JVM垃圾回收与调优
首先,第一个问题:什么是垃圾?
我们说当一个对象,没有任何引用指向它的时候,那这个对象就是垃圾。
那么JVM是怎么知道这个对象已经没有引用指向它了呢?也就是说JVM是怎么找到垃圾的?
目前来说有两种算法:reference count(引用计数)、Root Searching(根可达)
reference count(引用计数)
在对象的头信息中记了一个数,每当有一个引用指向了这个对象,就加1。引用失效时,就减1。当计数值为0的时候,说明这个对象变成了垃圾,需要被回收。
但是引用计数这种方式不能解决循环引用的问题

这里有A、B、C三个对象循环引用,导致他们的引用计数无法为0,所以不能被回收。
Root Searching(根可达)
从gcroot(根对象)不断往下搜索,凡是能找到的都是有用的对象,找不到的就是垃圾。
哪些对象可作为GCroot?JVM stacks,native method stack,run-time constant pool,static references in method area,Clazz
我们可以简单理解为main方法中可以访问到的对象可作为根对象。
垃圾回收算法
找到垃圾后,有3种算法可以用于清理垃圾:Mark-Sweep(标记清除)、copying(拷贝)、Mark-Compact(标记压缩)
- Mark-Sweep(标记清除)

先标记出需要回收的对象,标记完成后再回收所有被标记的对象。这种算法的缺陷在于容易产生大量不连续的内存碎片。在分配较大对象的时候,无法找到足够·大的连续内存。同时标记和清除的效率也不高。
- copying(拷贝)

copying就是把内存一分为二,每次只使用其中一块,垃圾回收时,只需找到还存活的对象,将它们复制到另一块内存中,再将已使用的这一整块内存直接清理掉。这种算法效率比较高,但缺点是浪费空间。
- Mark-Compact(标记压缩)

类似于硬盘整理碎片,将存活对象都压缩到最前端,清理掉边界外碎片。这种算法效率很低。
内存分区分代模型

整个内存分为年轻代和老年代两部分,默认情况下年轻代和老年代是按照1:2的比例划分,而年轻代中又按照 8:1:1分成三部分:eden、survivor1,survivor2。一般来说,年轻代发生的GC比较多,老年代中GC相对比较少。年轻代中采用的copying(拷贝)算法,效率非常高,老年代中一般使用Mark-Compact(标记压缩)和 Mark-Sweep(标记清除)算法。
分代回收流程

一个对象从出生到消亡会经过一系列的过程:
一个对象刚new出来的时候,优先在栈上分配。不是在堆上分配吗?不是这样的,我们的hospot虚拟机在执行的时候,会先尝试在栈上分配,栈上分配的优点在于不需要垃圾回收器的介入。每个方法对应的有个栈帧,方法执行完毕,从对应的栈帧弹出去后,分配在栈上的对象,就消失了。不过栈上分配有局限性,符合特定条件才可以。
如果无法在栈上分配,那就要看它是否为大对象,如果特别大,直接进入老年代。如果不够大,说明它适合放入Eden中,那么在Eden中会进行线程本地分配,叫TLAB(ThreadLocalAllocationBuffer)。想象一个场景,有很多线程同时往Eden中分配对象,那这个时候肯定是需要做线程同步的,以控制多个线程争抢同一块内存。所以这个时候效率会偏低一些。所以在hospot虚拟机中新增了ThreadLocalAllocationBuffer的机制。在Eden中给每个线程分配了一块属于自己的内存区域。对象产生的时候优先往自己专属的区域分配。不管是否符合线程本地分配,最终都是分配在Eden中。
YGC/MinorGC
eden中的对象,经过一次垃圾回收后,幸存对象到达survivor1。伊甸区采用copying的垃圾回收算法,将经过一次垃圾回收后还存活的对象copy到survivor1。
要知道,新生代可是按照 8:1:1的比例来分配的,eden占了8份,survivor1占1份,那要是survivor1装不下该怎么办?首先我们需要知道一点,就是eden中的都是很容易被回收的对象,所以eden中的绝大部分对象经过一次回收都能够回收掉,存活的比较少。如果幸存对象实在太多,survivor1放不下,那就直接进入老年代中。
survivor1中的幸存对象,又经过一次垃圾回收后,将幸存对象copy到survivor2,清空survivor1。下一次垃圾回收的时候,将幸存对象copy到survivor1中,清空survivor2。如此往复切换, 一直经历到一定年龄(n次垃圾回收,参数n可设置,最大为15)后,还没被回收掉,进入到老年代。
MajorGC/FullGC
老年代中的垃圾越来越多,老年代中都快装不下了,需要再次垃圾回收,这个时候会触发FullGC。
垃圾回收器
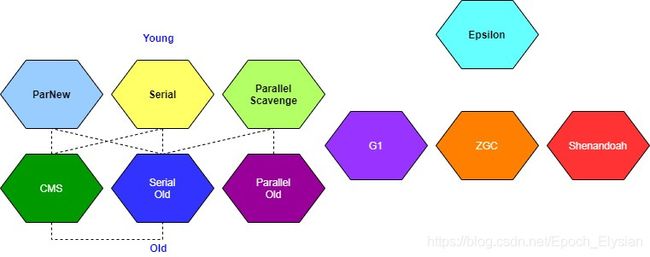
随着内存大小的不断增加,stop the world (STW)消耗的时间太长,为了解决这些问题, 产生了一系列的垃圾回收器。垃圾回收器有分代模式和非分代模型,左边的ParNew、Serial、ParallelScavenge、CMS、SerialOld、ParallelOld 这6个是属于分代模型,G1是逻辑分代,物理上不分代。ZGC和Shenandoah这两个不分代。Epsilon这个垃圾回收器用作调试,JDK11后才有。
图中虚线代表垃圾回收器之间可以互相搭配,常见的垃圾回收器的搭配:
1.Serial+Serial Old(Serial年轻代和Serial老年代)
- Serial:a stop-the-world,copying collector which uses a single GC thread (年轻代copying算法,老年代标记压缩算法)
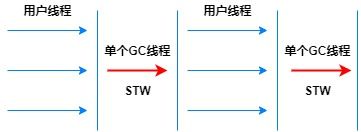
这个垃圾回收器是单线程的年轻代加上单线程的老年代,执行垃圾回收的时候,必须暂停其它所有的工作线程(Stop the world)。单cpu效率最高,虚拟机是Client模式时的默认垃圾回收器
2.ParallelScavenge+Parallel Old
- Parallel Scavenge:a stop-the-world,copying collector which uses mutiple GC threads (年轻代中多线程copying算法)
- Parallel Old:a compacting collector that uses multiple GC threads (老年代中多线程标记压缩算法)

