Alexnet论文笔记
文章目录
- 前言
- 论文介绍
- 主要贡献
- 网络结构
- 细节方法
- ReLU
- 用 GPU 训练
- 局部响应归一化(LRN: Local Response Normalization)
- 重叠池化
- 数据增强(Data Augmentation)
- Dropout
- 其他训练细节
- 实验结果
前言
没有多少看论文的经验,也知道论文笔记非常重要。但是对于如何看和如何记录没有特别清晰的认识和了解,网上也找了很多相关的资料,但从看论文的思路到论文笔记的结构都因人而异各不相同。这是我第一篇论文笔记,方便查询和供各位参阅和探讨,里面也包括了笔者对论文的一些个人意见。虽然各路说法不一,还是先尝试再慢慢形成自己的套路,这是开端,是探索,笔者本着学习的态度完成这篇笔记,望一同学习和进步。
论文介绍
AlexNet就是由Hinton和他的两位学生发表的,该模型取得了ILSVRC2012冠军,并在这之后掀起CNN研究的热潮。
AlexNet 一开始在 ILSVARC-2010 数据集(带标签)上训练,在 top-1 和 top-5 错误率分别取得 37.5% 和 17.0% 的成绩,比以往的所有成绩都高。该网络使用了 60 million 参数和 650000 个神经元。模型使用非饱和神经元(ReLU)和应用GPU来加速训练,在全连接层使用 dropout 方法来减轻过拟合。该模型在 ILSVAC-2012 (没有标签)比赛中取得第一名的成绩, 15.3% 的 top-5 成绩比第二名的 26.2% 要好得多,也因此让深度学习开始被广泛关注。
主要贡献
- 构建由 5 层卷积层和 3 层全连接层组成的深度网络模型并在 ILSVARC-2012 取得第一;
- 使用 GPU 进行二维卷积;
- 使用了 ReLU线性神经元,进行并行的GPU计算,使用LRN(局部响应归一化)以及重叠的池化等方法来提高网络性能和缩小训练时间;
- 使用 Data Augmentation 和 Dropout 等方法来组织过拟合。
网络结构
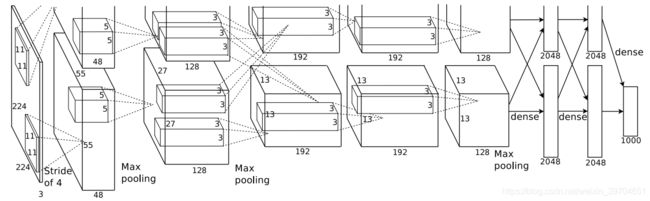
原文图如上,使用了两个GPU进行训练,Ng将此网络介绍如下:

网络输入图像为 224 X 224 X 3 。网络顺序如下:
input -> Conv1 (LRN) -> Pool1 -> Conv2 (LRN) -> Pool2 -> Conv3 -> Conv4 -> Conv5 -> Pool5 -> Fc6 (dropout) -> Fc6 (dropout) -> Fc7 (dropout) -> Fc8 -> 输出 1000 类
其中 ReLU 在每个 Conv 和 Fc 的后面都设置有。
网络细节可以参考附录。
细节方法
ReLU
公式: f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
实验证明使用4层卷积网络,使用 ReLUs 达到 25% 训练误差的速度要比相同情况下使用 tanh 要快 6 倍。ReLU 加速了网络的训练。
笔者补充:
加速的原因可能因为ReLU的线性,x>0 时梯度不衰减,缓解了梯度消失的问题,加速网络收敛。
另外,ReLU简单容易计算也是其另一个优点。
ReLU也要不好的地方,x<0 出现硬饱和,神经元输出变为0,梯度自然而然为0,使得 ReLU神经元难以再更新,这也是“ReLU神经元死亡”问题,也叫“Dead ReLU Problem”,当然,有人说永久失活,私以为死亡的ReLU神经元可能通过其他同层的未死亡的神经元对梯度的反向传播来更新 W,更新的 W 重新让已死亡的 ReLU 神经元激活。所以说永久失活应该是个概率问题,即大概率或者说长时间情况下死亡的 ReLU 神经元都会保持其“死亡”的状态。
ReLU的输出不是0均值分布的,这可能会有一定的影响。
用 GPU 训练
由于当时 GTX580 GPU 3GB显存的限制,作者使用两个 GPU 来进行并行训练。
局部响应归一化(LRN: Local Response Normalization)
公式如下图所示
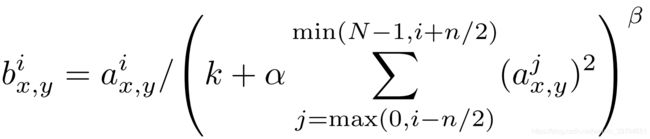
其中 b x , y i b_{x,y}^i bx,yi 表示第 i 个通道上位置为 (x,y) 的值。其中 N 表示通道数,n 为设定的维度之间的关联范围。 n , k , α , β n,k,\alpha,\beta n,k,α,β 均为自定义的,文章中设定 k = 2 , n = 5 , α = 1 0 − 4 , β = 0.75 k=2,n=5,\alpha=10^{-4},\beta=0.75 k=2,n=5,α=10−4,β=0.75。累加的方向为维度(通道)方向。总结一下,LRN就是将某一元素与相邻通道相同位置的其他元素相互抑制,公式里体现在除法上。
作者将该层放在 ReLU 之后,使得 top-1 和 top-5 错误率分别下降 1.4% 和 1.2%。
