使用线性回归模型对波士顿数据集进行预测。
1、数据集读入
导入sklearn的自带数据集——boston数据集,分别取出特征向量,以及样本。
2、数据预处理,根据需要进行标准化,归一化处理
查看数据集中的数据,X的数据最小为0.0,最大为711,y的数据最小为5.0,最大为50。数据的跨度较大,因此采用最小最大标准化的规则来把数据归一化到[0,1],以便让代价函数收敛得更快一点。

标准化后的数据:
3、将数据集划分为训练集与测试集
将数据集按照8:2的比例划分为训练集与测试集:

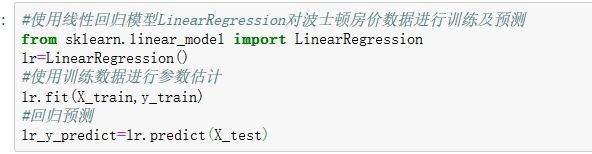
4、利用训练数据构建模型
构建线性回归模型:
其中LinerRegression采用了梯度下降法拟合的线性回归,实现原理是:
假设函数:![]() ,其中,x0=1;
,其中,x0=1;
将所有的参数抽取为一个向量,得到参数向量。当真实值与测试值的平方误差之和最小时,则得到代价函数:
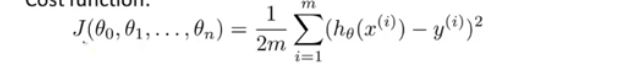
特征x1,x2,……,xn组成一个特征矩阵,而参数向量的倒置与特征矩阵乘积恰好就是假设函数,同步更细参数向量的元素,使得代价函数最小时,就得到与真实曲线拟合度最好的假设函数,使用梯度下降法:
就得到了拟合度最好的一组参数。

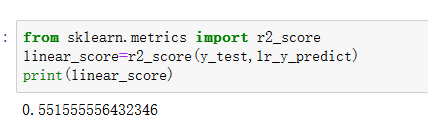
5、用测试数据评价模型的性能
使用r2_score来评价模型的性能,由下图可以看出二者的拟合度为0.55
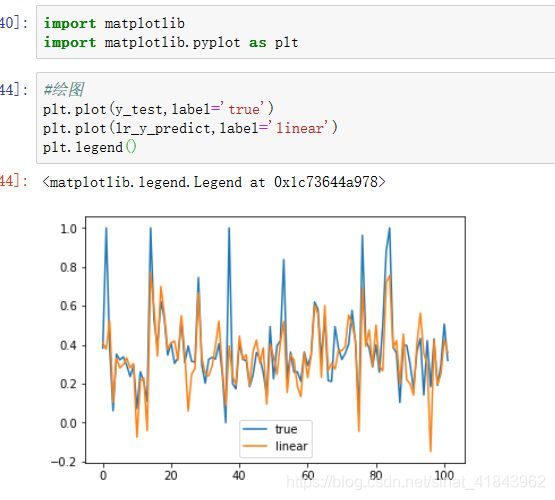
6、结果分析(可视化)
使用matplotlib中pyplot,将测试数据与预测结果画成散点图: