golang整理
1. 算法基础
冒泡排序(稳定):
冒泡排序实现的过程主要是分为两步,第一步利用一层循环控制数列的冒泡的次数,第二步利用第二层循环控制从第一个数值位置“冒出”的元素数值不断与之后的数值比较之后(也就是冒泡中的数值始终是比较之后的最大值(或最小值))放在合适的位置,也就是逐次将大(小)数,次大(小)数。。。往后放,最终形成一个有序的序列。
选择排序(不稳定):
整个排序过程和插入排序的思想有些相似,默认形成两个子序列,一个有序序列,一个无序序列,不断地从无序列中选择出最大值(或最小值)往有序序列中填充,填充的过程只是简单的在有序序列后面追加,因为有序序列本身就已经满足按照之后最大值(或最小值)选出来的。
插入排序(稳定):
插入排序的思想和选择排序类似,也是分成两个序列,有序序列和无序序列,不同的插入排序是不在无序列中挑选,而是不断直接选取无序序列第一个数值,在有序序列中比较,来确定有序序列中的准确位置。
希尔排序(不稳定):
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止
快速排序(不稳定):
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
步骤为:
1) 从数列中挑出一个元素,称为"基准"(pivot),
2) 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
3) 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去
2. sql
mqsql优化:
1) 避免使用星号 * ,用具体字段替代(使用星号会在查询时增加一个查询列的操作)
2) where尽量加索引, 尽量避免在 where 子句中对字段进行 null 值判断,最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库 (不然会进行全表扫描,影响效率)
-反例:select id from t where num is null
-可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num = 0
3) 应尽量避免在 where 子句中使用 != 或 <> ,in 或 not in 操作符 (同上)
4) 能用between就不要使用in,或者用exists替换in
-select num from a where num in(select num from b)
用下面的语句替换:select num from a where exists(select 1 from b where num=a.num)
5) 尽可能的使用 varchar/nvarchar 代替 char/nchar (节省字段存储空间)
6) 加一个explain(分析), 可以分析当前的查询, 用它来判断是否需要使用索引
7) 怎么加索引: 建表的时候加索引, add index(xxx某个需要索引的名称)
MongoDB是一个由C++编写的高性能的文档型数据库,为web应用提供可扩展数据库解决方案。它和MySQL的区别如下:
| 项目 | MongoDB | MySQL |
|---|---|---|
| 存储单元 | 按collection存储,一个collection中包含很多document | 按table存储,一个table中包含很多的记录 |
| 数据格式要求 | 非常灵活,document可以存储任意json格式的数据 | row中的每一列的数据类型都是限定死的,不够灵活 |
| 数据字段扩展 | 对数据字段的扩展零消耗 | 数据扩展字段有很大的消耗。比如:上万条数据再增加一列就要消耗几十秒。 |
| 事务支持 | 在4.0之后版本支持,目前已经支持 | 支持 |
| 读写性能 | 一般情况下,读写性能都要略高于MySQL | 性能平稳 |
| CRUD | MongoDB | MySQL |
|---|---|---|
| C | db.[documentName].insert({…}); | insert into 表名[列名1,列名2...]values(值1,值2...); |
| R | db.[documentName].remove({...}); | delete from 表名 [where 条件]; |
| U | db.[documentName].update({查询器},{修改器}); | update 表名 set 字段名1=值,字段名2=值 [where 条件]; |
| D | db.[documentName].find(); | select distinct[列名1,列名2...]from 表名 [where 条件] |
mongodb: (1)面向文档(2)高性能(3)高可用(4)易扩展(5)丰富的查询语言 --------------------- 本文来自 shehun1 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/shehun1/article/details/21240731?utm_source=copy
