洛谷 P1140 dp
https://www.luogu.org/problemnew/show/P1140
题目背景
大家都知道,基因可以看作一个碱基对序列。它包含了4种核苷酸,简记作A,C,G,T。生物学家正致力于寻找人类基因的功能,以利用于诊断疾病和发明药物。
在一个人类基因工作组的任务中,生物学家研究的是:两个基因的相似程度。因为这个研究对疾病的治疗有着非同寻常的作用。
题目描述
两个基因的相似度的计算方法如下:
对于两个已知基因,例如AGTGATG和GTTAG,将它们的碱基互相对应。当然,中间可以加入一些空碱基-,例如:

这样,两个基因之间的相似度就可以用碱基之间相似度的总和来描述,碱基之间的相似度如下表所示:

那么相似度就是:(−3)+5+5+(−2)+(−3)+5+(−3)+5=9。因为两个基因的对应方法不唯一,例如又有:
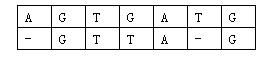
相似度为:(−3)+5+5+(−2)+5+(−1)+5=14。规定两个基因的相似度为所有对应方法中,相似度最大的那个。
输入输出格式
输入格式:
共两行。每行首先是一个整数,表示基因的长度;隔一个空格后是一个基因序列,序列中只含A,C,G,T四个字母。1≤1 \le 1≤序列的长度≤100。
输出格式:
仅一行,即输入基因的相似度。
输入输出样例
输入样例#1: 复制
7 AGTGATG
5 GTTAG输出样例#1: 复制
1思路:dp,用dp[i][j]表示第一个字符串前i个与第二个字符串前j个匹配所能达到的最大匹配值。那么有三种情况:(1)j与空碱基配对,dp[i][j]=dp[i][j-1]+(空碱基与s2[j]配对的值);(2)i与空碱基配对,dp[i][j]=dp[i-1][j]+(s1[i]与空碱基配对的值);(3)s1[i]与s2[j]配对,dp[i][j]=dp[i-1][j-1]+(s1[i]与s2[j]配对的值)。取三种情况最大的即可。
#include
using namespace std;
int t[6][6]=
{
{0,0,0,0,0,0},
{0,5,-1,-2,-1,-3},
{0,-1,5,-3,-2,-4},
{0,-2,-3,5,-2,-2},
{0,-1,-2,-2,5,-1},
{0,-3,-4,-2,-1,0}
};
int a[105],b[105];
int dp[105][105]; //dp[i][j] s1前i个字符与s2前j个字符匹配对应的值
int zh(char ch);
int main()
{
string s1,s2;
int n1,n2;
cin>>n1>>s1>>n2>>s2;
for(int i=0;i