深度学习 分类问题与回归问题
分类问题与回归问题
- 分类与回归
- 一、分类问题
- 1.1分类性能度量:
- (1)准确率(accuracy)
- *(2)精确率(percision)
- *(3)召回率(recall)/灵敏度(sensitivity)
- (4)P-R曲线
- P-R曲线的绘制
- (5)F值
- (6)ROC曲线
- 绘制ROC曲线
- AUC(area under curve)
- 1.2 分类性能可视化
- (1)混淆矩阵(Confusion matrix)
- (2)分类报告(Classification report)
- 二、回归问题
- 回归性能度量方法(regression metrics)
- (1)平均绝对误差MAE(mean absolute error)
- (2)均方误差MSE(mean_squared_error)及均方根差RMS
- (3)逻辑回归损失 / 称交叉熵loss(cross-entropy loss)
- 回归评价中每个样本的真实标签true label(或叫ground truth地面真值结果)如何获得?
分类与回归
分类预测建模问题与回归预测建模问题不同。
- 分类是预测离散类标签的任务。
- 回归是预测连续类数量的任务。
分类和回归算法之间存在一些重叠, 例如:
- 分类算法可以预测连续值,但是连续值是类标签的概率的形式。
- 回归算法可以预测离散值,但是以整数量的形式预测离散值。
一些算法可用于分类和回归,只需很少的修改,例如决策树和人工神经网络。一些算法不能或不能容易地用于两种问题类型,例如用于回归预测建模的线性回归和用于分类预测建模的逻辑回归。
重要的是,我们评估分类和回归预测的方式各不相同,并且不重叠,例如:
- 可以使用准确度评估分类预测,而回归预测则不能。
- 可以使用均方根误差来评估回归预测,而分类预测则不能。
比如,区分图像中的人是男性还是女性的问题就是分类问题。根据一个人的图像预测这个人的体重的问题就是回归问题(类似“57.4kg”这样的预测)。

一、分类问题
分类问题是有监督学习的一个核心问题。
分类用于解决要预测样本属于哪个或者哪些预定义的类别。此时输出变量通常取有限个离散值。
分类的机器学习的两大阶段:
(1)从训练数据中学习得到一个分类决策函数或分类模型,成为分类器(classifier);
(2)利用学习得到的分类器对新的输入样本进行类别预测。
多类分类问题可转化为两类分类问题解决,如采用一对其余(One-vs-Rest)方法:将其中一个类标记为正类,将其余类标记为负类。
1.1分类性能度量:
假设只有两类样本,即正例(positive)和负例(negetive)。
 真正(True Positive , TP):被模型预测为正的正样本。
真正(True Positive , TP):被模型预测为正的正样本。
假正(False Positive , FP):被模型预测为正的负样本。
假负(False Negative , FN):被模型预测为负的正样本。
真负(True Negative , TN):被模型预测为负的负样本。
(1)准确率(accuracy)
分类器正确分类的样本数与总样本数之比。
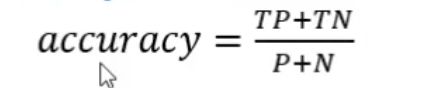
*(2)精确率(percision)
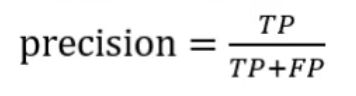
精确率和召回率是二类分类问题常用的评价指标。
精确率反映了模型判断的正例中真正正例的比重。
在垃圾分类中,是指预测出的垃圾短信中真正垃圾短信的比例。
*(3)召回率(recall)/灵敏度(sensitivity)

召回率反映了总正例中被模型正确判定为正例的比重。
医学领域也叫做灵敏度。在垃圾短信分类器中,指所有真的垃圾短信被分类器正确找出来的比例。
(4)P-R曲线
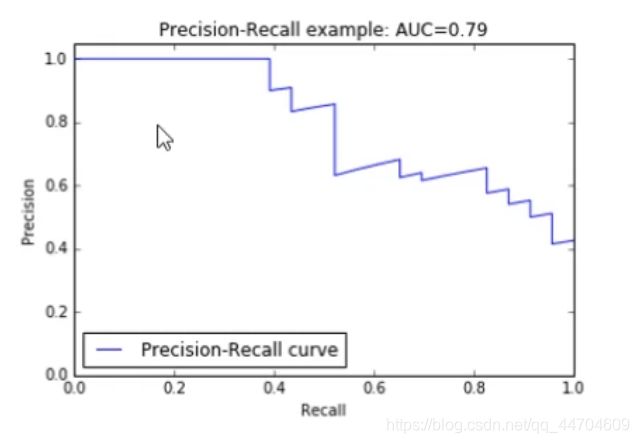 由图可见,如果提高召回率,则精确率会受到影响而下降。
由图可见,如果提高召回率,则精确率会受到影响而下降。 如图是多类分类器,每次将一类分为正例,其他两类为负例,则得到蓝绿红三条曲线。而黄色曲线是他们的平均值线。
如图是多类分类器,每次将一类分为正例,其他两类为负例,则得到蓝绿红三条曲线。而黄色曲线是他们的平均值线。
括号中area为曲线下面积。
area有助于弥补P、R的单点值局部性,可以反映全局性能。
P-R曲线的绘制
绘制P-R曲线需要一系列Percision和Recall值,通过阈值获得。分类器给每个测试样本一个“Score”值,表示该样本多大概率上属于正例。
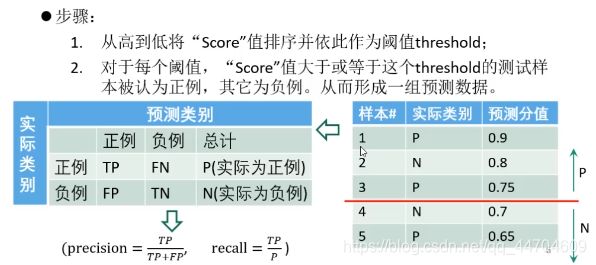 TP与FP的个数会随之增加,因此会形成N个(P,R)点将这些点连起来就形成了P-R曲线。
TP与FP的个数会随之增加,因此会形成N个(P,R)点将这些点连起来就形成了P-R曲线。
(5)F值
F值是精确率和召回率的调和平均值。
 F1值更接近于两个数较小的那个,所以精确率和召回率接近时,F1值大。
F1值更接近于两个数较小的那个,所以精确率和召回率接近时,F1值大。