3. goroutine和锁
go协程学习一: https://blog.csdn.net/kjfcpua/article/details/18265441
go协程学习二:https://blog.csdn.net/kjfcpua/article/details/18265461
go协程学习三:https://blog.csdn.net/kjfcpua/article/details/18265475
4. http、tcp/udp、socket网络编程
socket: 就是网络编程, 里面做好了一套网络接口, 是一个封装好的模型(文件描述符, 文件操作)
Socket就是封装了” 打开open –> 读写write/read –> 关闭close”等模式的一个类似于管道的一种文件描述符; Socket类型主要有两种方法, 一种是TCP端口协议(安全, 速度慢, 比如说用于电话传输, 平时用的最多的也是TCP) ,另一种是UDP端口协议(安全度低, 速度很快, 比如说用于发短信等操作)
网络分层架构:
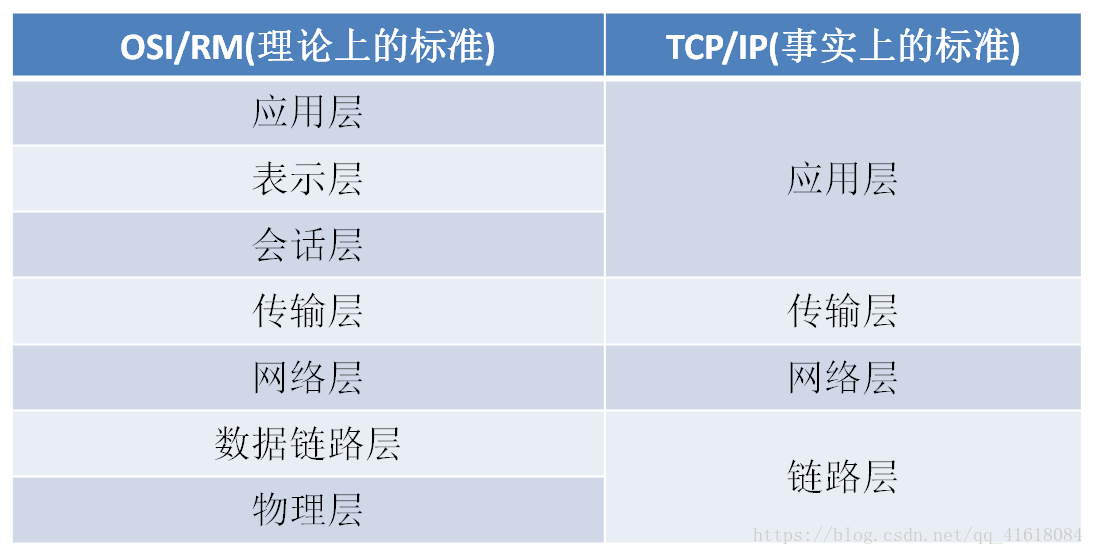
越下面的层,越靠近硬件;越上面的层,越靠近用户。至于每一层叫什么名字,其实并不重要(面试的时候,面试官可能会问每一层的名字)。只需要知道,互联网分成若干层即可。
网络的每一层,都定义了很多协议。这些协议的总称,叫“TCP/IP协议”。TCP/IP协议是一个大家族,不仅仅只有TCP和IP协议,它还包括其它的协议,如下图:

5. nginx
https://blog.csdn.net/kisscatforever/article/details/73129270#t2
1、 http服务器。Nginx是一个http服务可以独立提供http服务。可以做网页静态服务器。
2、 虚拟主机。可以实现在一台服务器虚拟出多个网站。例如个人网站使用的虚拟主机。 基于端口的,不同的端口 基于域名的,不同域名
3、 反向代理,负载均衡。当网站的访问量达到一定程度后,单台服务器不能满足用户的请求时,需要用多台服务器集群可以使用nginx做反向代理。并且多台服务器可以平均分担负载,不会因为某台服务器负载高宕机而某台服务器闲置的情况。 --------------------- 本文来自 AresCarry-王雷 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/kisscatforever/article/details/73129270?utm_source=copy
总结: http服务器,虚拟主机,反向代理,负载均衡
6. 总结面试中经常考的mysql面试问题
https://blog.csdn.net/ligupeng7929/article/details/79421205
面试技巧,如何通过索引说数据库优化能力,内容来自Java web轻量级开发面试教程:
https://www.cnblogs.com/JavaArchitect/p/7465715.html
7. 面试中碰到的问题
https://www.cnblogs.com/junwangzhe/p/7224256.html
面试中被问到:你在工作中碰到的最困难的问题是什么?
https://blog.csdn.net/u012423865/article/details/7945271
8. 什么是RESTful API?
https://blog.csdn.net/hjc1984117/article/details/77334616
9. redis常见面试题
https://www.cnblogs.com/Survivalist/p/8119891.html
redis在项目中的实战
https://blog.csdn.net/u010539352/article/details/51787324
使用redis作为mysql的缓存
https://blog.csdn.net/gx_1983/article/details/79033502
网站或接口响应时间较长应该如何排查
https://www.cnblogs.com/111testing/p/7119113.html
深入理解Redis:底层数据结构
https://blog.csdn.net/hanhuili/article/details/17710781
10. linux常用命令
切换目录:
和windows 基本一样
cd .. 回到上一级目录
cd xxx 进去子级目录, 如果是 cd usr 就表示进去 当前的子级usr目录
cd / 表示回到根目录 , cd ~ 表示进入root目录
显示文件夹内容:
ls 普通显示文件夹内容。只显示名称,没有其他信息
ls -l 显示的内容更加详细, 有时间、 大小...
