一次性解决你所有的编码检测问题
在日常使用中,我们难以避免会遇到编码转换问题。(如果编码是什么都不知道,请先看:什么是编码?)
而进行编码转换的前提是你知道这个字符串使用的是什么编码。
比如你使用 urllib.request.urlopen() 获取一个网页时,你特么如果不知道网页的编码会怎样?
直接 read().decode() 就可能会出现下边错误:
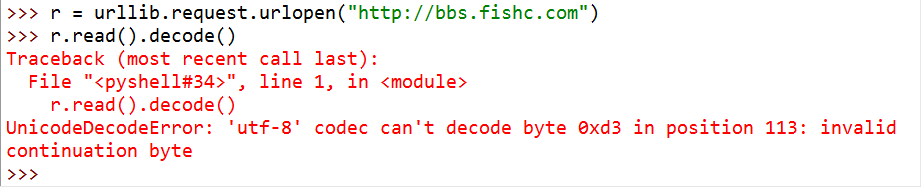
这是因为无论是 encode() 还是 decode(),默认采取的编码/解码都是 encoding="utf-8" 编码……
虽然你大 UTF-8 行迹踏遍天下,但在这神州大地,处处都有奇葩的好不?
这时候需要一个可靠的方式来检测字符串到底是什么编码,这样我们才能对症下药!
这里我向大家推荐一个不错的模块:chardet,使用它就可以检测字符串的编码。
chardet 模块可以检测以下编码:
- ASCII, UTF-8, UTF-16 (2 variants), UTF-32 (4 variants)
- Big5, GB2312, EUC-TW, HZ-GB-2312, ISO-2022-CN (Traditional and Simplified Chinese)
- EUC-JP, SHIFT_JIS, CP932, ISO-2022-JP (Japanese)
- EUC-KR, ISO-2022-KR (Korean)
- KOI8-R, MacCyrillic, IBM855, IBM866, ISO-8859-5, windows-1251 (Cyrillic)
- ISO-8859-2, windows-1250 (Hungarian)
- ISO-8859-5, windows-1251 (Bulgarian)
- windows-1252 (English)
- ISO-8859-7, windows-1253 (Greek)
- ISO-8859-8, windows-1255 (Visual and Logical Hebrew)
- TIS-620 (Thai)
chardet 模块安装方法:
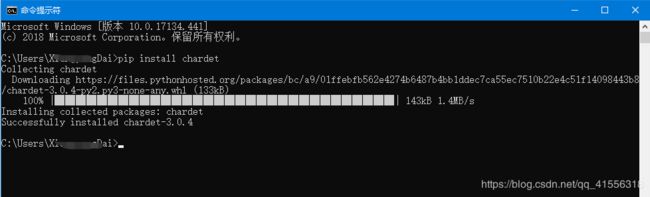
1. (推荐)使用 pip 安装,打开命令行窗口(Windows 的 cmd,Linux 的 terminal,Mac 的“终端”)
输入命令:pip install chardet
2. 下载安装包并解压: ![]() chardet-3.0.4.zip
chardet-3.0.4.zip
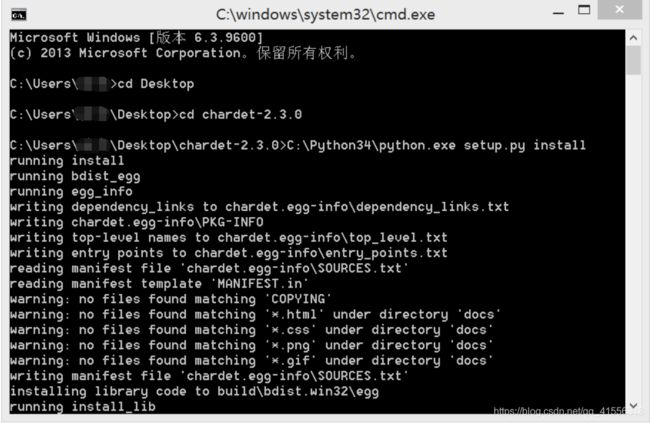
打开命令行窗口(同上),切换目录到上方解压包的文件夹,输入命令:C:\Python34\python.exe setup.py install
chardet 模块用法:
非常简单,使用该模块的 detect() 函数即可:
>>> import urllib.request
>>> response = urllib.request.urlopen("http://bbs.fishc.com").read()
>>> import chardet
>>> chardet.detect(response)
{'confidence': 0.99, 'encoding': 'GB2312'}哦,confidence 是可信度的意思……
0.99 就是 99% 确定是 'GB2312'!
年轻人,你太傲娇了,偶其实使用的是 GBK 编码(GBK 是 GB2312 的扩展)
所以你直接 decode('GB2312') 还是会报错的:(是不是很炸裂)
>>> response.decode("GB2312")
Traceback (most recent call last):
File "", line 1, in
response.decode("GB2312")
UnicodeDecodeError: 'gb2312' codec can't decode byte 0xfd in position 22581: illegal multibyte sequence 你现在有两种选择:
一、忽略识别不出的字符(GB2312 支持的汉字比较少,如果用这种方法会出现小部分乱码)
>>> response.decode("GB2312", "ignore")
……
二、(推荐)由于 GBK 是向下兼容 GB2312,因此你检测到是 GB2312,则直接用 GBK 来编码/解码
>>> if chardet.detect(response)['encoding'] == 'GB2312':
response.decode('GBK')
……