(6)ROC曲线
ROC曲线全称为“受试者工作特征”(Receiver Operating Characteristic)曲线。描绘了分类器在真正率(TPR)和假正率(FPR)之间的trade-off。
也可理解为:我们根据学习器的预测结果,把阈值从0变到最大,即刚开始是把每个样本作为正例进行预测,随着阈值的增大,学习器预测正样例数越来越少,直到最后没有一个样本是正样例。在这一过程中,每次计算出TP和FP,分别以它们为横、纵坐标作图,就得到了“ROC曲线”。
ROC曲线的纵轴是“真正率”(True Positive Rate, 简称TPR),真正正例占总正例的比例,反映命中概率。横轴是“假正率”(False Positive Rate,简称FPR),错误的正例占负例的比例,反映误诊率、假阳性率、虚惊概率。

绘制ROC曲线
ROC 曲线的画法与P-R曲线相似。
绘制ROC曲线需要一系列FPR值和TPR值,这些系列值是通过阈值形成的。对于每个测试样本,分类器会给一个“Score”值,表示该样本多大概率上属于正例或负例。
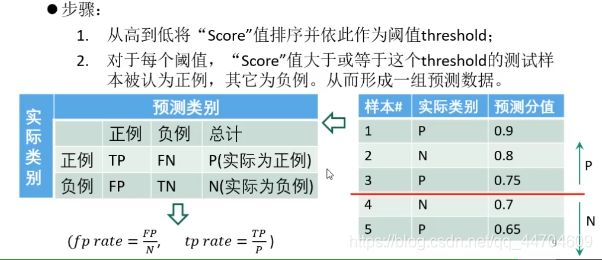 TP与FP的个数会随着样本数的增加而增加,因此形成一个个(FP,TP)点,将点连起来就形成了ROC曲线。
TP与FP的个数会随着样本数的增加而增加,因此形成一个个(FP,TP)点,将点连起来就形成了ROC曲线。

- 对角线对应于“随机猜测”模型,而点(0,1)则对应于将所有正例预测为真正例、所有反例预测为真负例的“理想模型”。
- ROC曲线不适用于多分类问题。
AUC(area under curve)
AUC就是ROC曲线下的面积,即ROC的积分。衡量学习器优劣的一种性能指标。
AUC是衡量二分类模型优劣的一种评价指标,表示预测的正例排在负例前面的概率(反映分类器对样本的排序能力)。
AUC提供了分类器的一个整体数值。通常AUC越大,分类器越好。
AUC的取值范围为[0,1]

1.2 分类性能可视化
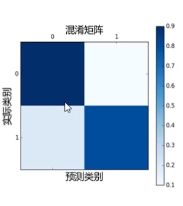
(1)混淆矩阵(Confusion matrix)
如用热力图(heatmap)直观地展现类别的混淆情况(每个类有多少样本被错误地预测成另一个类)
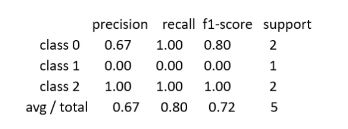
(2)分类报告(Classification report)
显示每个类的分类性能。包括每个类标签的精确率、召回率、F1值等。。
二、回归问题
回归分析(regression analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
回归侧重在定量关系的分析,输出实数数值。而分类的输出通常为若干指定的类别标签。
回归性能度量方法(regression metrics)
- 常用的评价回归问题的方法:
平均绝对误差MAE(mean absolute error)
均方误差MSE(mean squared error)及均方根差RMS
逻辑回归损失或称交叉熵loss(cross-entropy loss)
R方值,确定系数(r2_score)
(1)平均绝对误差MAE(mean absolute error)
MAE :是绝对误差损失(absolute error loss)的期望值。

(2)均方误差MSE(mean_squared_error)及均方根差RMS
MSE:是平方误差损失(squared error loss)的期望值。
NSE的取值越小,预测模型的性能越好。
RMSE是MSE的平方根。


(3)逻辑回归损失 / 称交叉熵loss(cross-entropy loss)
逻辑回归损失简称为Log loss,又称为交叉熵损失。
常用于评论逻辑回归LR和神经网络。

- logistic回归损失(二类)
举例:
 - logistic回归损失(多类)
- logistic回归损失(多类)
对于多类问题,可将样本的真实标签编码成1-of-K(K为类别总数)的二元指示矩阵Y,即每个样本只有其中一个标签值为1,其余K-1都为0。

现将每个样本的真实标签记为[1, 2, 3],此时标签1可转化为[1, 0, 0],标签2转化为[0, 1, 0],标签3转化为[0, 0, 1]。

举例:

回归评价中每个样本的真实标签true label(或叫ground truth地面真值结果)如何获得?
- 人工标注每个样本的标签或回归的目标值
- MAE,PMSE(MSE)常用于评分预测评价
如网站的让用户给物品打分的功能