ls -a 显示所有内容, 包含 . 文件
ls -al 和前面两个组合起来,就是显示所有文件,并且详细的显示
ll 其实就是 ls -l 的简写
操作目录:
-
添加目录
mkdir xxx 生成目录 xxx 如: mkdir heima26
-
修改目录名称
mv aa bb 修改文件夹名称, 把aa这个名字改成 bb
-
删除目录
rm -r xxx 删除这个目录,但是会询问是否删除
rm -rf xxx 删除这个目录,即便里面有子目录也删除,并且不会询问。
-r : 对应删除目录
-f : 强制删除
如果要删除的东西是一个目录,必须要带上 -r , 否则无法删除操作文件:
-
添加文件
touch aa.txt : 生成一个文件 aa.txt
当然生成文件也还可以用另外一个命令 , vi | vim 如:vi bb.txt , 但是这两个命令,更多的是用来编辑文件内容的。
-
删除文件
其实不用记太多,就记得它和删除文件夹是一样的命令即可。
rm -rf aa.txt : 强制删除 aa.txt
-
查看文件内容
cat aa.txt : 一次性显示所有内容
more aa.txt : 分页显示内容
回车就是看下一行
空格是看下一页
B 看上一页
如果不想看了。 点击q 退出查看less -mN aa.txt : 分页显示内容 ,和上面的more 有点区别就是 多了行号 (有点像是more的升级版)
tail aa.txt 只查看文件的末尾内容,适合查看日志文件
-
查找有没有该文件
find -name aa.txt : 在当前目录中查找是否有该aa.txt文件
-
拷贝文件
cp aa.txt doc : 拷贝aa.txt 到当前的子目录 doc里面去
cp aa.txt /usr/local/heima : 拷贝当前这个文件到 /usr/local/heima
-
剪切文件
mv aa.txt doc : 剪切,其实就是移动文件到doc目录去。
-
修改文件名
和以前一样 mv aa.txt bb.txt
压缩:
tar 用来压缩和解压缩
linux系统里面打包和压缩是分开来说的。以前windows说的打包(集中到一个文件,并且压缩)linux下面是分开来的,打包是打包,压缩是压缩
tar -cvf 打包后的名字 被打包的文件...
如: tar -cvf aa.tar aa.txt bb.txt : 把aa.txt 和 bb.txt 打包成一个文件 , 文件名叫做 aa.tar
linux下面的打包后缀一般都叫做 tar 如果想打包并且压缩,那么使用下面的命令
tar -zcvf 打包后的名字 被打包的文件...
如: tar -zcvf aa.tar.gz aa.txt bb.txt : 把aa.txt 和 bb.txt 打包且压缩成一个文件 ,文件名字叫做aa.tar.gz 。 以后看到文件的后缀是.tar.gz 就知道这个文件一般是给linux系统使用的压缩文件。 参数解释:
z : gzip 代表使用gzip压缩算法
c : create 生成文件
v : verbose 显示详情,表示哪个文件被打包了
f : file 指定被打包的文件解压缩:
tar -zxvf aa.tar.gz : 解压这个压缩包的内容到当前目录
tar -zxvf aa.tar.gz -C /usr/local/heima27 : 解压这个文件到 /usr/local/heima27 文件夹里面注意,这是大写的 -C
参数解释:
x : extract 解压缩的意思
C : Change Directory 改变解压缩的目录
输入 vi | vim aa.txt
进入文件内容,目前处于一般模式,不允许编辑
点击 i | a | o
一般都是点击i (insert) ,现在处于编辑模式 ,可以写东西了。
写完之后,想退出。
先点击esc 键盘上的左上角那个键位, 现在变成了一般模式
变到底行模式退出
输入 : wq 保存切退出 w ---就是 write写入的意思
输入 :q! 不保存,强制退出
权限命令:
linux系统对文件的访问都有明确的权限控制。如:
-rwxrw-r-- aa.txt
第一个- 表示文件
rw- 当前用户的操作权限
r-- 同组用户的操作权限
r-- 其他组的用户操作权限
这其实表示当前用户对aa.txt具有可读可写可执行前悬, 同组的其他用户具有读写权限
其他组的用户具有只读权限
权限可以修改的。
chmod u=rwx,g=rwx,o=rwx aa.txt 修改aa.txt 的权限为 当前用户,同组用户,其他组用户 ,都具有可读可写可执行权限。 chmod 其实是 change mode 的缩写
-rwx rwx rwx . 其实是能够对应二进制的 111, 转换成十进制的话是 421 421 421 刚好是777
chmod 777 等同于上面的命令11. 学会docker看这一篇文章就够了
https://segmentfault.com/a/1190000009544565
12. 为什么golang还需要调度器呢
https://studygolang.com/articles/9610
