caffe训练之数据准备
在caffe框架下进行深度学习模型训练,数据准备是极为关键的一环。在其网络结构中,数据层的输入格式一般为lmdb格式,而我们常用的图像数据类型为jpg或者png等,这就需要对数据进行类型转换。本文将对这一过程的具体步骤进行描述,并针对本人在实践过程中遇到一些问题,给出解决方案。
1. 数据准备(Windows下操作)
数据分为训练集和测试集。下面针对训练集给出详细步骤,测试集准备的步骤相同。
选取50张火焰图像与50张非火焰图像,分别存放在两个文件夹中(火焰,非火焰)。将这些图片分别按规则rename并resize为256*256,然后存放至train文件夹中。如图。

这里给出rename和resize的MATLAB代码,如下。
file = dir('E:\02专业资料\14毕业论文\深度学习\测试\火焰\');
temp = length(file);
file = file(3:temp);
for n = 1 : length(file)
temp = imread(['E:\02专业资料\14毕业论文\深度学习\测试\火焰\' file(n).name]);
temp = imresize(temp,2);
temp = imresize(temp,[256 256]);
imwrite(temp, ['E:\02专业资料\14毕业论文\深度学习\测试\train\', 'F_', file(n).name]);
end在训练和测试时,输入均是用train.txt和val.txt进行描述的。这里就将根据图片数据,制作两个.txt文本。
(1)打开Windows命令行
Win + R打开运行命令框,输入cmd打开。
(2)cd 到图片数据的路径下
cd E:\02专业资料\14毕业论文\深度学习\训练\火焰
(3)输入命令生成train.txt文件
dir/s/on/b > E:\02专业资料\14毕业论文\深度学习\训练\train.txt

(5)修改上述文本,使之成为“文件名 label”格式
依次点击“编辑-->替换”,将路径替换为空,将后缀替换为label,如0或者1.
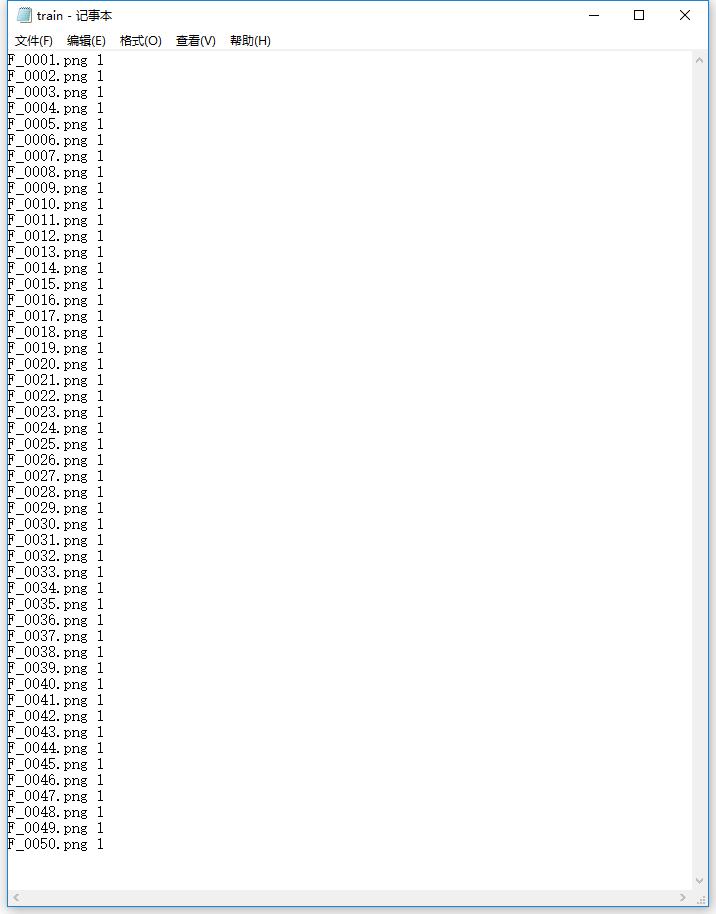
至此,训练集数据已经准备好,测试集数据的准备过程相同,在此不再赘述。
2. 格式转换(Ubuntu16.04)
(1)现将Windows上准备的数据拷贝到Ubuntu上,拷贝路径为 ./caffe/data/
(2)在 ./caffe/examples/ 下创建 fire 文件夹,将 ./caffe/examples/imagenet 下的 create_imagenet.sh 文件拷贝过来,rename为 create_fire.sh
(3)打开create_fire.sh文件,修改数据路径,然后运行,如图:
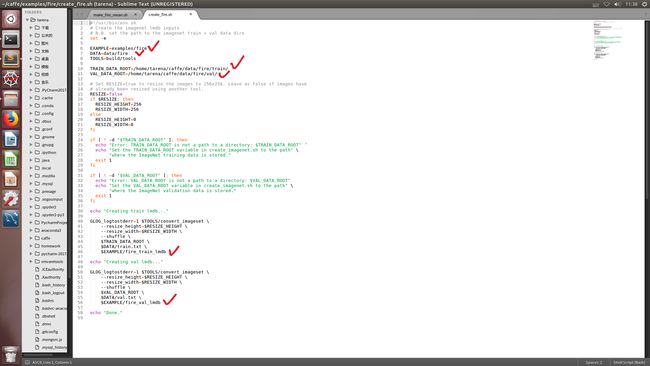
上图中画对钩的,都是需要修改的地方。
运行结果如下所示,即为成功。

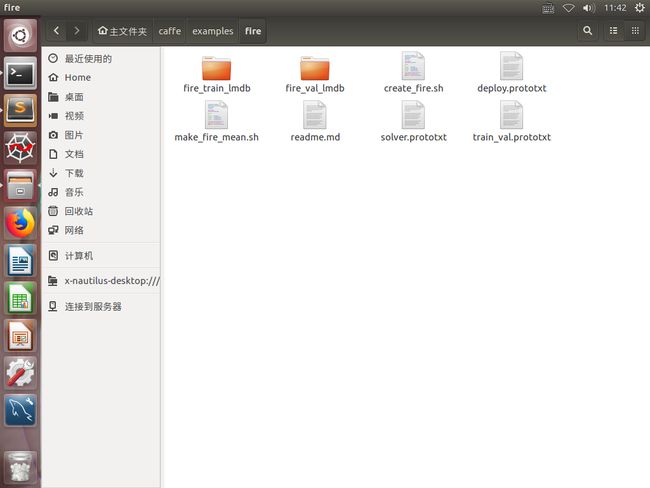
(4)得到fire_train_lmdb和fire_val_lmdb:
3. 遇到的一些问题
由于实践的时候忘记截图,姑且手动记录几条问题如下。
(1)Could not open or find file ......
出现该问题,可检查一下“文件名 label”txt文件中的文件名与图片名是否一致。本人所碰到的情况是,图片文件拷贝到Ubuntu下,图片名变为XXXX.png.png,此时由于修改文件名需要批量处理,本人懒于操作,直接将.txt文本中的.png替换成了.png.png,由此解决问题。
另外,val中的txt文本,也是需要给出label的,本人第一次操作时,只生成了train的lmdb格式,而val生成失败,添加label之后成功。
再有一个需要注意的地方,添加label时,其后直接换行,不可多打任何字符,尤其是空格。否则会导致某几张图片生成失败。
(2)Check failed: mkdir( ) ......... mkdir train_fire_lmdb.....
出现该问题,是因为一旦运行create_fire.sh文件,便会产生该文件夹,再次运行时便会提示此错误。只需在对应路径下删除该文件夹,重新运行.sh文件即可。
以上,便是本人初步尝试用caffe框架训练自己的数据过程中,一些自己的心得。在此致谢一些博客的帮助。
(1) Caffe︱构建lmdb数据集、binaryproto均值文件及各类难辨的文件路径名设置细解
(2)深度学习(十三)caffe之训练数据格式
(3)Caffe下自己的数据训练和测试
(4)CAFFE学习笔记(四)将自己的jpg数据转成lmdb格式