理解进程调度时机跟踪分析进程调度与进程切换的过程
Linux进程调度
进程调度对于一个现代操作系统来说是必不可少的部分,为了表现出多个进程在CPU上同时运行的效果,Linux必须不断的从一个进程快速切换到另一个进程。在进程切换中有三个地方是值得注意的:
一是如何调度,主要包括调度策略的设计,调度策略的作用是为了从运行队列中选择下一个被执行的进程;
二是何时调度,即进程调度的时机选择;
三是怎么切换,即选出来的下一个进程如何上CPU执行。
内核通过sched_class这个结构体将调度策略和进程切换的过程解耦和,可以实现对不同的进程的需求采用不同的调度策略,而不同调度策略会以不同的目标函数来优化调度过程,设置优先级。我们从sched/sched.h中可以看到如下的调度策略。
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;我们这次主要关注后两个问题,即调度时机和切换过程,就不再介绍调度策略本身的内容。但大家在阅读源码的时候如果碰到rt,cfs这样的缩写时,应该想到它们指代的是相应的调度算法。
进程调度的时机
进程调度的时机主要有以下几个:
- 中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
- 内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
- 用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
进程的切换过程
分析切换过程之前,我们来熟悉几个关键的数据结构:
struct rq *rq; //This is the main, per-CPU runqueue data structure.rq(runqueue)是当前CPU上就绪进程所组成的队列,这个结构体记录了每个队列的状态,rq结构体中有cfs_rq和rt_rq两个子结构,分别描述了该CPU上fair类型和rt类型进程的信息。
struct task_struct *prev, *next;task_struct是进程在内核中对应的数据结构,它标识了进程的状态等各项信息。所以这里我们就认为它们是进程本身。
进程切换调用的是schedule()函数,该函数调用了__schedule()。
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
__schedule();
}static void __sched __schedule(void)
{
...
next = pick_next_task(rq, prev);
if (likely(prev != next)) {
...
context_switch(rq, prev, next); /* unlocks the rq */
...
} else {
...
raw_spin_unlock_irq(&rq->lock);
...
}
...
post_schedule(rq);
...
}这个__schedule()函数精简了以后如上所示,我们根据调度策略在运行队列rq中拿出prev进程的下一个进程,如果next进程和prev不是同一个进程,则进行进程的切换并释放自旋锁,否则直接释放自旋锁。
我们来看一下这个函数里的核心函数context_switch,省去一些minor details,将函数精简如下:
context_switch {
...
mm = next->mm;
if(!mm) {
next->active_mm = oldmm;
...
}
else
switch_mm(oldmm, mm, next);
...
switch_to(prev, next, prev);
...
}该函数做了两件事情,第一是切换页表switch_mm,当next进程mm为空(next是内核线程)时,则使用当前进程的页表,否则切换成新进程的页表(用户态地址空间);第二是切换进程switch_to,这是一段汇编函数,也是进程切换的核心代码。我们来看一下这段代码。
#define switch_to(prev, next, last) \
32do {
40 unsigned long ebx, ecx, edx, esi, edi; \
41
42 asm volatile("pushfl\n\t" /*保存当前进程的flag */ \
43 "pushl %%ebp\n\t" /* 保存当前进程EBP */ \
