根据官网文档看Spark Streaming对接Kafka的两种方式, 以及如何实现"Exactly Once"语义
注: 本文算是本人的学习记录, 中间可能有些知识点并不成熟, 不能保证正确性. 只能算是对官网文档作了个翻译和解读, 随时有可能回来更新和纠错
上一篇文章讨论了Spark Streaming的WAL(Write Ahead Log)机制, 最后给出了三个流处理的语义:

不仅是在Spark Streaming, 在其他的实时处理框架下, 这也还是需要面对的问题
先简单理解一下这三个语义:
- At most once: 每个记录最多被处理一次. 说直白一点, 应该是类似于"只管发送, 不管接收"这么个意思
- At least once: 每个记录至少被处理一次. 并且官网的描述说: 这肯定比"At most once"要好, 因为它保证了数据不会丢. 但是呢, 它可能会导致数据重复处理
- Exactly once: 每个记录就是准确地只处理一次, 不多不少, 不丢数据也不会重复处理. 官网也说了, 这很明显是最好的. 不过呢, 事情总有两面性的, 它既然在功能上完胜前两者, 那么肯定不会这么容易就实现的
上一篇文章也说了, WAL可以保证"At least once"语义. 在Spark Streaming对接Kafka的时候, 就有用到这个WAL机制的地方, 就是Receiver方式
(贴一下官网上的具体地址, 官网的布局找起来是真的有点绕…可能是因为全是英文, 不太习惯)http://spark.apache.org/docs/latest/streaming-kafka-0-8-integration.html#approach-2-direct-approach-no-receivers

简要翻译一下:
- 第一段说: Receiver是Kafka consumer的高级API(略). 在这种情况下, Kafka过来的数据是通过一个receiver存储在每个Spark的Executor上的
- 第二段说: 默认的配置下, 会出现数据丢失. 不过问题不大, 可以通过开启WAL机制来保证数据零丢失. 它会同步地将Kafka过来地数据用WAL保存到分布式文件系统(如HDFS, 保障完整性, 上一篇文章也有提到过一句)
重点: Receiver模式默认不开启WAL, 开启了只能保证数据不丢失, 即"At least once"
(跳过部署代码. 使用Receiver模式的话, 在API中是KafkaUtils.createStream()这个方法, 后面有时间的话单独写一篇分析一下源码)
接着往下看:

继续翻译:
- 第一段: 这种模式下, Kafka的partition数量跟Spark并没有什么相互依赖的关系, 通过参数可以提高Kafka的topic中的partition数量, 但这会提高单个receiver消费这个topic时的线程数, 这并不会提高Spark处理数据的并行度
这里好像有点复杂, 主要是有几个小知识点:- 无论是Kafka的partition, 还是Spark的partition, 都是提高并行度->加快运行/处理速度的设计
- Spark的一个partition会对应一个小的Task, 而一个Task对应一个线程, 线程对应的是Core的数量(即CPU中的核数). 而Spark对接Kafka的时候, 数据是要给到executor上的, executor的Core和Memory在Spark-submit的时候可以指定
- 线程并不是越多越好. 理论上来说, 比如CPU有N个Core, 那么N个线程是最大化的处理速度. 举个通俗的例子来说, 单核CPU的话就是单线程最快, 而不是多线程最快. 在单核CPU上进行多线程运行, 只会使性能下降, 因为会引起很多的CPU上下文切换, 而单核CPU+单线程就不会, N核CPU+N个线程也不会
- 第二段: Kafka的DStream可能由不同的group(Kafka的consumer group是指代多个consumer组成的集合. 在这个场景下, consumer指的就是executor上的receiver)和topic创建, 可以用大量的receiver来提高接收数据的并行度
分开来看, 先看逗号前的半句. DStream吧, 用一张图就可以概括:

接着, 说到Kafka的consumer group, 注意它有这么几个特点:
1) 同一个consumer group可以并发消费多个partition的消息
2) 同一个partition也可以由多个consumer group并发消费
3) 但是在同一个consumer group中, 每个partition只能由其中一个consumer消费
这三句话有点绕, 我也没想好很简单的表述, 尽量理解一下吧. 因为这样一来, 后半句话也很好理解了:
0) 最重要的: "增加receiver的数量"跟"增加每个receiver上的线程数量(即文档中第二段的说法)"不是一个概念!!!
1) 增加receiver的数量, 就可以直接提高partition处理的并行度, 也就会提高Kafka对数据的处理速度 - 第三段: 如果用了WAL且写入像HDFS这样的文件系统, 收到的数据还是会被多份备份在日志中(简单地说, 一定程度上加大了存储负担, 因为每份数据都要多份存储啊). 然后, 可以设置一个存储级别: StorageLevel.MEMORY_AND_DISK_SER
这里有个词MEMORY_AND_DISK_SER:
1) MEMORY_AND_DISK指的是内存和磁盘共同存储. 优先在内存存储(为的是速度, 保证实时性), 不够的时候再存储到磁盘. 内存当然指的是executor的内存了, 记不记得Spark-submit的时候指定了executor的Core数量, 也指定了内存大小memory?
2) SER指的是序列化. 序列化就是一种转换操作, 常用于数据存储和数据传输, 代价就是会增加CPU消耗. 所以照理说, 要综合CPU性能和存储空间两者一起考虑决定
此外, Kafka消费是要通过offset来进行的, Spark Streaming在这个Receiver模式下, offset是怎么管理的呢?

(这个文档不一定精确, 但我看这个是最接近的了)
大概是说, Kafka自身就可以周期性地自动提交offset, 但我们也可以自己手动提交
在Receiver模式下是自动提交的, 那么提交去哪儿呢?
我从别处盗了一张图来(因为还是没在官网上找到精确的文档和图, 这个网站属实有点陌生…)
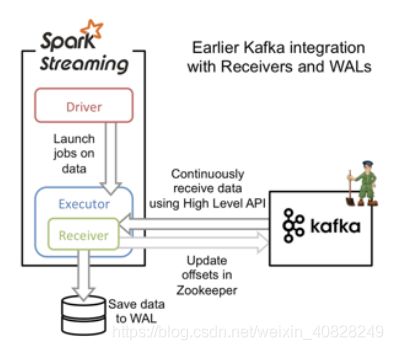
也就是说, 可以把offset提交到Zookeeper上. 结合上面说的, 那就是Receiver模式下, Receiver会定期向Zookeeper更新offset
不过呢, 总要假设不靠谱的情况的. 如果WAL(注意是write ahead的, 肯定在所有动作之前)先保存了数据, 然后数据也消费好了, 但是最后更新消费的offset时, 即offset发送到Zookeeper的时候, 发送失败了呢? 好吧, 不过问题不大, 就从上一次保存的offset再重新消费一次就行了
所以, Receiver并不能保证"Exactly once", 只能保证"At least once"!
好了, 终于把Receiver模式讲完了. 不过呢, 很不幸, 它已经是过时的了… 新的Kafka版本下, 不支持Receiver模式了(应该没理解错吧?)
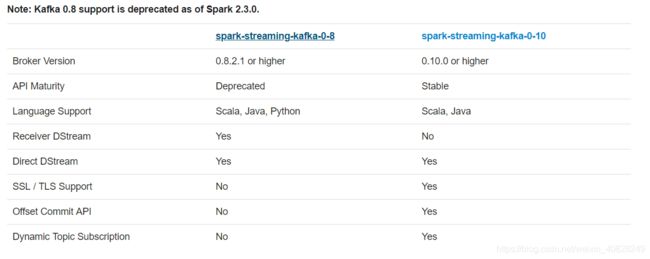
好吧, 但是按照常理, Yes的肯定有些地方比No的好. 那么来看看这另一种模式, Direct模式
先趁热打铁, 对比一下offset管理的过程(这图仍然是盗的, 官网上我是真找不到, 很无语…)
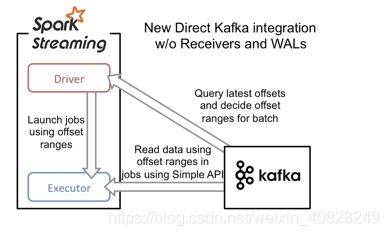
乍一看, Zookeeper那个铲子哥呢? 还有, Receiver呢? WAL呢?
ok, 怀着问题去学习, 挺好的
先看网页顶部这一段介绍

划重点: Kafka的partition和Spark的partition是1:1的. 什么意思? 上面已经解释过了, 就不用说了吧
简而言之, 数据partition的处理并行度可以有效地控制和提高了! 而不是干巴巴地通过增加线程来提高单个partition的处理速度!
接着看正文, 继续翻译

- 第一大段: 这是一种没有receiver的"direct"模式, 更强大的点对点保障(指的Kafka到Spark). 它周期性地去找Kafka要最新的offset, 每个topic中的每个partition都要, 根据offset的范围来处理每个批次. 当处理(Kafka)数据的(Spark)job连接, Kafka的低级API(应该是跟Receiver的高级API对应, 略, 暂时不知道低级高级是什么意思)将会去Kafka上读取定义好的offset范围, 就像从文件系统读文件一样. 其他就是说一下版本, 知道就行
几个重点:- 从Kafka取offset(看来offset的管理确实没用到Zookeeper了)
- offset有范围, 按批读取(executor的进程根据offset range去读取该批次对应的消息即可, 一段offset在Kafka中能唯一确定一条消息的, 这个很好理解). 那么结合之前"Kafka和Spark的partiton 1:1", 是不是好像能有所联系?
我的理解是这样: 在Receiver模式中, Spark的partition和Kafka中的partition并不是相关的, 所以如果增加Kafka每个topic的partition数量, 也仅仅是为receiver增加了处理消费对应topic的线程(此时数据已经到达executor了), 并没有增加Spark在处理数据上的并行度
说白了, 单个Task的计算速度也许加快了, 可是Task的并行度很差. 即便加快了单个Task的执行速度, 可能也跑不过并行计算(这个道理很容易想明白, 像MapReduce这样的分布式计算框架, 本身就是单机的计算力不足的背景下所产生的. 既然不能直接扩展计算力了, 那就提高并行度, 也就是加机器来解决)
那么就要说到Direct模式了, 它确实是Kafka的partition和Spark的partition一一对应. 这样的话, Spark Streaming对接Kafka的性能问题就全部交给了"partition数量(Task数量) = executor数量 * Core数量"这样一个公式(个人理解). 而executor数量和每个executor的Core数量都是可以设置的, 问题就简化了
且相比Receiver模式来说, 使用Direct模式的Spark集群是不是有了更好的可扩展性? 我觉得这是非常直观的对比了
此外, 我看到另外一个说法"Spark Streaming会周期性的获取Kafka中每个Topic的每个partition中的最新offsets, 即通过Kafka API读取Topic中每个partition最后一次读的offset, Spark的partition与之一一对应并根据这个offset与上一次的offset构成的范围进行读". 我觉得是比较有道理的, 但是官网上没有找到对应的描述, 还暂时存疑 - 提到了"批次", 那么有一个概念强调一下: Spark Streaming并不是"真真正正的实时流处理", 它是一个"时间间隔很短的微小批处理", 而不是"来一条数据就直接处理掉". 放一张官网的图:

- 第二大段:
- 简化的并行度. 使用KafkaUtils.directStream()这个API, Spark Streaming就会创建和Kafka partition一样多的RDD partition
- 效率. 在Receiver模式下想要实现零数据丢失的话, 需要先来一个WAL, 而且它还要备份(如果是HDFS的话, 我猜是得等HDFS备份好了才算成功写入WAL). 数据在Kafka还需要备份(Leader复制两份给Follower), 然后还要WAL一次. 相比之下, Direct模式没有receiver, 也就不需要WAL. 然后, 数据备份工作由Kafka来, 可以保障数据恢复(但可没说数据消费零丢失哦)
简而言之, 把WAL这个操作省去了(其实在这一段这么看来, 这个"需要进行备份"的"ahead"操作似乎是有点多余, 新版本的Kafka对它进行了No, 确实是挺有依据的, 好像确实没有必要等它完成, 太影响性能了) - Exactly once语义.前面几行"批判"了一下Receiver模式可能存在的多次消费问题, 然后追根溯源, 找到了这个的原因: offset最后更新到Zookeeper的时候可能发生意外. 所以, 在这个Direct模式下, 用的是低级的Kafka API, 不用Zookeeper了(这样看起来, 把offset交给Kafka管理真的是有道理的! 然后, 高级低级API的区别可能是能不能操作外部组件吧), offset将在checkpoint被保存(暂不讨论checkpoint). 这消除了Spark Streaming和Zookeeper/Kafka之间的不一致性(应该指的是保存的offset和实际消费到的offset保持一致), 即使出现意外情况, 也可以保证数据消费的Exactly once. 但是, 需要做额外的工作来保障这个Exactly once(前面说了吧, 不会那么容易实现的…). 给了两种方式, 一个是idempotent, 幂等; 一个是atomic transaction, 原子性的事务, 它们需要在程序中实现, 以正确保存result和offset
总的来说, Spark Streaming对接Kafka管理offset有两种方式:
- 通过checkpoint机制向HDFS存储metadata, 来实现offset的管理
- 通过代码逻辑对offset进行读取和提交
接着看, 附了一个蓝色链接提示我们去看, 先不急. 不如先思考一下, 为什么要用幂等和事务来处理呢? 如果不照做, 会怎么样呢? 真的就不能了吗?
既然说了是要在程序中实现, 那么代码一定有先后顺序对吧? 假设是这样的代码顺序:
("消费数据并保存result"一般来说就是业务逻辑, 可能长可能短, 但是是有可能崩的)

5. 最好的情况: 什么问题也不出, 正常执行. 这时候, 无论是先保存result, 还是先保存offset, 都没有关系
此时就是"Exactly once"语义, 但是并不是每次都能好运的, 要设计容错方案
6. 不太好的情况: 出问题了, 但是还好, 是result保存了, offset没保存. 即上面的程序执行了一半

这个时候呢, 是"At least once"语义, 即数据是不会少消费的, 但是不防止重复消费
7. 最不好的情况: 出问题了, 而且代码里是保存offset在先, 消费数据和保存result在后, 且程序又是执行到一半崩了

我觉得这应该就是"At most once"语义了…
所以, 从"两害相权取其轻"这个思想来说, 好像是应该先读取数据, 再保存offset? 不过我也只是初学不久, 没有实践过, 只是逻辑上的推导, 就不妄加推测了
那能不能出错的情况下实现"Exactly once"呢? 不然的话和之前的也没什么区别啊, 反正都要祈祷它不出错
那么现在应该点进去刚才那个蓝色链接了, 可以看到官网对这两个方式做了详细些的介绍:

坚持我们的主题, 根据官网文档学习
也就是继续翻译:
- 第一大段: 输出操作是有"At least once"语义的(应该说的是先保存result, 后保存offset的那种代码), 在一个worker(Spark的工作节点)挂掉的时候, 数据可能被重复消费. 写入的文件系统有可能不允许写入相同数据(以我的理解来说, 比如说MySQL的主键冲突), 总之需要额外的操作来达到"Exactly once"语义
- 第一大段之后, 开始介绍这两个了
- 幂等性的更新. 多次的尝试也只会写入相同的数据
幂等是数学的概念, 说的是f(x) = f(f(x)), 那也就是无论计算几次, 结果都一样
从逻辑上讲, At least once + 幂等 = Exactly once, 借助上面那个幂等小公式应该也可以理解
具体的话, 我推荐这篇文章(因为我不懂): https://cloud.tencent.com/developer/article/1430049 - 事务性的更新. 保证"update"操作的原子性(拿上面的例子来说, 保存result和保存offset这两个操作必须同时执行. 要么同时成功, 要么同时失败, 不能分割开来执行!)
简单回顾一下事务的原子性. 贴一下百度百科对"事务的原子性"的解释:

插一句, 为什么叫"原子性"呢? 原子的其他三种性质(一致性/隔离性/持久性)其实按字面意思都很好理解, 就原子性有点抽象. 那就还是贴一下百度百科对"原子"的解释(我觉得原子性借助的是化学的原子概念, 究竟是什么那就不钻牛角尖了):

顺便举个常见的事务例子, 银行转账, 张三转账500给李四, 也就是张三-500, 李四+500对吧, 那肯定不能张三-500, 李四没有+500啊, 出多大的故障都不能, 不然就出事了
当然, 事务中处理错误也很简单, 回滚即可, 只要不提交都不算数. 以一段超简单的java操作JDBC代码为例:

回到官网的文档上来, 其实也差不多了(主要是因为我不太懂具体怎么做…)
i) 根据批处理的时间和partition在RDD中的序号, 创建一个identifier, 在Streaming Application中进行唯一区分
说实话, 这个我没怎么看懂, 还需要点水平
ii) 我觉得这里的思想是一个"upsert"的思想. 也就是说, 保存result的时候(因为说了是update external system, 那就肯定不是保存offset了), 先判断有没有这样的数据已经存在/提交过(比如说数据库的唯一主键), 没有的话就commit, 有就skip(跳过)
- 幂等性的更新. 多次的尝试也只会写入相同的数据
现在再看一下Spark Streaming以Direct模式对接Kafka的offset管理这幅图, 是不是就很好理解这个过程了呢?
然后再对比一下Receiver模式下的offset管理吧:
这样一趟, 我们根据官方文档, 把Spark Streaming对接Kafka的两种方式, 以及三种语义的实现(最重要的是Exactly once), 都学习了一遍. 有一说一, 我觉得很多知识点, 知道了一些核心设计和底层知识之后(比如partition的并行, CPU的核数与线程数的关系), 很多逻辑都能直接想到的. 我在写这篇文章的时候, 好几次根据前面的情况, 直接就猜想了一下它是怎么解决的, 然后看后面的文档, 果真如此
总而言之, 我觉得学大数据属实没有那么轻松, 知识面还是非常广的. 不仅有很多新的陌生的组件, 而且有好几门计算机基础课程的掌握和逻辑发散, 还是有很多很多地方需要学习的