笔者补充: LRN 参考了神经生物的“侧抑制”。其指被激活的神经元抑制相邻神经元。归一化的目的就是“抑制”,而LRN 就是借鉴侧抑制的思想来实现局部抑制的,据说在用 ReLU 时侧抑制很管用,不过还没有一些证明,后期读到相关论文再来补充。
参考: https://blog.csdn.net/hduxiejun/article/details/70570086
重叠池化
作者使用大小为3,步长为2的池化方法。和大小为2步长为2的方法比,这个方法在 top-1 和 top-5 分别减少 0.4% 和 0.3% 的错误率,同时作者发现这个方法可以阻止过拟合。
数据增强(Data Augmentation)
两种扩充数据的方法。
- 其一,由于 ImageNet 数据集的图片大小为 256 X 256,作者需要进行裁剪到变长为 224 的图片。作者先遍历原图进行裁剪,再将原图进行水平翻转再进行裁剪,可以获得 ( ( 256 − 224 ) + 1 ) 2 × 2 = 33 × 33 × 2 = 2178 ((256-224) + 1)^2 \times 2 = 33 \times 33 \times 2=2178 ((256−224)+1)2×2=33×33×2=2178 倍的数据集。论文里说是2048,公式里没有加1,可能是漏了。预测的时候,对图片进行五次裁剪(四个角和中心位置),并对5次的softmax输出平均获得结果。
- 其二,fancy PCA 方法,另一种扩充数据的方法。论文没说这个称呼,但是网上都称其为 fancy PCA。首先对 RGB 三个通道计算PCA矩阵,在对于每个RGB图像 I x y = [ I x y R , I x y G , I x y B ] T I_xy = [I_{xy}^R, I_{xy}^G, I_{xy}^B]^T Ixy=[IxyR,IxyG,IxyB]T,增加如下项目: [ P 1 , P 2 , P 3 ] ⋅ [ α 1 λ 1 , α 2 λ 2 , α 3 λ 3 ] T [P_1,P_2,P_3] \centerdot [\alpha_1 \lambda_1,\alpha_2 \lambda_2,\alpha_3 \lambda_3]^T [P1,P2,P3]⋅[α1λ1,α2λ2,α3λ3]T。
其中 P i P_i Pi 和 λ i \lambda_i λi 分别是图像三个通道的协方差矩阵的的第 i i i 个特征向量和特征值,而 α i \alpha_i αi 是服从均值0标准差0.1的正太分布的随机量。论文中说这种方法可以近似捕捉自然图像的一个重要性质,即物体的同一性对于光照的强度和颜色的变化是不变的。该方法使得 Top1 错误率降低1%。
Dropout
该方法就是使得全连接层的神经元以 50% 的概率随机失活。作者认为更利于学习更加鲁棒且有用的特征。
笔者补充: Ng对dropout有如下解释
- 正是因为在每一层随机的丢弃了一些单元,所以相当于训练出来的网络要比正常的网络小的多,在一定程度上解释了避免过拟合的问题。
- 因为每一个特征都有可能被丢弃,所以整个网络不会偏向于某一个特征(把某特征的权重的值赋的很大),会把每一个特征的权重都赋的很小,这就有点类似于L2正则化了,能够起到减轻过拟合的作用。
其他训练细节
- batchsize = 128, momentum = 0.9, weight decay = 0.0005;
- 2,4,5卷积层和全连接层的偏置初始化为1,其他卷积层偏置初始化为0,权重初始化为均值为0标准差为0.01的高斯分布;
- 学习率初始化0.01,如果验证集的错误率不能改善就将学习率除以10,不过只进行3次这样的操作就终止学习;
- 两块NVIDIA GTX 580 3GB GPU 训练了 90 个epoch,花费 5-6天。
实验结果
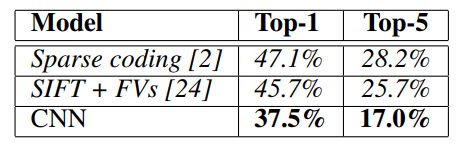
在 ILSVRC-2010 上结果比当时的 best performance 要好很多,错误率如下图:
在 ILSVRC-2012 结果如下图:
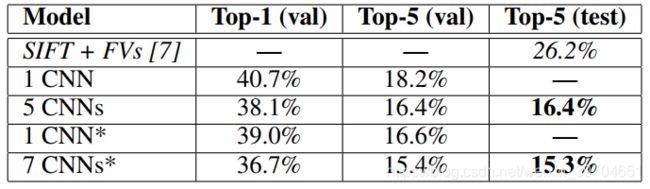
其中,论文的模型在top-5中达到 18.2% 错误率。作者做了其他工作。使用5个类似结构的CNN预测并对结果取平均,获得 16.4% 的结果;在CNN模型的最后一个池化层中添加第六个卷积层,事先训练过整个 ImageNet 2011秋 的数据集,并在 ILSVRC-2012 上进行微调获得 16.6% 的结果,将事先训练的两个CNN与前面说的 5 CNNs 模型的预测值取平均获得 15.3% 的结果。
另外,作者还对 ImageNet 2009 数据集进行训练,将其按训练集测试集对半分。模型采用论文中的模型再加上第六个卷积层,在 top-1 和 top-5 上分别获得 67.4% 和 40.9% 的错误率结果,也比当时最好的结果要好。
附录: