System.exit(status);
} catch (Exception e) {
e.printStackTrace();
}
}
}
三、实现 mapper 子类处理缓存数据以及关联逻辑的实现:
public static class JoinMapper extends Mapper{
private Text outputKey = new Text();
private Text outputValue = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//缓存数据的处理
Configuration configuration = context.getConfiguration();
URI[] uri = Job.getInstance(configuration).getCacheFiles();
Path path = new Path(uri[0]);
FileSystem fileSystem = FileSystem.get(configuration);
InputStream inputStream = fileSystem.open(path);
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line = null;
while((line = bufferedReader.readLine()) != null){
if(line.trim().length() > 0){
customerMap.put(line.split(",")[0], line);
}
}
bufferedReader.close();
inputStreamReader.close();
inputStream.close();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String lineValue = value.toString();
StringTokenizer stringTokenizer = new StringTokenizer(lineValue, ",");
while(stringTokenizer.hasMoreTokens()){
String wordValue = stringTokenizer.nextToken();
if(customerMap.get(wordValue) != null){
outputKey.set(wordValue);
outputValue.set(customerMap.get(wordValue) + lineValue);
context.write(outputKey, outputValue);
break;
}
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
}
}
四、运行程序并在控制台中命令查看关联结果:
bin/hdfs dfs -text /user/hdfs/output66/part*
运行结果如图:

image.png
大小表的关联就这么简单,接下来我们使用 reduce 的进行 join
五、由于在 reduce 中进行 join 的话是同时加载两个数据进来的,为了区分从 map 中传进来的数据,我们要自定义一个类型,设置一个变量用于标识是哪张表的数据,这样我们在reduce中才能区分哪些数据是属于哪张表的:
public class DataJoionWritable implements Writable {
private String tag;
private String data;
public DataJoionWritable() {
}
public DataJoionWritable(String tag, String data) {
this.set(tag, data);
}
public void set(String tag, String data){
this.tag = tag;
this.data = data;
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.getTag());
dataOutput.writeUTF(this.getData());
}
public void readFields(DataInput dataInput) throws IOException {
this.setTag(dataInput.readUTF());
this.setData(dataInput.readUTF());
}
public String getTag() {
return tag;
}
public void setTag(String tag) {
this.tag = tag;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
@Override
public String toString() {
return "DataJoionWritable{" +
"tag='" + tag + '\'' +
", data='" + data + '\'' +
'}';
}
}
六、为了方便使用表示常量我们创建一个常用类:
public class DataCommon {
public final static String CUSTOMER = "customer";
public final static String ORDER = "order";
}
七、创建驱动类的通用框架:
public class ReduceJoinMR extends Configured implements Tool {
public int run(String args[]) throws IOException, ClassNotFoundException, InterruptedException {
//driver
//1) 获取配置对象
Configuration configuration = this.getConf();
//2) 创建任务对象
Job job = Job.getInstance(configuration, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
//3.1) 设置输入
Path path = new Path(args[0]);
FileInputFormat.addInputPath(job, path);
//3.2) map 的设置
job.setMapperClass(JoinMapper2.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DataJoionWritable.class);
//3.3 reduce 设置
job.setReducerClass(JoinReduce2.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
//3.4 设置输出
Path output = new Path(args[1]);
FileOutputFormat.setOutputPath(job, output);
//4. 提交
boolean sucess = job.waitForCompletion(true);
return sucess ? 0 : 1;
}
public static void main(String[] args) {
//datas目录下有已存在要关联的两个数据文件
args = new String[]{
"hdfs://bigdata-pro01.lcy.com:9000/user/hdfs/datas",
"hdfs://bigdata-pro01.lcy.com:9000/user/hdfs/output100"
};
Configuration configuration = new Configuration();
try {
//判断是否已经存在路径
Path fileOutputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(fileOutputPath)){
fileSystem.delete(fileOutputPath, true);
}
int status = ToolRunner.run(configuration, new ReduceJoinMR(), args);
System.exit(status);
} catch (Exception e) {
e.printStackTrace();
}
}
}
八、接下来我们开始实现 Mapper 的数据逻辑的处理:
public static class JoinMapper2 extends Mapper{
private Text outputKey = new Text();
DataJoionWritable outputValue = new DataJoionWritable();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] values = value.toString().split(",");
if((3 != values.length) && (4 != values.length)) return;
//customer
if(3 == values.length){
String cid = values[0];
String name = values[1];
String telphone = values[2];
outputKey.set(cid);
outputValue.set(DataCommon.CUSTOMER,name + ","+telphone);
}
//order
if(4 == values.length){
String cid = values[1];
String price = values[2];
String productName = values[3];
outputKey.set(cid);
outputValue.set(DataCommon.ORDER,productName + ","+price);
}
context.write(outputKey,outputValue);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
}
}
九、使用 reduce 对数据的关联处理:
public static class JoinReduce2 extends Reducer{
private Text outputValue = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
}
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
String customerInfo = null;
List orderList = new ArrayList();
for (DataJoionWritable dataJoinWritable : values){
if(DataCommon.CUSTOMER.equals(dataJoinWritable.getTag())){
customerInfo = dataJoinWritable.getData();
}
else if(DataCommon.ORDER.equals(dataJoinWritable.getTag())){
orderList.add(dataJoinWritable.getData());
}
}
for (String orderInfo : orderList){
if(customerInfo == null) continue;
outputValue.set(key.toString() +","+ customerInfo + ","+ orderInfo);
context.write(NullWritable.get(),outputValue);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
}
}
十、使用命令查询结果如下:

image.png
由于时间过于紧迫,基本上就粘贴代码了,后续会优化,在此感谢老师的思路。。。