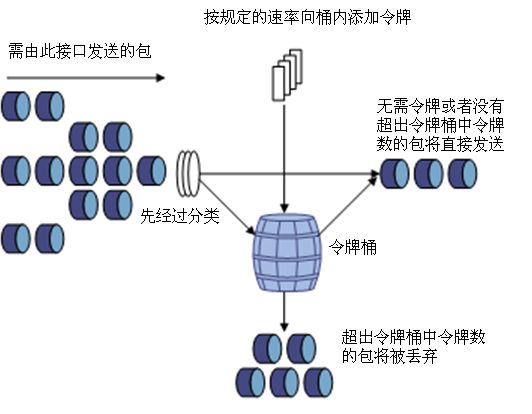
13. 什么是token bucket算法
https://www.jianshu.com/p/356c4d2aef6d
当桶里面没有令牌时,可能的处理方式:
1. 直接丢掉
2. 入队等待,知道令牌足够
3. 可能直接处理,但是被标记为没有令牌携带的packet,当网络过载时可能被丢
如果有攻击者, 或者用户有意无意的像你的网站发起请求, 当请求达到一定数量时候, 会导致连接数不够, 或者更严重的把你的带宽占完, 那你系统就会出现一些问题
那么bucket: 箱子, 里面可以装很多的token, 使用token bucket让我们的项目有一个留空的功能, 防止恶意攻击导致我们的系统出现问题

14. mysql和redis的区别
https://www.2cto.com/database/201802/723877.html
mysql和redis保持数据一致
https://blog.csdn.net/thousa_ho/article/details/78900563
大数据量大并发下mysql瓶颈和nosql简绍
https://www.cnblogs.com/shuaiandjun/p/5648334.html
MySQL、Redis、MongoDB对比
https://blog.csdn.net/szm1234560/article/details/78991577
mongodb:
它是一个内存数据库,数据都是放在内存里面的。
对数据的操作大部分都在内存中,但mongodb并不是单纯的内存数据库。
持久化方式:
mongodb的所有数据实际上是存放在硬盘的,所有要操作的数据通过mmap的方式映射到内存某个区域内。
然后,mongodb就在这块区域里面进行数据修改,避免了零碎的硬盘操作。
至于mmap上的内容flush到硬盘就是操作系统的事情了,所以,如果,mongodb在内存中修改了数据后,mmap数据flush到硬盘之前,系统宕机了,数据就会丢失。
mmap详解链接:http://www.cnblogs.com/techdoc/archive/2010/12/22/1913521.html
redis:
它就是一个不折不扣的内存数据库了。
持久化方式:
redis所有数据都是放在内存中的,持久化是使用RDB方式或者aof方式。
解密redis持久化:http://blog.nosqlfan.com/html/3813.html
mysql:
无论数据还是索引都存放在硬盘中。到要使用的时候才交换到内存中。能够处理远超过内存总量的数据。
数据量和性能:
当物理内存够用的时候,redis>mongodb>mysql
当物理内存不够用的时候,redis和mongodb都会使用虚拟内存。
实际上如果redis要开始虚拟内存,那很明显要么加内存条,要么你换个数据库了。
但是,mongodb不一样,只要,业务上能保证,冷热数据的读写比,使得热数据在物理内存中,mmap的交换较少。
mongodb还是能够保证性能。有人使用mongodb存储了上T的数据。
mysql,mysql根本就不需要担心数据量跟内存下的关系。不过,内存的量跟热数据的关系会极大地影响性能表现。
当物理内存和虚拟内存都不够用的时候,估计除了mysql你没什么好选择了。
其实,从数据存储原理来看,我更倾向于将mongodb归类为硬盘数据库,但是使用了mmap作为加速的手段而已。
15. tcp三次握手和四次握手
https://mp.weixin.qq.com/s/S1mv8AE_pQz3uHjRGS7tWg
当然是烂熟于胸的回答,一般面试官是男的,反正我没遇到过女的,电话面试的场景就是三次握手的场景.
面试官:Hi,我是某公司面试官,你能听到我说话么?
阁下:你很激动,并回答能听到,反问面试官听到你说话么?
面试官:能听到的,那么咱们开始吧,你能描述下TCP连接关闭的过程么?
阁下:还好我刚才在知乎问过,要不然又凉了,你举挂电话依依不舍的场景.
面试官:聊的差不多了,我准备挂电话了
阁下:好的,和您聊的挺愉快的,你挂吧
面试官:me too,吧唧,挂了
阁下:听到滴滴滴的声音,确认面试官真的挂了,大概回味了2分钟才把电话撂下.
聊天对应的状态和TCP抓包自己去实践和体会,师父领进门,修行在个人.
作者:Sodo
链接:https://www.zhihu.com/question/271701044/answer/363011103
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
16. go的异常处理机制panic
在通常情况下,向程序使用方报告错误状态的方式可以是返回一个额外的error类型值。
但是,当遇到不可恢复的错误状态的时候,如数组访问越界、空指针引用等,这些运行时错误会引起painc异常。这时,上述错误处理方式显然就不适合了。反过来讲,在一般情况下,我们不应通过调用panic函数来报告普通的错误,而应该只把它作为报告致命错误的一种方式。当某些不应该发生的场景发生时,我们就应该调用panic。