ORACLE执行计划
PLSQL执行计划F5
一、Description 缩进判断:缩进最多执行 缩进相同的最上边先执行 通过箭头查看执行的顺序
二、其中 TABLE ACCESS FULL是一种执行表访问的方式
表的访问方式:
1、TABLE ACCESS FULL 全表扫描
这种扫描类型从表中读取所有行,并过滤掉不符合选择条件的行。 在全表扫描期间,扫描处于高水位标记下的表中的所有块。 高水位标记表示已使用空间的数量,或已格式化为接收数据的空间。 检查每一行以确定它是否满足语句的WHERE子句 。当Oracle数据库执行全表扫描时,顺序读取块 。 因为这些块是相邻的,所以数据库可以使I / O调用大于单个块来加快进程。 读取呼叫的大小范围从一个块到由初始化参数DB_FILE_MULTIBLOCK_READ_COUNT指示的块数。 使用多块读取 ,数据库可以非常有效地执行全表扫描。 数据库读取每个块只有一次。
2、TABLE ACCESS BY INDEX ROWID 通过ROWID的表存取
ROWID是由Oracle自动加在表中每一行的伪列,表中并不会物理存储ROWID的值,可以像使用其他列一样使用,但是不能对这个值进行增删改,一旦数据插入后,对应的ROWID在改行的生命周期内是唯一的,即使发生迁移,该行的ROWID不会变。
一行的rowid指定包含该行中的行和该行的位置的数据文件和数据块。 通过指定其rowid来定位行是检索单个行的最快方法 ,因为指定了数据库中行的确切位置。 要通过rowid访问表,Oracle数据库首先从语句的WHERE子句或通过对表的一个或多个索引的索引扫描获取所选行的rowid。 然后,Oracle数据库将根据其rowid在表中定位每个选定的行。
这通常是从索引中检索rowid后的第二步。 索引列以外的其他列需要通过rowid返回表访问。
3、INDEX FULL SCAN 索引扫描
在索引块中 既存储每个索引的键值,也会存储该行的ROWID。首先扫描索引得到对应的ROWID,然后通过ROWID定位到具体的行读取数据。
索引的种类(5):
(1)INDEX UNIQUE SCAN 索引唯一扫描

场景: 【UNIQUE or PRIMARY KEY】
针对唯一性索引(UNIQUE INDEX)的扫描每次至多返回一条记录,oracle实现唯一性扫描。
(2)INDEX RANGE SCAN 索引范围扫描
场景: 【a. 在唯一索引列上使用了范围操作符(<、>、<>、>=、<=、between)

b. 在组合索引上,只使用部分列进行查询(查询时必须包含前导列)

c. 在非唯一索引上进行任何的查询】
使用一个索引存取多行数据
(3)INDEX FULL SCAN 索引全扫描
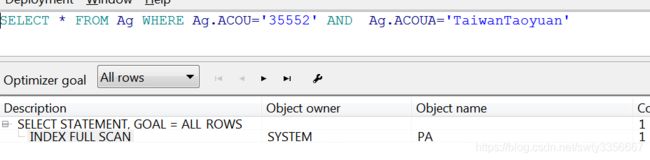
进行全索引扫描时,查询出的数据都必须从索引中可以得到(全索引扫描CBO模式下才生效)
当索引包含查询所需的所有列时,快速全索引扫描可替代全表扫描,并且索引键中 至少有一列具有NOT NULL约束。 快速全索引扫描访问索引本身的数据,而无需访问表 。 数据库无法使用此扫描来消除排序操作,因为数据不是由索引键排序的。 数据库使用多块读来读取整个索引 ,与完整索引扫描不同,可以并行扫描。
快速全索引扫描比正常全索引扫描更快,因为它可以使用多块I/O和并行,就行全表扫描一样。
Oracle中的优化器是SQL分析和执行的优化工具,负责生成+指定SQL的执行计划,有两种优化器:
RBO:基于规则的优化器
CBO:基于代价的优化器:CBO通过计算各种可能的执行计划中的COST,从中选用COST最低的执行方案作为实际运行方案。它依赖数据库对象的统计信息,统计信息的准确与否影响CBO作出最优的选择,对数据敏感。
(4)INDEX FAST FULL SCAN 索引快速扫描
扫描索引中的所有的数据块,与INDEX FULL SCAN类似,但是一个显著的区别是它不对查询出的数据进行排序。
(5)INDEX SKIP SCAN 索引跳跃扫描