年轻代和老年代垃圾回收都是多线程,吞吐量高。
3.ParNew+CMS(concurrent mark sweep)
- CMS:concurrent mark sweep , a mostly concurrent, low-pause collector.
- phases
- initial mark
- concurrent mark
- remark
- concurrent sweep

- 初始标记:暂停用户线程(STW),找到最根上的垃圾,仅标记GCroots能直接关联到的对象,速度很快
- 并发标记:用户线程和垃圾回收线程同时运行,用户线程产生垃圾的同时,垃圾回收线程一直在并发标记,
- 重新标记:暂停用户线程(STW),为了防止上一步并发标记过程中出现的错误,采用多线程重新标记。
- 并发清除:用户线程和工作线程同时运行,使用标记清除算法对标记区域进行回收。
CMS垃圾回收器有一个重大的问题就是容易产生大量的内存碎片。
- ParNew:工作流程上和ParallelScavenge一样,专门用来配合CMS的
ParNew+CMS组合就是新生代使用ParNew,老年代使用CMS
4.G1垃圾回收器
为了解决传统垃圾回收器在大内存下,STW时间过长的问题,出现了G1(Garbage-First)这个垃圾回收器。

大内存下,传统分代模型的垃圾回收器STW时间非常长。G1中对物理内存模型进行了修改,将内存划分成N个小块。而G1从逻辑上来讲是分代的,我们可以认为它的某一小块内存是属于年轻代或老年代,或者是Survivor亦或是大对象。
所以G1在做垃圾回收的时候,只需要找到对应的那一块内存,然后回收掉就可以了。而且G1能够控制只回收部分内存块。比如说Eden一共有10小块内存,那在回收的时候只回收2块。这样一来,STW的时候就可以大幅度缩减。
G1有些类似于CMS垃圾收集器,垃圾收集线程和用户线程是同时并发执行的。不同的是G1是一个天然的压缩收集器,它将内存划分成了很多个小块(压缩),可以更细粒度的控制垃圾回收,有效避免内存碎片的问题。而且G1意在优先处理更多的垃圾内存块。
G1垃圾回收大致流程:
- 初始化标记:暂停用户线程(STW),找到最根上的垃圾,也就是标记GCroots能直接关联到的对象
- 并发标记:从GCRoot开始查找,进行可达性分析,标记垃圾对象。该过程用户线程和垃圾回收线程并发执行
- 重新标记:暂停用户线程(STW),为了防止上一步并发标记过程中出现的错误,GC线程采用多线程重新标记。
- 筛选回收:在满足用户设定回收停顿时间的前提下,选择部分内存完成最多的垃圾回收,这个过程会产生Stop the world