44 "movl %%esp,%[prev_sp]\n\t" /* 保存当前的内核栈顶 */ \
45 "movl %[next_sp],%%esp\n\t" /* 恢复下一个进程的内核栈顶 */ \
//内核堆栈角度,这里已经切换到next的内核堆栈了
46 "movl $1f,%[prev_ip]\n\t" /*将标号1放入当前进程的EIP*/ \
47 "pushl %[next_ip]\n\t" /* 恢复下一个进程的EIP,next内核堆栈的栈顶 */ \
48 __switch_canary \
49 "jmp __switch_to\n" /*寄存器传递参数,jmp不压栈EIP*/ \
//EIP角度,这里是新的进程的执行入口
50 "1:\t" /*switch_to 返回到这里*/ \
51 "popl %%ebp\n\t" /* restore EBP */ \
52 "popfl\n" /* restore flags */ \
53 \
54 /* output parameters */ \
55 : [prev_sp] "=m" (prev->thread.sp), /*字符串标号*/ \
56 [prev_ip] "=m" (prev->thread.ip), \
57 "=a" (last), \
58 \
59 /* clobbered output registers: */ \
60 "=b" (ebx), "=c" (ecx), "=d" (edx), \
61 "=S" (esi), "=D" (edi) \
62 \
63 __switch_canary_oparam \
64 \
65 /* input parameters: */ \
66 : [next_sp] "m" (next->thread.sp), \
67 [next_ip] "m" (next->thread.ip), \
68 \
69 /* regparm parameters for __switch_to(): */ \
70 [prev] "a" (prev), \
71 [next] "d" (next) \
72 \
73 __switch_canary_iparam \
74 \
75 : /* reloaded segment registers */ \
76 "memory"); \
77} while (0)我们分析下这段代码:
先看当前进程(prev):首先保存当前进程的flags,push ebp,然后把EIP置为标号1,等到当前进程(prev)下一次再开始执行时(被__switch_to切出来),内核堆栈被恢复了以后,刚好会从pop ebp开始执行(和前面的push ebp相对应),即恢复原来的堆栈状态。
再看下一个进程(next): 这个进程即将上CPU,是被jmp __switch_to 切换出来的进程,由于这里使用的是jmp指令而不是call指令,之前又手工压栈了EIP,所以__switch_to会返回到next_ip的地方开始执行,这样就完成了进程的切换过程。
如果只有两个进程的话,那么下一次prev就变成了next,next变成prev,大家可以对照上面再理解一下。
总结一下进程切换的调用过程:schedule -> __schedule -> context_switch -> switch_to -> __switch_to
GDB调试
我们既然知道了用户态进程调度时机在中断处理的过程中,那么我们这次实验就可以选取一次中断过程来进行分析。由于之前我们做过系统调用的实验,在那个实验中我们发现在系统调用返回时,是有一次进程调度的操作的,我们可以继续那次实验进行深入。
在这次实验中,我们照例使用孟老师提供的menu_OS作为我们的试验环境。
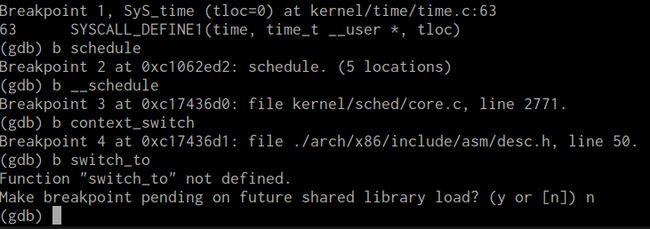
先将断点加在sys_time,进入系统后添加断点schedule,__schedule,context_switch,注意switch_to不是函数。
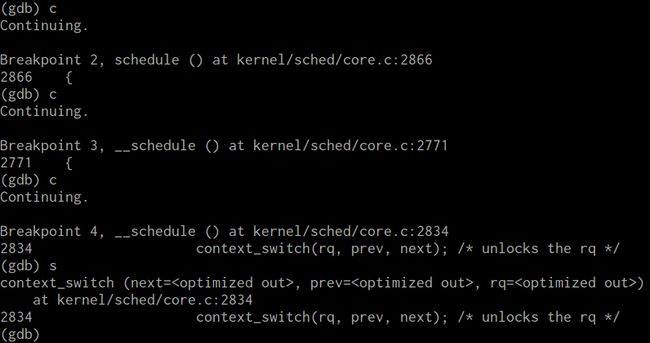
我们看到前几个函数断点都顺利进入了。

调试的时候发现,schedule是比较难调试的,因为kernel启动运行过程中,不断地会有进程切换,而且switch_to只是一个宏,并不是函数,所以无法加断点。而且好像无法进入context_switch,step一直进不去,也许对调度的分析还不够深入,接下来可以再考虑考虑这个问题。