前提:表中有一个复合索引,且在查询时有除了前导列(索引中第一列)外的其他列作为条件,并且优化器为CBO
过程:当oracle发现前导列的唯一值个数很少时,会将每个唯一值都作为常规扫描的入口,在此基础上做一次查找,最后合并这些查询。
有时候复合索引的前导列(索引包含的第一列)没有在查询语句中出现,oracle也会使用复合索引,此时使用INDEX SKIP SCAN。
例如:clear.tc_home_inquire_match建立了索引如下:
![]()
因为fn_flalg只有 '1' 和 '2 两个值,所以为了提高索引的利用率,Oracle可将这个复合索引拆成 ('1', trade_date, seq_no),('2', trade_date, seq_no) 这两个复合索引;
Oracle先进入fn_flag为'1'的入口,这时候使用到了 ('1', trade_date, seq_no) 这条复合索引,查找 seq = '1';
再进入fn_flag为'2'的入口,这时候使用到了 ('2', trade_date, seq_no) 这条复合索引,查找 seq = '1';
最后合并查询到的来自两个入口的结果集。
【为什么又是全表扫描比索引扫描快】因为逻辑读物理读 单位是 次块 (一次IO读取相同或不同块数情况下,看读取了多少次),数据总块数一样的情况下,多块读的话,读取次数就少,逻辑读或物理读就少了,而全表扫描就是多块读。而 一次IO的开启和结束是要消耗操作系统很多资源的 。
多块读的场景
Full Table Scan --全表扫描
Index Fast Full Scans --索引快速全扫描
单块读的场景
Rowid Scans --直接通过Rowid获取
Index Unique Scans --索引唯一扫描
Index Range Scans --索引局部扫描
Index Skip Scans --索引跳跃扫描
Index Full Scans --索引全扫描
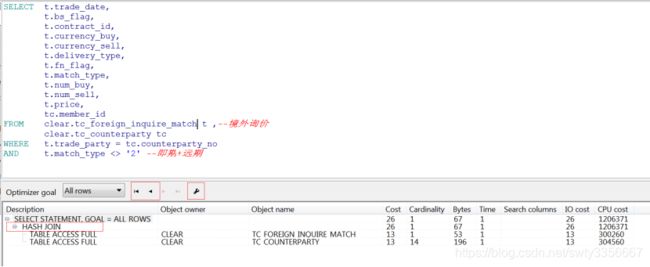
三、HASH JOIN是一种表连接方式
JOIN操作的各步骤一般是串行的(在读取做连接的两张表的数据时可以并行读取)
驱动表(Driving Table):表连接时首先存取的表,又称外层表(Outer Table),这个概念用于 NESTED LOOPS(嵌套循环) 与 HASH JOIN(哈希连接)中;如果驱动表返回较多的行数据,则对所有的后续操作有负面影响,故一般选择小表(应用Where限制条件后返回较少行数的表)作为驱动表。
匹配表(Probed Table):又称为内层表(Inner Table),从驱动表获取一行具体数据后,会到该表中寻找符合连接条件的行。故该表一般为大表(应用Where限制条件后返回较多行数的表)。
四种表连接方式:row source 1 先存取的表 row source 2 后连接的表
1、SORT MERGE JOIN(排序-合并连接)
select a.name,b.name from A a join B on(a.id = b.id)
首先按照a.id作为关联列进行排序生成resource1,
然后按照b.id作为关联列进行排序生成resource2,
两边已排序的行放在一起执行合并操作(对两边的数据进行扫描并判断是否连接)
排序-合并连接适用的连接条件有: < <= = > >= ,不适用的连接条件有: <> like
2、NESTED LOOPS(嵌套循环)
首先先取驱动表的每一行,遍历匹配表所有行并且检查是否有匹配的,取出匹配的放入结果集中
如果驱动表中返回了N行数据,则匹配表会相应的全表遍历N次,所以驱动表返回行数尽可能少(where)并且能高效访问匹配表(建立索引)时,效率较高。
3、HASH JOIN (哈希连接)
哈希连接只适用于等值连接(连接条件=)
取驱动表中的数据集,然后将其构建成内存中的一个哈希表,创建哈希位图
取匹配表中的数据集,对其中的每一条数据的连接操作关联列使用相同的hash函数找到对应的数据位置,在该位置上检查是否找到匹配的数据